Entities
View all entitiesCSETv1 Taxonomy Classifications
Taxonomy DetailsIncident Number
54
CSETv0 Taxonomy Classifications
Taxonomy DetailsProblem Nature
Robustness
Physical System
Software only
Level of Autonomy
Unclear/unknown
Nature of End User
Expert
Public Sector Deployment
Yes
Data Inputs
Crime statistics
Risk Subdomain
1.1. Unfair discrimination and misrepresentation
Risk Domain
- Discrimination and Toxicity
Entity
AI
Timing
Post-deployment
Intent
Unintentional
Incident Reports
Reports Timeline















Faiza Patel is the co-director of the Liberty and National Security Program at the Brennan Center for Justice at New York University Law School. She is on Twitter.
In every age, police forces gain access to new tools that may advance their …
Just over a year after Michael Brown’s death became a focal point for a national debate about policing and race, Ferguson and nearby St. Louis suburbs have returned to what looks, from the outside, like a kind of normalcy. Near the Canfield…

A police officer stands at the corner of a busy intersection, scanning the crowd with her body camera. The feed is live-streamed into the Real Time Crime Center at department headquarters, where specialized software uses biometric recogniti…
This is Episode 12 of Real Future, Fusion’s documentary series about technology and society. More episodes available at realfuture.tv.
There's a new kind of software that claims to help law enforcement agencies reduce crime, by using algori…

ON A SPRING AFTERNOON IN 2014, Brisha Borden was running late to pick up her god-sister from school when she spotted an unlocked kid’s blue Huffy bicycle and a silver Razor scooter. Borden and a friend grabbed the bike and scooter and tried…

“Predictive policing” is happening now — and police could learn a lesson from Minority Report.
David Robinson Blocked Unblock Follow Following Aug 31, 2016
In the movie Minority Report, mutants in a vat look into the future, and tell Tom Cr…
In late 2013, Robert McDaniel – a 22-year-old black man who lives on the South Side of Chicago – received an unannounced visit by a Chicago Police Department commander to warn him not to commit any further crimes. The visit took McDaniel by…
Natalie Behring/Getty
Algorithms have taken hold over our lives whether we appreciate it or not.
When Facebook delivers us clickbait and conspiracy theories, it's an algorithm deciding what you're interested in.
When Uber ratchets up rush-h…

During an October shift, Los Angeles police Sgt. Charles Coleman of the Foothill Division speaks with Clarance Dolberry, wearing baseball cap, and Veronica De Leon, donning a Mardi Gras mask, at a bus stop. Software that predicts possible f…

From Los Angeles to New York, there is a quiet revolution underway within police departments across the country.
Just as major tech companies and political campaigns have leveraged data to target potential customers or voters, police depart…

Image: Gina Ferazzi/Getty
Tim Birch was six months into his new job as head of research and planning for the Oakland Police Department when he walked into his office and found a piece of easel pad paper tacked onto his wall. Scribbled acros…

The problem of policing has always been that it's after-the-fact. If law enforcement officers could be at the right place at the right time, crime could be prevented, lives could be saved, and society would surely be safer. In recent years,…

The Truth About Predictive Policing and Race
Sunday, the New York Times published a well-meaning op-ed about the fears of racial bias in artificial intelligence and predictive policing systems. The author, Bärí A. Williams, should be commen…

IN THE DECADE after the 9/11 attacks, the New York City Police Department moved to put millions of New Yorkers under constant watch. Warning of terrorism threats, the department created a plan to carpet Manhattan’s downtown streets with tho…

Introduction
The expansion of digital record-keeping by police departments across the U.S. in the 1990s ushered in the era of data-driven policing. Huge metropolises like New York City crunched reams of crime and arrest data to find and tar…

