Associated Incidents

🧵 Some thoughts about the recent release of Galactica by @MetaAI (everything here is my personal opinion) 👀
Let's start with the positive / What went well
{kind=link}
[1] The model was released and Open Source*
Contrary to the trend of very interesting research being closed or just accessible through paid APIs, by open-sourcing the models and building on top of existing OS tools, evaluation can be reliably done in a transparent and open way
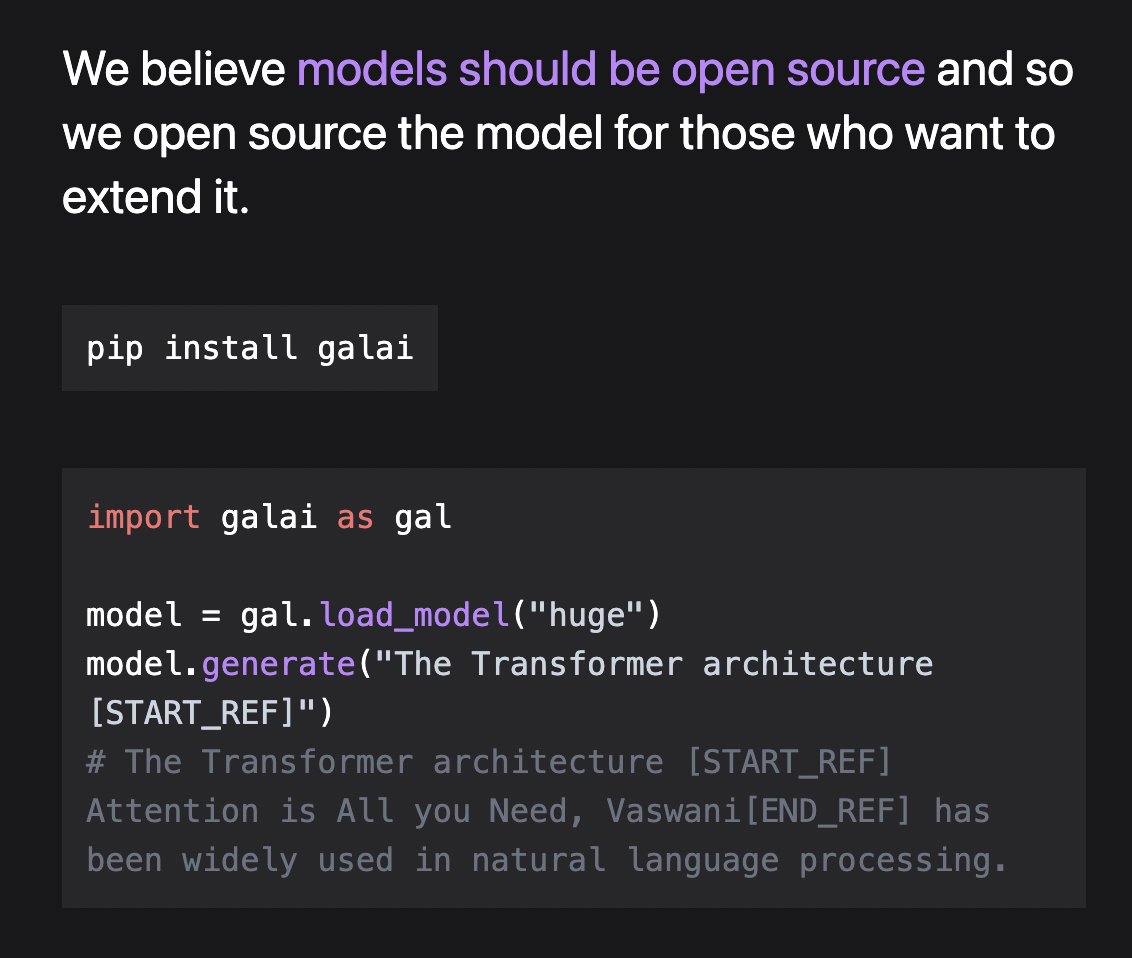{kind=link}
[2] There was a demo with the release**
Demos allow for a much wider audience to understand how models work. By having a demo with the release, a much more diverse audience can explore the model, identify points of failure, new biases, and more.
