Associated Incidents

After all of the hype around the LLM shareable links this week I was inspired to investigate it further. On Friday, Google stopped indexing ChatGPT's shareable links, and several other providers were never indexed at all. However, after having seen that archive.org kept their own record, I was curious to see if other providers were saved there as well.
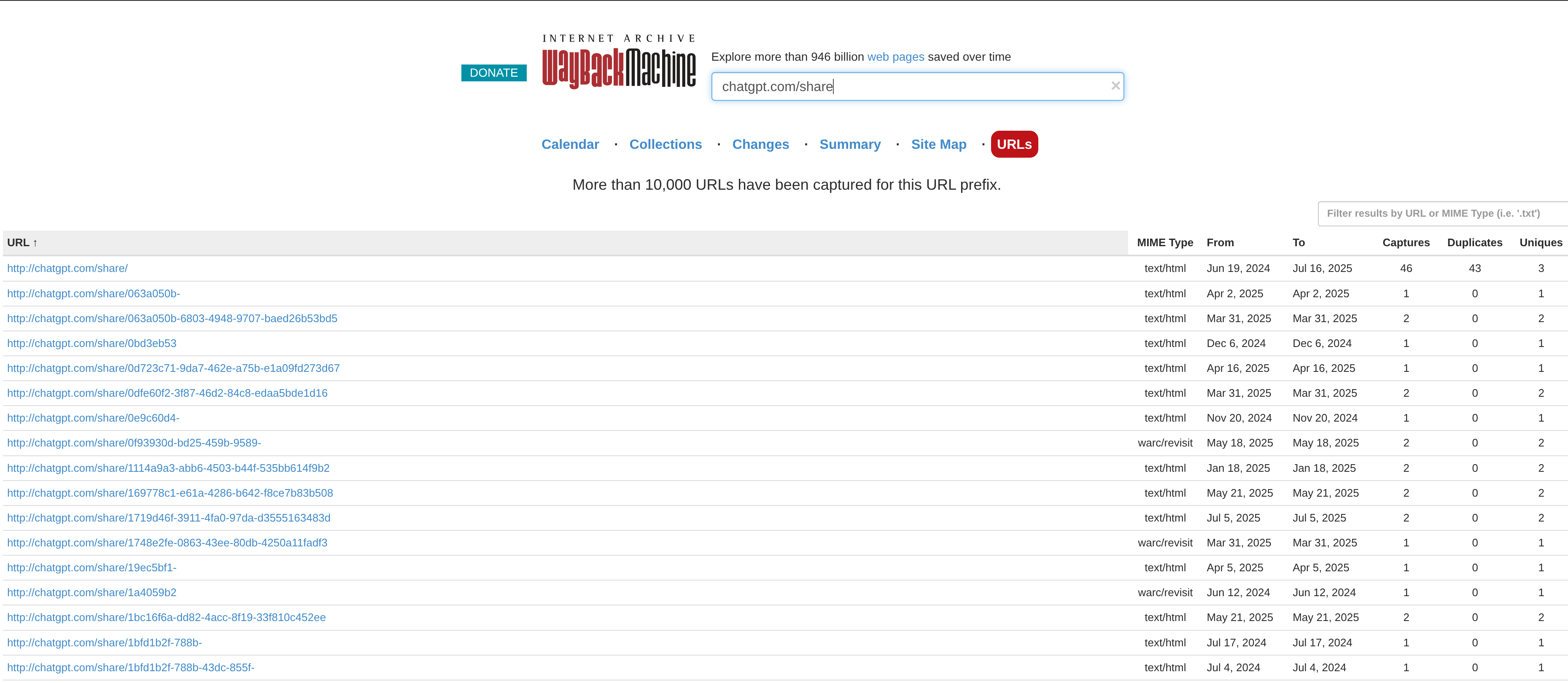
As you can see in the screenshot above, they in fact were. With Archive.org, we could now pull down the shareable links for:
-
Grok
-
ChatGPT
-
Mistral
-
Qwen
-
Claude
-
Copilot
And surely more, however I focused my attention solely on these providers for the purpose of this article.
