Description: AI tools failed to sufficiently predict COVID patients, some potentially harmful.
Entities
View all entitiesRisk Subdomain
A further 23 subdomains create an accessible and understandable classification of hazards and harms associated with AI
7.3. Lack of capability or robustness
Risk Domain
The Domain Taxonomy of AI Risks classifies risks into seven AI risk domains: (1) Discrimination & toxicity, (2) Privacy & security, (3) Misinformation, (4) Malicious actors & misuse, (5) Human-computer interaction, (6) Socioeconomic & environmental harms, and (7) AI system safety, failures & limitations.
- AI system safety, failures, and limitations
Entity
Which, if any, entity is presented as the main cause of the risk
Human
Timing
The stage in the AI lifecycle at which the risk is presented as occurring
Post-deployment
Intent
Whether the risk is presented as occurring as an expected or unexpected outcome from pursuing a goal
Unintentional
Incident Reports
Reports Timeline

Loading...
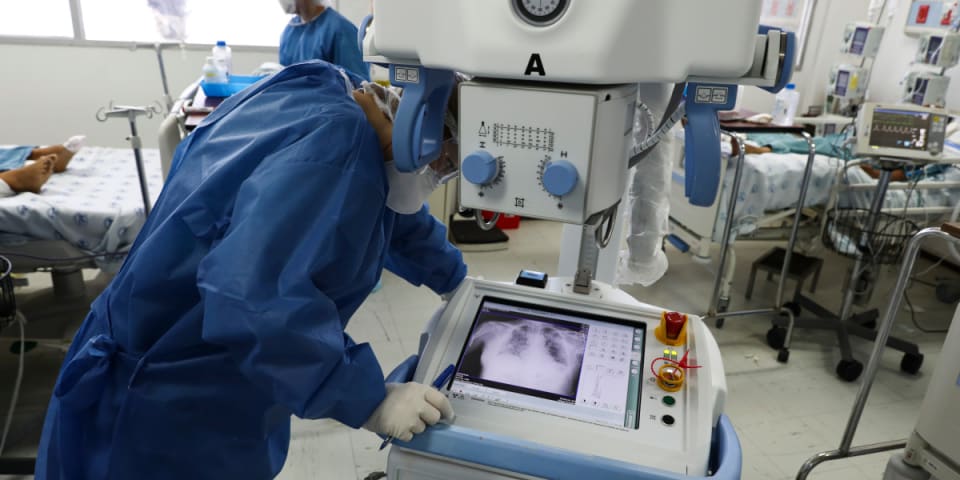
When covid-19 struck Europe in March 2020, hospitals were plunged into a health crisis that was still badly understood. “Doctors really didn’t have a clue how to manage these patients,” says Laure Wynants, an epidemiologist at Maastricht Un…
Variants
A "variant" is an AI incident similar to a known case—it has the same causes, harms, and AI system. Instead of listing it separately, we group it under the first reported incident. Unlike other incidents, variants do not need to have been reported outside the AIID. Learn more from the research paper.
Seen something similar?
Similar Incidents
Did our AI mess up? Flag the unrelated incidents


Similar Incidents
Did our AI mess up? Flag the unrelated incidents