Using AI to Connect AI Incidents
The AI Incident Database (AIID) launched publicly in November 2020 as a dashboard of AI harms realized in the real world. Inspired by similar databases in the aviation industry, its change thesis is derived from the Santayana aphorism, “Those who cannot remember the past are condemned to repeat it.” After amassing a collection of 1,600 incident reports, the AIID has much recorded "history" and a new set of problems: understanding the trends and relationships between incidents and ensuring we don't accept multiple copies of the same incident. Thus we set out to develop a tool to make it easier to connect and categorize the emerging history of AI harms.
This is a guest post written by three members of an Oregon State University (OSU) Capstone team, including Nicholas Broce, Nicholas Olson, and Jason Scott-Hakanson.[^1]
The Newest Tool in the Box
Each incident in the AIID is a collection of news reports about the same event, and each of these collections is given a unique “incident ID.” We built a tool that applies a neural network to all new incident reports, and returns the most semantically related incident -- according to the neural network. For example, let's input a report of a Tesla car crash and see what the neural network returns as most related,
This example is built around the API that takes arbitrary input text and outputs the IDs of the most similar incidents in the database. The API is currently being used by AIID editors to identify when new submissions are already in the database. It is also planned for future use-cases, including:
- seeding all incidents with a "Similar Incident" panel
- graphically visualizing relations between incidents in the AIID
- automatically identifying news reports to be added to the database
In testing, the model was about 94% accurate at correlating leave-one-out reports in the database back to their own incident IDs. The model is especially accurate with news reports or similarly long input texts, and less so with shorter input texts. We hope to tackle these and other issues in future iterations.
The project is fully open source and is built to be modular, extensible, and easily changed for future development. New models, new techniques, and new features can and will be easily added to this API to fulfill future needs.
If you want to know more about how this project was built, how it works, its current limitations, and how you can contribute, see our appendix on the technical details!
Try it Yourself!
You can find the first integration of this tool available at the report submission form, and we encourage you to play around with it and explore the articles you find. On the website scroll down to the field labeled “text” and enter a text of at least 256 non-space characters. After a short calculation time, articles will appear in the box labeled “Semantically Related Incidents” at the bottom of the page.
Credits
- Iz Beltagy, Matthew E. Peters, Arman Cohan at AllenAI for the Longformer model as hosted on Huggingface
- Luna McNulty and Sean McGregor for ongoing front-end work interfacing with the API
[^1]: Having completed their capstone, the authors will all be starting Software Engineering work this summer, with Nicholas Broce at Garmin AT, Nicholas Olson at Cognex, and Jason Scott-Hakanson at Lam Research.
Appendix
Click to show/hide the technical details
AWS Solution
To support scalable, asynchronous, and fast similarity correlation, this implementation uses a full stack of AWS tools, all built and deployed using AWS CDK v2. The AWS side of the solution primarily consists of a collection of AWS Lambdas and an AWS API Gateway RESTful HTTP API. This system and build-chain was designed to be highly modular and expandable, so that new Lambda functions or API features could be added at any time. In addition, the Longformer model can be easily swapped out for another pre-trained or fine-tuned model, so that future development can go in whatever direction best supports the growth of the database.
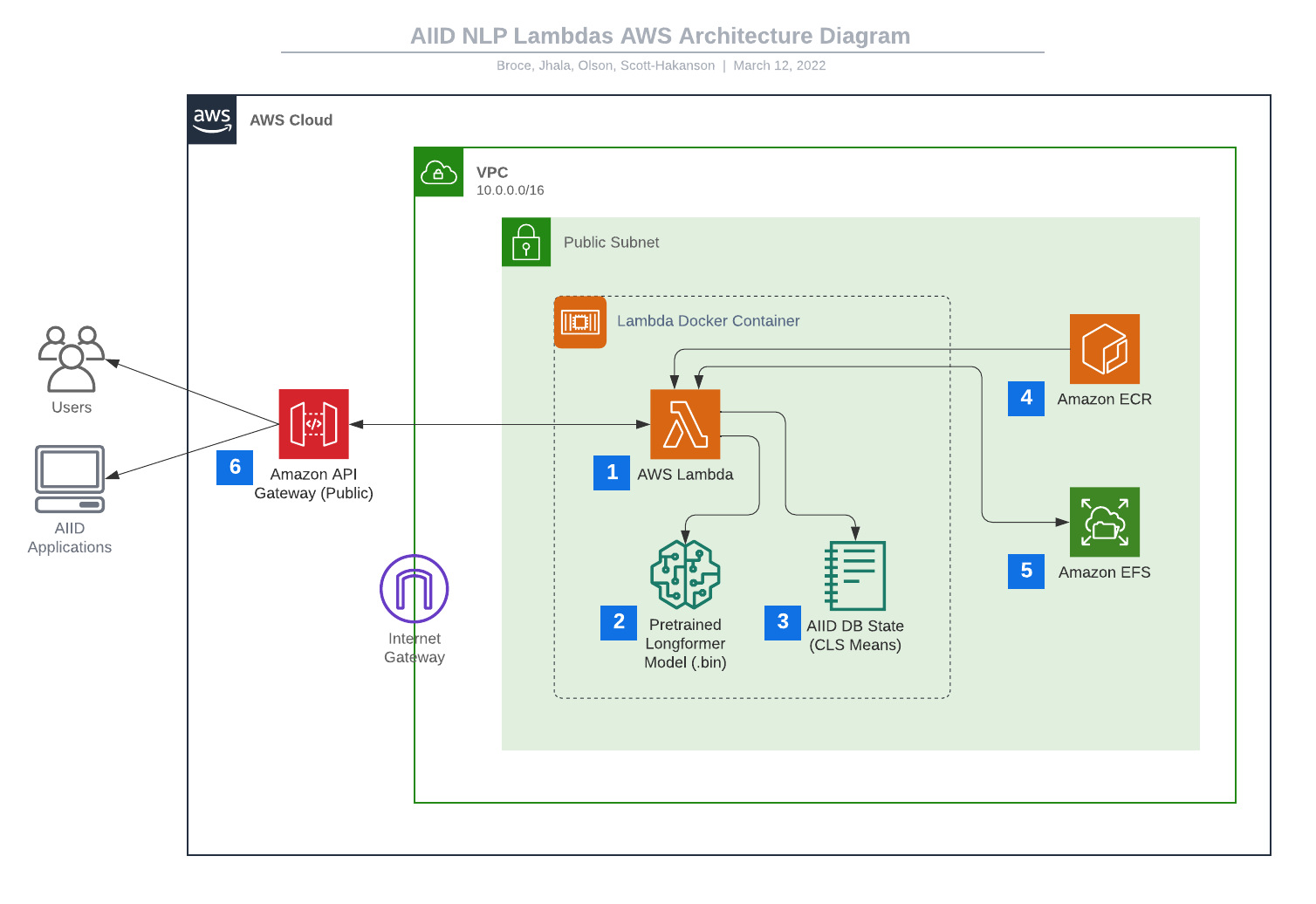