By navigating to the archvie.org page on Burp Suite, I found that all of the URLs indexed were retrievable from an API call to:
https://web.archive.org/web/timemap/json?url=chatgpt.com%2Fshare&matchType=prefix&collapse=urlkey&output=json&fl=original%2Cmimetype%2Ctimestamp%2Cendtimestamp%2Cgroupcount%2Cuniqcount&filter=!statuscode%3A%5B45%5D..&limit=1000000&_=1754224717183
Using this, we could run a simple wget on the endpoint saving the content to our local host, then we grepped for the URL patter for each of the providers, and output the result to a file specific to each LLM.
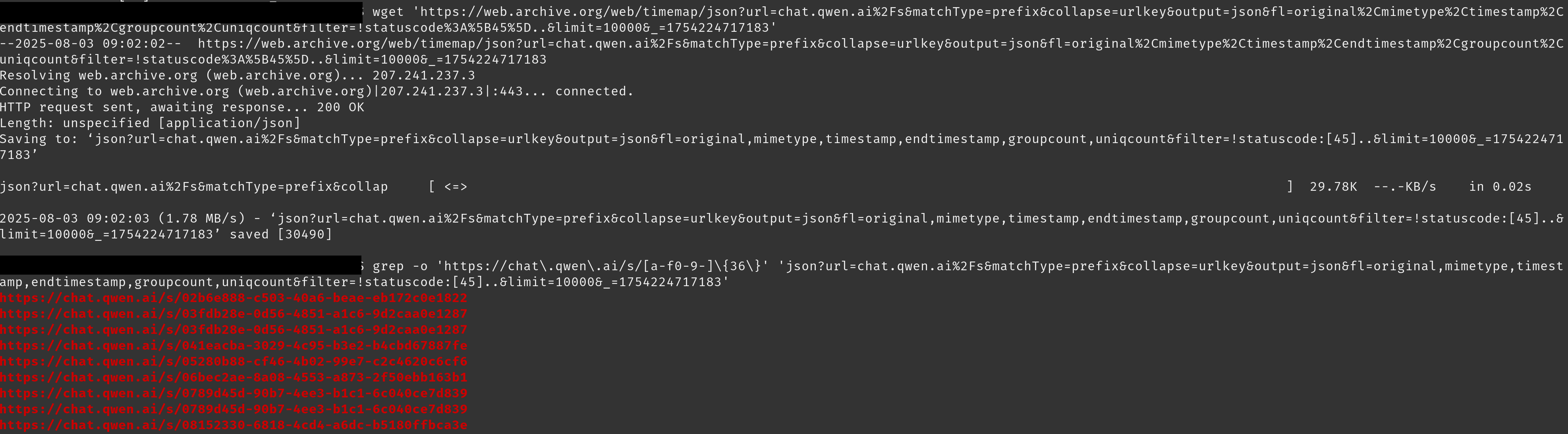
In total we collected 143,142 shared links which we could retrieve the content of. Here's the breakdown for each:
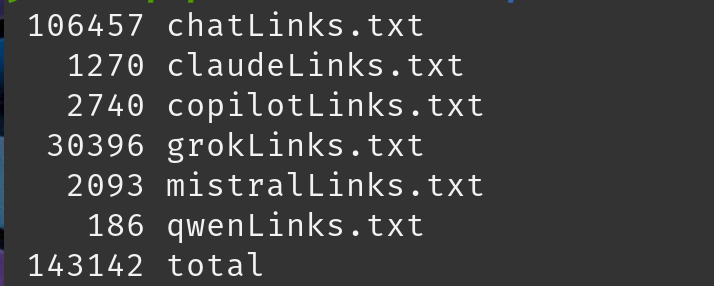
I found that each provider would have a different method of retrieving the chat history from the shared link. Some were a simple GET query to the shared link, while others had made an API call to another endpoint. To determine how it was retrieved I again browsed to a few of the URLs and located the chat content in my Burp Suite history and updated URLs where necessary.

Seen above is the endpoint used by Alibaba's Qwen LLM.