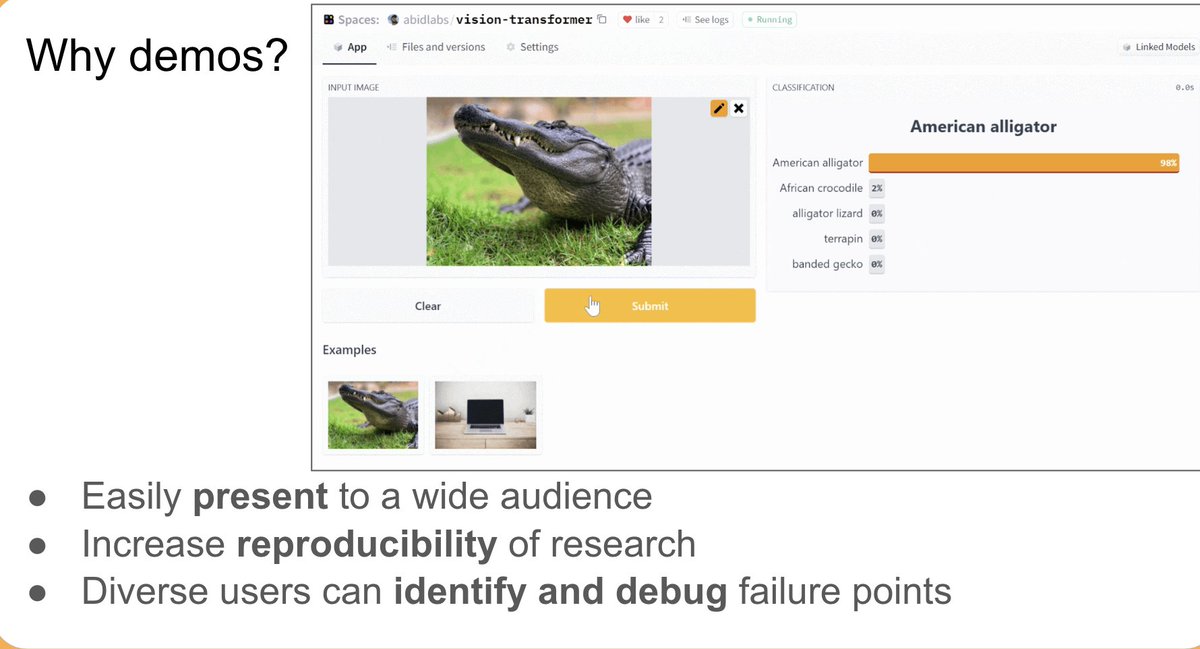{kind=link}
[3] Technically impressive!
Big Kudos where it's deserved. The model is technically impressive, with strong performance in different benchmarks, 50% citation accuracy, generation of latex and SMILES formulas, and more.
{kind=link}
/ What went wrong [1] Hype in announcements, mixing end-product with research. The announcement and page talk about "solving" information overload in science and that this can be used to write scientific code.
This communication style is very misleading and will cause misuse
{kind=link}
[2] Safety Filter in demo erasing communities
Although I imagine this was well-intentioned, the (non-transparent) safety filter removed content about queer theory and AIDS
OpenAI has been doing the same with Dalle 2 and received backlash as well
The safety filter - Censors content about minorities, further marginalizing people - Contradicts the idea of storing and reasoning about scientific knowledge
See more at
https://twitter.com/mmitchell_ai/status/1593351384573038592?s=20&t=8W0DbEqaln7hDKPY_xGhYQ
[3] Use cases were unclear, undocumented, or misleading
The limitations stated in the site and paper are quite limited and somewhat unclear. The paper says, "we would not advise using it for tasks that require this type of knowledge as this is not the intended use-case."
{kind=link}
There is also a somewhat hidden model card in github.com/paperswithcode…
But I find again that the documentation around limitations, biases, and use cases is too limited, given how powerful the model is
[4] Demo Although having a demo was nice, it could have done a better job in - Adding clearer disclaimers - Changing the UI to make it less like real-papers - Having a mechanism to identify such generated content
- Adding a way to flag toxic and erroneous content
[5] Related to the previous point, there was a lack of opportunity for the community to discuss and report issues, just by Twitter.
At @huggingface we learned that creating a space for public, open and transparent discussions on models is essential
thread#showTweet data-screenname=osanseviero data-tweet=1594420190619439104 dir=auto> As such, users have mechanisms to report outputs generated by the demo, explore the code used to create it, and discuss with the community about the work openly and transparently.
So TL;DR, what could be done better - More explicit use cases and limitations - Better documentation of the model - Consider OpenRAIL licenses, which dive into use cases much more than classical software licenses