Indexing AI Risks with Incidents, Issues, and Variants
Two years after publicly launching the AI Incident Database (AIID) as a collection of harms or near harms produced by AI in the world, a backlog of "issues" that do not meet its incident ingestion criteria accumulated in its review queue. To understand why, let's take a look at the short Incident definition.
"Incident" Definition: An alleged harm or near harm event where an AI system is implicated.
This definition is "eventy," meaning a risk needs to be realized in the form of a harm. But what about reports of risks that have not necessarily been realized (yet)? In computer security, risks are "vulnerabilities" while a security incident is an "exposure." Some AI analogues include:

| "China develops AI 'prosecutor' to press charges 'with 97% accuracy'" Not an incident: The inevitable harm event has not happened yet. |
"AI and deepfakes present new risks for internet relationships" Not an incident: We lack a specific example. |

|

| "Slight Street Sign Modifications Can Completely Fool Machine Learning Algorithms" Not an incident: The vulnerability has yet to be exploited. |
The AI impacts community can learn from, respond to, and prevent many of these issues from developing into incidents, but they require formal definition and a rigorous criteria. Therefore, we introduce "issues" defined as:
"Issue" Definition: An alleged harm by an AI system that has yet to occur or be detected.
We recently made "issue reports" available in the AI Incident Database. You can now search the growing list of issues, which are also machine translated into Spanish and French. You can also search simultaneously across incidents and issues to explore emerging and realized risks in the world.
These definitions and their application within the AI Incident Database are subject to a large and growing collection of editing rules[a] that adjudicate difficult decisions. In most cases, the decision of whether something is or is not an incident or issue, turns on whether someone is alleging that it meets the more restrictive criteria. Our intention in proposing these definitions is to provide a forum and infrastructure for sorting out these foundational questions.

| Among the more important forums for sorting through these questions is the OECD.ai Working Group on Classification and Risk , through which the Responsible AI Collaborative (the Collab) is providing input on emerging intergovernmental definitions for a two tier AI risk framework similar to that being explored here. |
Adopting shared definitions for AI risks is both important and timely.
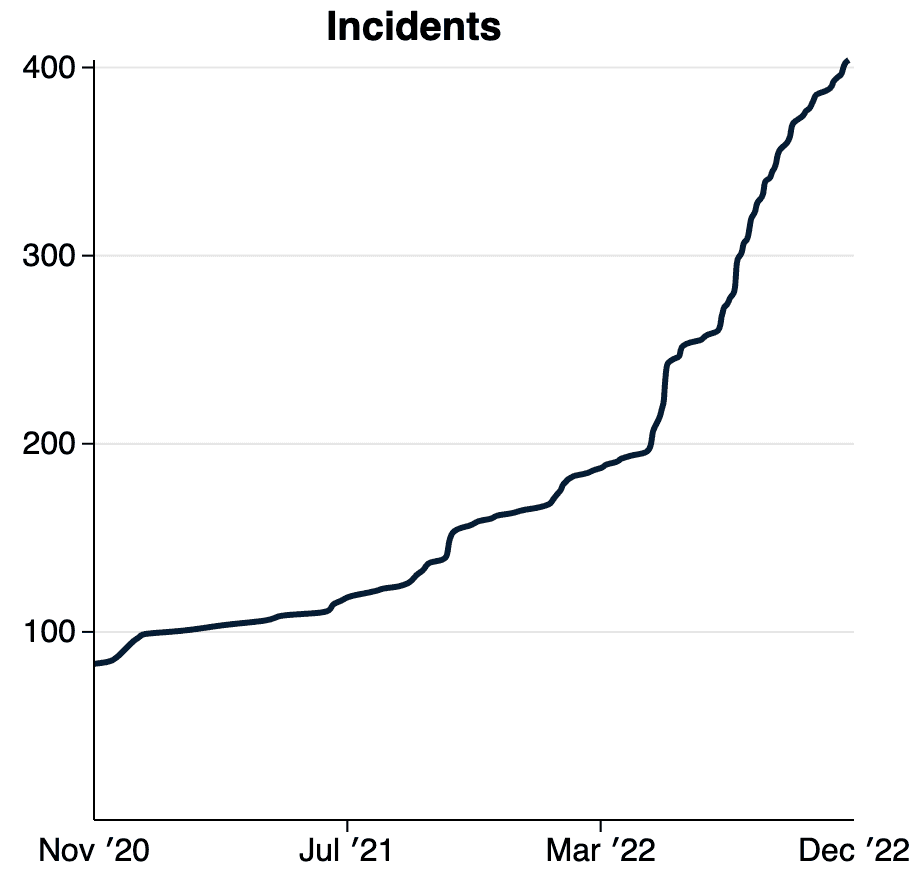
Having more than doubled the number of indexed AI incidents this year, we are beginning to see an increase in the pace of incident reporting. With the advent of deploying generative models to the real world, we expect this curve to soon become vertical. We plan to address the accelerating pace of incidents by introducing the concept of "variant" to the AI Incident Database. |
|
"Variant" Definition: An incident that shares the same causative factors, produces similar harms, and involves the same intelligent systems as a known AI incident.
Among the reasons to introduce "variants" to the incident database is to assemble large datasets of examples where inputs have produced harms. Most AI systems produce and act on data, so collecting the circumstances in which AI systems perform poorly is of immense importance for ensuring it does not recur. Impact datasets can come to define safety testing throughout industry, thereby moving beyond qualitative processes to quantifiably-assured system deployments. We will soon begin indexing bad generative text before moving on to other system types.
Finally, we note our privileged position in the AI social impact space and wish to note that the research paper published in the NeurIPS Workshop on Human-Centered AI also details a planned incident identifier for a world where there are multiple interrelated incident databases. No single database can index all AI incidents and issues in the world, but we desperately need to ensure that all incident data is shared. The AI Incident Database codebase is thus moving to support federation (i.e., sharing) of data among multiple countries, regulators, languages, and companies. Please reach out if you would like more information on federation plans.
Read the Research Paper(It expands on several elements) | |
|---|---|
McGregor, S., Paeth, K., & Lam, K. (2022). Indexing AI Risks with Incidents, Issues, and Variants. In Proceedings of the NeurIPS Workshop on Human-Centered AI (NeurIPS-22). Virtual Conference. | |
Abstract: Despite not passing the database's current criteria for incidents, these issues advance human understanding of where AI presents the potential for harm. Similar to databases in aviation and computer security, the AIID proposes to adopt a two-tiered system for indexing AI incidents (i.e., a harm or near harm event) and issues (i.e., a risk of a harm event). Further, as some machine learning-based systems will sometimes produce a large number of incidents, the notion of an incident "variant" is introduced. These proposed changes mark the transition of the AIID to a new version in response to lessons learned from editing 2,000+ incident reports and additional reports that fall under the new category of "issue." |

|
Acknowledgements: Kate Perkins gave valuable feedback on the contents of the paper in addition to her duties as an AIID incident editor. The definitions and discussions presented within the paper are also greatly influenced by ongoing efforts by the Organisation for Economic Co-operation and Development (OECD) to adopt a shared definition of AI incident across all 38 member states. Finally, the AIID is an effort by many people and organizations organized under the banner of the Responsible AI Collaborative, including the Center for Security and Emerging Technology (CSET), whose Zachary Arnold contributed to the first incident criteria and definition. Several people have contributed to the implementation of the database features, including César Varela, Pablo Costa, Clara Youdale, and Luna McNulty. It is through the Collab's collective efforts that the ontological perspectives presented above have meaning and real world importance.
The AI Incident Briefing

Create an account to subscribe to new incident notifications and other updates.