Description: Collaborative filtering prone to popularity bias, resulting in overrepresentation of popular items in the recommendation outputs.
Entities
View all entitiesAlleged: Facebook , LinkedIn , YouTube , Twitter and Netflix developed and deployed an AI system, which harmed Facebook users , LinkedIn users , YouTube users , Netflix users and X (Twitter) users.
Risk Subdomain
A further 23 subdomains create an accessible and understandable classification of hazards and harms associated with AI
1.3. Unequal performance across groups
Risk Domain
The Domain Taxonomy of AI Risks classifies risks into seven AI risk domains: (1) Discrimination & toxicity, (2) Privacy & security, (3) Misinformation, (4) Malicious actors & misuse, (5) Human-computer interaction, (6) Socioeconomic & environmental harms, and (7) AI system safety, failures & limitations.
- Discrimination and Toxicity
Entity
Which, if any, entity is presented as the main cause of the risk
AI
Timing
The stage in the AI lifecycle at which the risk is presented as occurring
Post-deployment
Intent
Whether the risk is presented as occurring as an expected or unexpected outcome from pursuing a goal
Unintentional
Incident Reports
Reports Timeline


Loading...
Introduction
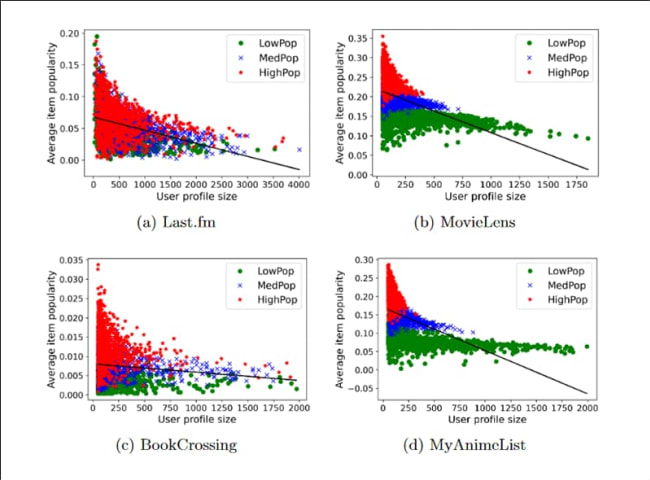
Collaborative filtering (CF) is one of the most traditional but also most powerful concepts for calculating personalized recommendations [22] and is vastly used in the field of multimedia recommender systems (MMRS) [11]. Howeve…
Loading...

If you’re interested in obscure things, there are two reasons why your searches for items and products are likely to be less related to your interests than those of your ‘mainstream’ peers; either you’re a monetization ‘edge case’ whose int…
Variants
A "variant" is an AI incident similar to a known case—it has the same causes, harms, and AI system. Instead of listing it separately, we group it under the first reported incident. Unlike other incidents, variants do not need to have been reported outside the AIID. Learn more from the research paper.
Seen something similar?
Similar Incidents
Did our AI mess up? Flag the unrelated incidents



Similar Incidents
Did our AI mess up? Flag the unrelated incidents