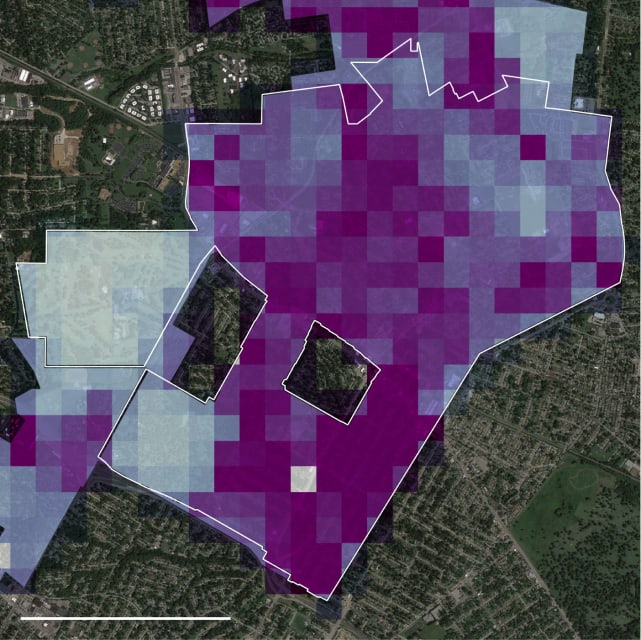
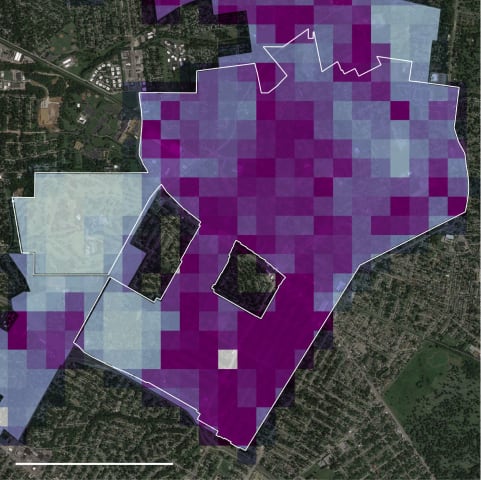
Between 2018 and 2021, more than one in 33 U.S. residents were potentially subject to police patrol decisions directed by crime-prediction software called PredPol.
The company that makes it sent more than 5.9 million of these crime predicti…
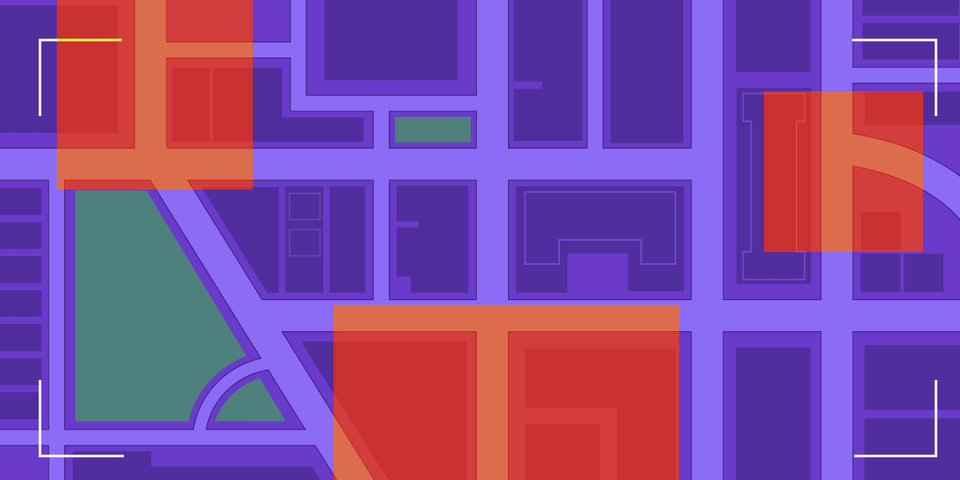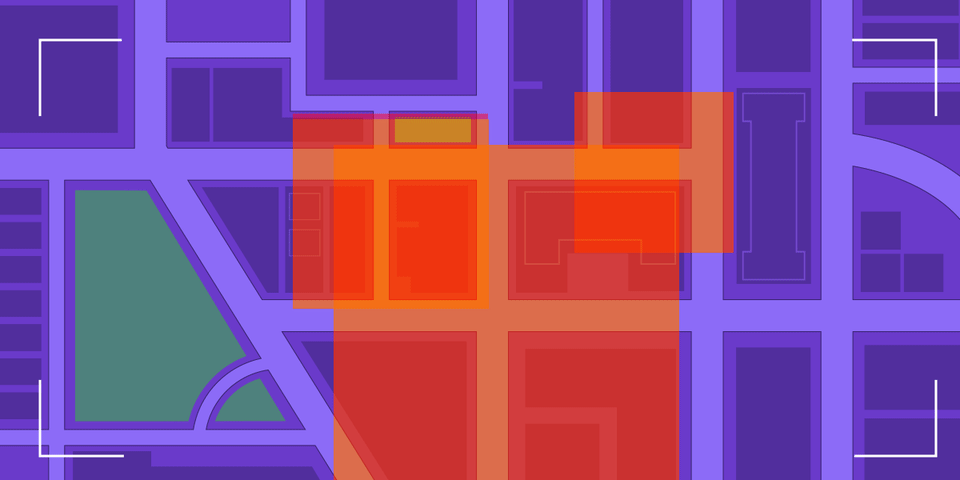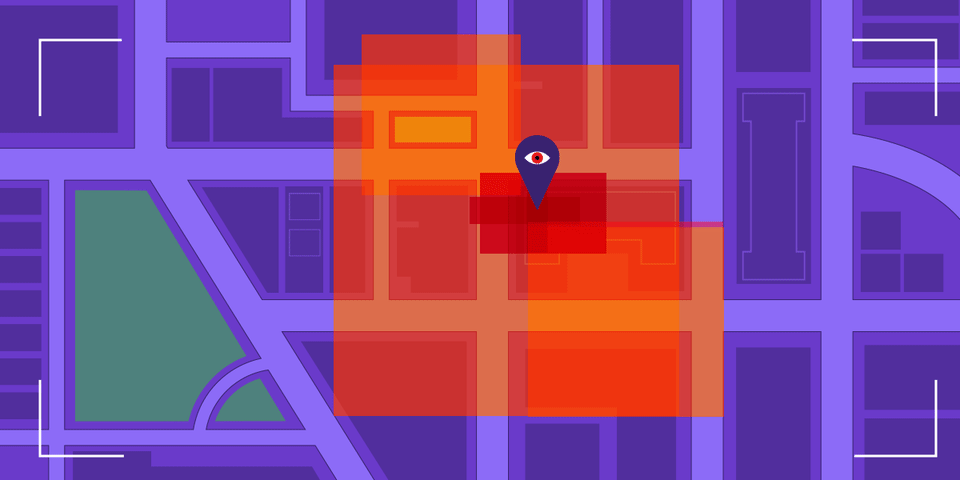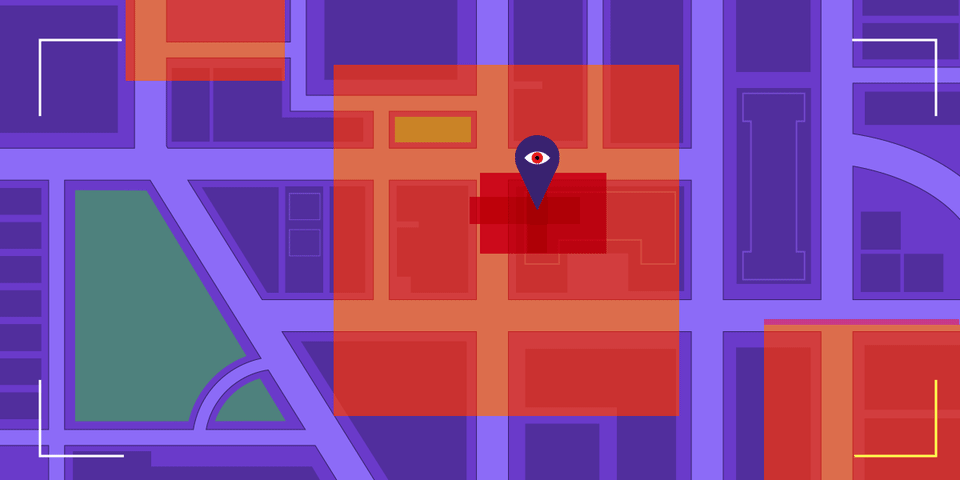
Decades ago, when imagining the practical uses of artificial intelligence, science fiction writers imagined autonomous digital minds that could serve humanity. Sure, sometimes a HAL 9000 or WOPR would subvert expectations and go rogue, but …
Variants
Similar Incidents
Did our AI mess up? Flag the unrelated incidents


Similar Incidents
Did our AI mess up? Flag the unrelated incidents