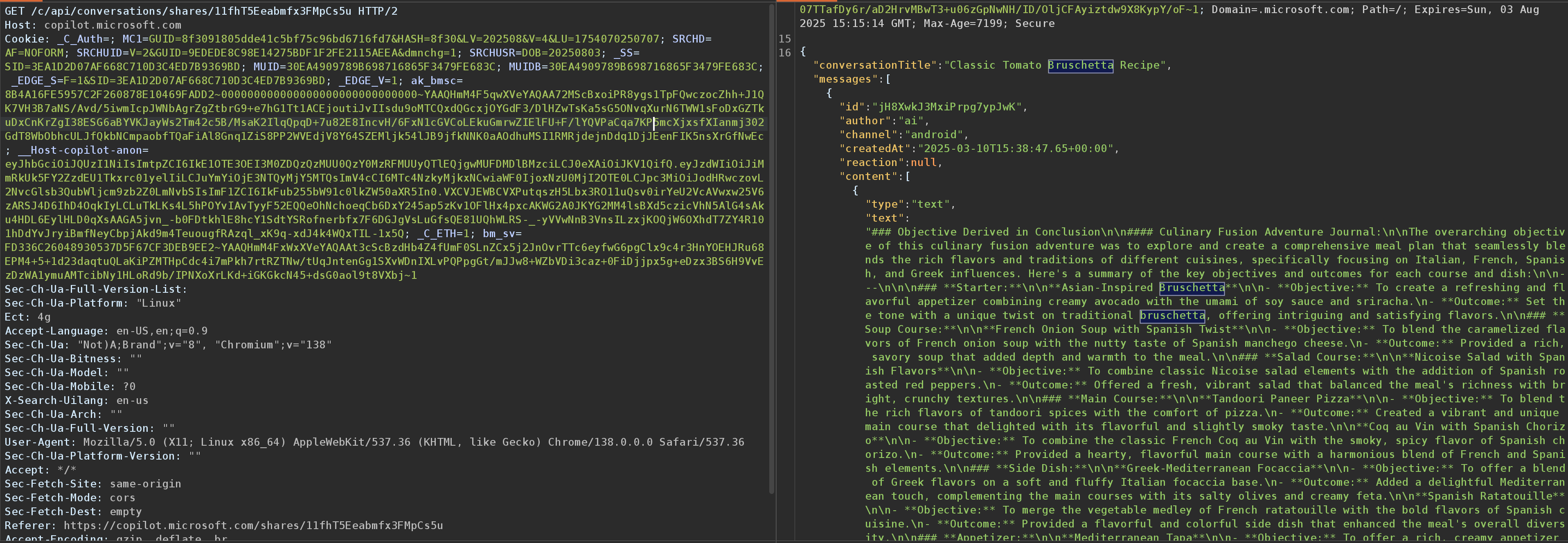
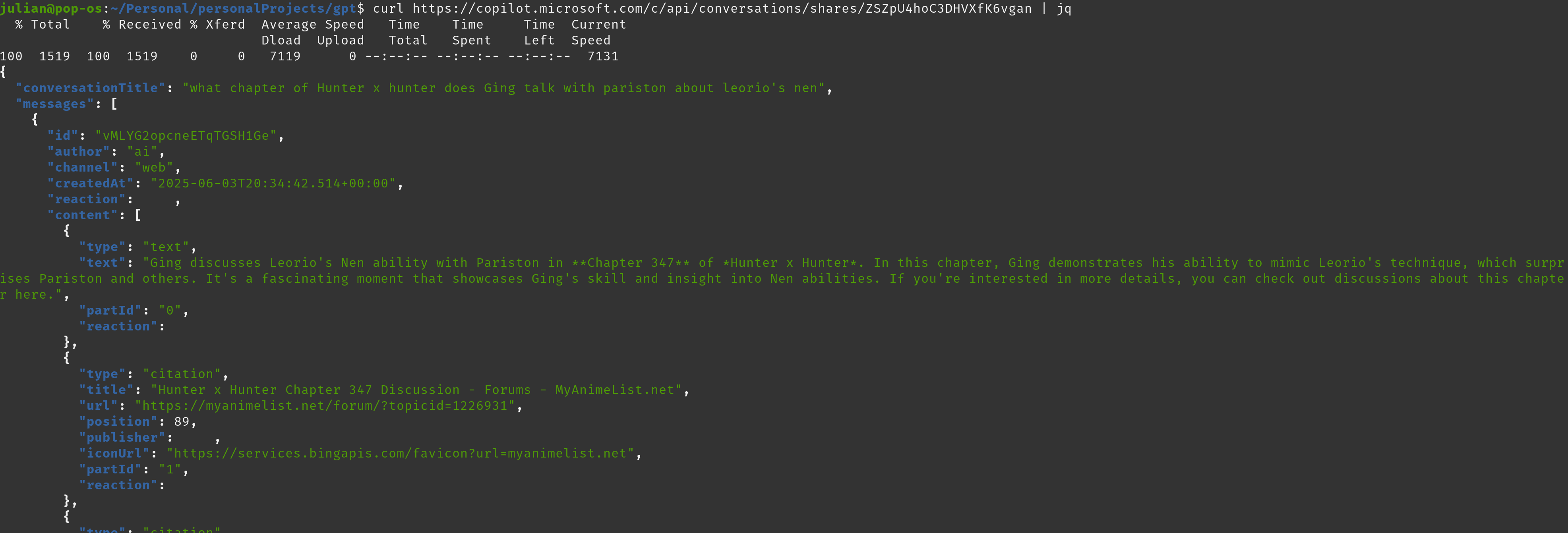
Seen above is the endpoint used by Copilot.
With the specific endpoints used for chats in hand I did a simple match and replace on the files which contained the URLs we'd be requesting.

Next was the task of curling each of these endpoints and writing the output to a file within the directory, a simple enough task.
Some providers required you pass a Cloudflare verification before displaying data. To get around, this I whipped up a quick Python script using Cloudscraper which is fairly good at getting around it.
import cloudscraper
INPUT_FILE = ''
OUTPUT_FILE = ''
scraper = cloudscraper.create_scraper()
scraper.headers.update({
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
})
last_successful_url = None
with open(INPUT_FILE, 'r') as infile, open(OUTPUT_FILE, 'w') as outfile:
for line in infile:
url = line.strip()
if not url:
continue
print(f"➡️ Requesting: {url}")
try:
response = scraper.get(url)
if response.status_code == 403:
print(f"\n❌ 403 Forbidden - stopping.\nLast successful URL: {last_successful_url}")
break
outfile.write(f"===== {url} =====\n")
outfile.write(response.text + "\n\n")
last_successful_url = url
except Exception as e:
print(f"⚠️ Error fetching {url}: {e}")
continue