These modular Lambda functions fulfill slices or whole chunks of the different computations that comprise the text-to-similar-incident process. Currently, the system hosts a few Lambda functions, each with a dedicated endpoint on the API:
-
\/text-to-db-similar– which uses a Longformer instance to process the input report text and spit out a list of the most similar incident IDs -
\/embed-to-db-similar– which takes a pre-processed Longformer embedding for some report text and spits out a list of the most similar incident IDs

These Lambdas are powerful because an arbitrary number of instances can be spun up and executed at any time with incredibly low latency, as they are built as self-contained Docker images with all requirements pre-packaged and no required access to the outside internet.
NLP Solution
This solution uses AllenAI’s pretrained Long Document Transformer model (Longformer) to process query inputs, and also to maintain a state based representation of each incident in the AIID. Longformer is specifically designed to support long input sequences, which made it ideal for our purposes.

When a query is made to /text-to-db-similar, the API Lambda uses a local Longformer instance to tokenize the input text and process it into a set of high-dimensional vectors. The length of this set is equal to the number of tokens in the input. The first token in each embedding is a special classification (CLS) token, and when processed, it retains some latent information about the nature of the embedding. This latent representation is compared using cosine similarity against embeddings that are pre-processed for each incident currently in the database, and the incidents with the highest similarity are returned as likely candidates.
The embeddings that the query input is compared against are generated asynchronously by fetching newly added reports from the AIID, processing them using Longformer, and performing a weighted average between the old state for the report’s related incident, and the new embedding. In this way, the latent representation for an incident is the average of the representations of each of its related reports. Ideally, this approach leads itself to greater accuracy over time as more data is added, and remains scalable, as the state can be updated at any time using few resources.
Current Limitations
The launch-state of this new system has a few notable limitation that is important to note:
-
The system currently only contains a handful of Lambdas, but was built to be highly modular, so new additions are on the imminent horizon for this project.
-
We have noticed a potential bias in the system where incident IDs that have fewer existing reports may be less likely to achieve high-similarity scores. This requires more research and likely would only apply in our current demonstration of similarity of some input text to each of the incident IDs, as opposed to individual incident reports.
-
Longformer has a limit to the length of input text it can process, and the further this limit is stretched, the slower initialization/correlation becomes and the more resources the model demands. For these reasons, the system currently only processes the first 2,000 tokens (roughly 2,000 words) of each provided input text. This is more than enough for almost all texts in the database, but can easily be modified for individual Lambdas in the future.
-
The Longformer processing of report text works on comparing the model’s holistic understanding of the text, which leads to a few quirks popping up in use. Specifically of note is that the model tends to conceptualize short segments of text and longer articles differently, leading to the current example integration of the system giving unintuitive results for very short inputs of a few sentences. Currently, this system does not (try to) replace the Algolia search system the Discover application utilizes
Want to Help?
If you would like to help this tool grow and improve or would like to tinker with the systems we have set up, you can find all the code in the GitHub repository.