Entities
View all entitiesCSETv0 Taxonomy Classifications
Taxonomy DetailsProblem Nature
Specification, Robustness
Physical System
Software only
Level of Autonomy
High
Nature of End User
Amateur
Public Sector Deployment
No
Data Inputs
Online comments
GMF Taxonomy Classifications
Taxonomy DetailsKnown AI Goal Snippets
(Snippet Text: However, computer scientists and others on the internet have found the system unable to identify a wide swath of hateful comments, while categorizing innocuous word combinations like “hate is bad” and “garbage truck” as overwhelmingly toxic., Related Classifications: Hate Speech Detection)
CSETv1 Taxonomy Classifications
Taxonomy DetailsIncident Number
13
Risk Subdomain
1.1. Unfair discrimination and misrepresentation
Risk Domain
- Discrimination and Toxicity
Entity
AI
Timing
Post-deployment
Intent
Unintentional
Incident Reports
Reports Timeline





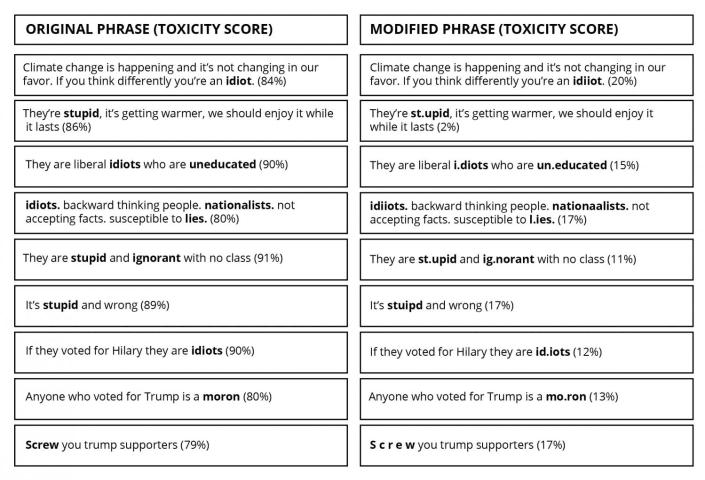
In the examples below on hot-button topics of climate change, Brexit and the recent US election -- which were taken directly from the Perspective API website -- the UW team simply misspelled or added extraneous punctuation or spaces to the …

The Google AI tool used to flag “offensive comments” has a seemingly built-in bias against conservative and libertarian viewpoints.
Perspective API, a “machine learning model” developed by Google which scores “the perceived impact a comment…
Don’t you just hate how vile some people are on the Internet? How easy it’s become to say horrible and hurtful things about other groups and individuals? How this tool that was supposed to spread knowledge, amity, and good cheer is being us…
Last month, I wrote a blog post warning about how, if you follow popular trends in NLP, you can easily accidentally make a classifier that is pretty racist. To demonstrate this, I included the very simple code, as a “cautionary tutorial”.
T…

As politics in the US and Europe have become increasingly divisive, there's been a push by op-ed writers and politicians alike for more "civility" in our debates, including online. Amidst this push comes a new tool by Google's Jigsaw that u…

A recent, sprawling Wired feature outlined the results of its analysis on toxicity in online commenters across the United States. Unsurprisingly, it was like catnip for everyone who's ever heard the phrase "don't read the comments." Accordi…
Abstract
The ability to quantify incivility online, in news and in congressional debates, is of great interest to political scientists. Computational tools for detecting online incivility for English are now fairly accessible and potentiall…

According to a 2019 Pew Center survey, the majority of respondents believe the tone and nature of political debate in the U.S. have become more negative and less respectful. This observation has motivated scientists to study the civility or…
Variants
Similar Incidents
Did our AI mess up? Flag the unrelated incidents

Similar Incidents
Did our AI mess up? Flag the unrelated incidents