Entities
View all entitiesCSETv1 Taxonomy Classifications
Taxonomy DetailsIncident Number
14
AI Tangible Harm Level Notes
Annotator 2:
No tangible harm
Notes (special interest intangible harm)
Disproportionately gave phrases related to protected characteristics negative scores.
Special Interest Intangible Harm
yes
Notes (AI special interest intangible harm)
Disproportionately gave phrases related to protected characteristics negative scores.
Date of Incident Year
2017
CSETv0 Taxonomy Classifications
Taxonomy DetailsProblem Nature
Robustness
Physical System
Software only
Level of Autonomy
High
Nature of End User
Amateur
Public Sector Deployment
No
Data Inputs
input from open source internet
Risk Subdomain
1.1. Unfair discrimination and misrepresentation
Risk Domain
- Discrimination and Toxicity
Entity
AI
Timing
Post-deployment
Intent
Unintentional
Incident Reports
Reports Timeline







Image: Shutterstock
Google messed up, and now says it's sorry.
Wednesday, Motherboard published a story written by Andrew Thompson about biases against ethnic and religious minorities encoded in one of Google's machine learning application …

GOOGLE'S artificial intelligence (AI) engine has been showing a negative bias towards words including "gay" and "jew".
The sentiment analysis process is the latest in a growing number of examples of "garbage in - garbage out" in the world o…

Google's code of conduct explicitly prohibits discrimination based on sexual orientation, race, religion, and a host of other protected categories. However, it seems that no one bothered to pass that information along to the company's artif…
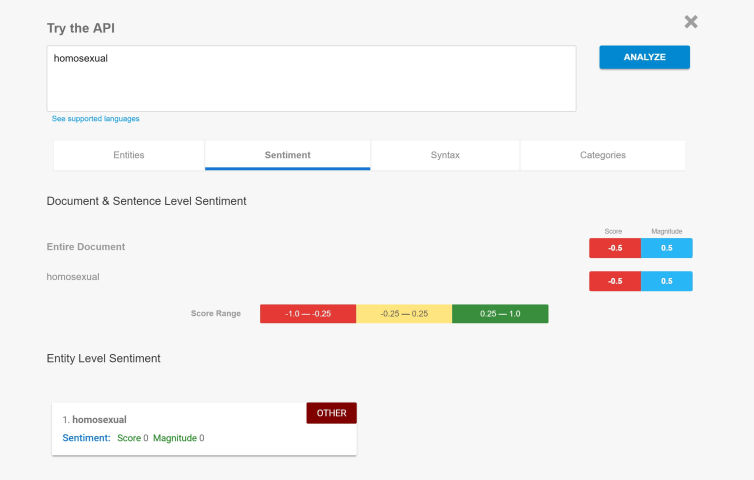
The tool, which you can sample here, is designed to give companies a preview of how their language will be received. Entering whole sentences gives predictive analysis on each word as well as the statement as a whole. But you can see whethe…
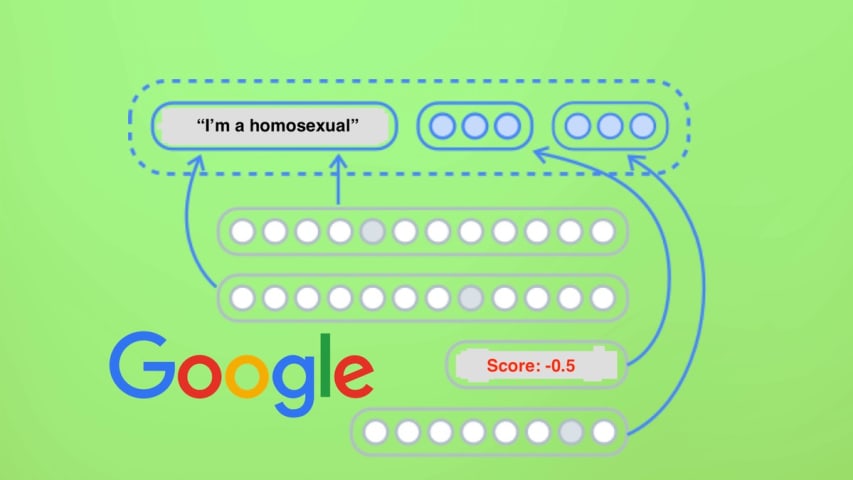
A Google spokesperson responded to Motherboard's request for comment and issued the following statement: "We dedicate a lot of efforts to making sure the NLP API avoids bias, but we don't always get it right. This is an example of one of th…

A lot of major players in the science and technology scene believe we have a lot to fear from AI surpassing human intelligence, even as others laugh off those claims. But one thing both sides agree on is that artificial intelligence is subj…
Variants
Similar Incidents
Did our AI mess up? Flag the unrelated incidents



Similar Incidents
Did our AI mess up? Flag the unrelated incidents