概要: フェイスブックのヘイトスピーチ検出アルゴリズムは、黒人、イスラム教徒、LGBTQ、ユダヤ教徒などの少数派グループが頻繁に経験する、あまり一般的ではないがより有害なコンテンツを過小報告していることが同社の研究者によって判明した。
Risk Subdomain
A further 23 subdomains create an accessible and understandable classification of hazards and harms associated with AI
1.3. Unequal performance across groups
Risk Domain
The Domain Taxonomy of AI Risks classifies risks into seven AI risk domains: (1) Discrimination & toxicity, (2) Privacy & security, (3) Misinformation, (4) Malicious actors & misuse, (5) Human-computer interaction, (6) Socioeconomic & environmental harms, and (7) AI system safety, failures & limitations.
- Discrimination and Toxicity
Entity
Which, if any, entity is presented as the main cause of the risk
AI
Timing
The stage in the AI lifecycle at which the risk is presented as occurring
Post-deployment
Intent
Whether the risk is presented as occurring as an expected or unexpected outcome from pursuing a goal
Unintentional
インシデントレポート
レポートタイムライン


Loading...

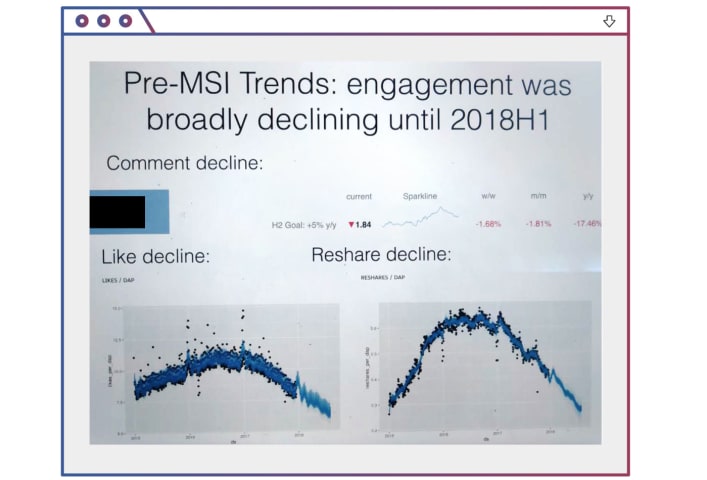
In public, Facebook seems to claim that it removes more than 90 percent of hate speech on its platform, but in private internal communications the company says the figure is only an atrocious 3 to 5 percent. Facebook wants us to believe tha…
Loading...

Last year, researchers at Facebook showed executives an example of the kind of hate speech circulating on the social network: an actual post featuring an image of four female Democratic lawmakers known collectively as “The Squad.”
The poste…
バリアント
「バリアント」は既存のAIインシデントと同じ原因要素を共有し、同様な被害を引き起こし、同じ知的システムを含んだインシデントです。バリアントは完全に独立したインシデントとしてインデックスするのではなく、データベースに最初に投稿された同様なインシデントの元にインシデントのバリエーションとして一覧します。インシデントデータベースの他の投稿タイプとは違い、バリアントではインシデントデータベース以外の根拠のレポートは要求されません。詳細についてはこの研究論文を参照してください
似たようなものを見つけましたか?