Unfortunately, using something like Trufflehog on this dataset didn't seem to work too well. Instead, I had to run grep and try to manually review the results to see if anything could be useable for an attacker. With a couple of regexes I was able to find AWS Access Key IDs, a Replicate API token, and more. There is still tons of data to parse through and it's very likely that much more will be found over the coming days that may be worth mentioning in future updates. For now, here's a quick glimpse:
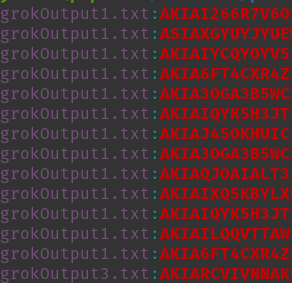


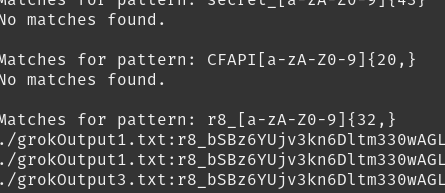
While these providers do tell their users that the shared links are public to anyone, I think that most who have used this feature would not have expected that these links could be findable by anyone, and certainly not indexed and readily available for others to view. This could prove to be a very valuable data source for attackers and red teamers alike. With this, I can now search the dataset at any time for target companies to see if employees may have disclosed sensitive information by accident.
A fun little thing I noticed when reviewing the output from the Claude chats was that each identified the user who created it and listed their full name.

[~] Special thanks to SyndromeImposter and MasterSplinter for their help with this!