Description: A book title by Korea’s first minister of culture was mistranslated into an offensive phrase by Google Lens’s camera-based translation feature allegedly due to its training on internet communications and a lack of context.
Entities
View all entitiesAlleged: Google developed and deployed an AI system, which harmed Google Lens users.
Risk Subdomain
A further 23 subdomains create an accessible and understandable classification of hazards and harms associated with AI
1.2. Exposure to toxic content
Risk Domain
The Domain Taxonomy of AI Risks classifies risks into seven AI risk domains: (1) Discrimination & toxicity, (2) Privacy & security, (3) Misinformation, (4) Malicious actors & misuse, (5) Human-computer interaction, (6) Socioeconomic & environmental harms, and (7) AI system safety, failures & limitations.
- Discrimination and Toxicity
Entity
Which, if any, entity is presented as the main cause of the risk
AI
Timing
The stage in the AI lifecycle at which the risk is presented as occurring
Post-deployment
Intent
Whether the risk is presented as occurring as an expected or unexpected outcome from pursuing a goal
Unintentional
Incident Reports
Reports Timeline

Loading...

Research and development has a major unsolved problem throughout state of the art AI systems: making systems perform well beyond the environment for which they were engineered. While this problem goes by many names (e.g., distributional shi…
Variants
A "variant" is an AI incident similar to a known case—it has the same causes, harms, and AI system. Instead of listing it separately, we group it under the first reported incident. Unlike other incidents, variants do not need to have been reported outside the AIID. Learn more from the research paper.
Seen something similar?
Similar Incidents
Selected by our editors
Loading...

Gender Biases in Google Translate
· 10 reports
Loading...
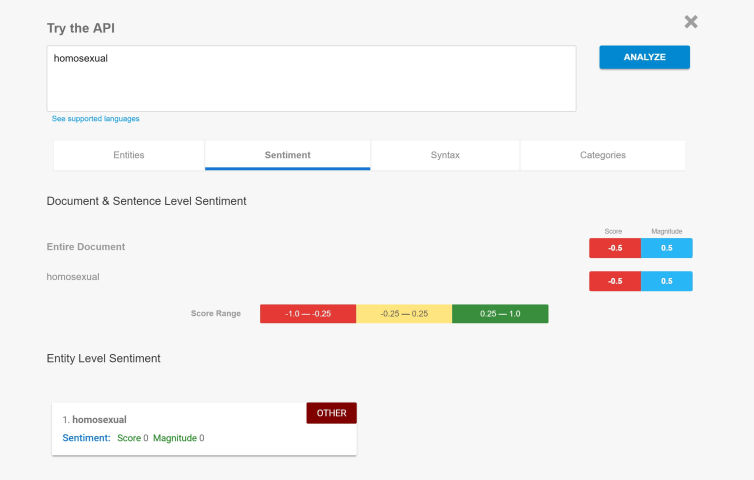
Biased Sentiment Analysis
· 6 reports
Did our AI mess up? Flag the unrelated incidents

Similar Incidents
Selected by our editors
Loading...
Gender Biases in Google Translate
· 10 reports
Loading...
Biased Sentiment Analysis
· 6 reports
Did our AI mess up? Flag the unrelated incidents