Incidents associés
Un porte-parole de Google a répondu à la demande de commentaire de Motherboard et a publié la déclaration suivante : "Nous déployons beaucoup d'efforts pour nous assurer que l'API NLP évite les biais, mais nous ne faisons pas toujours les choses correctement. Ceci est un exemple d'une de ces situations. , et nous en sommes désolés. Nous prenons cela au sérieux et travaillons à l'amélioration de nos modèles. Nous allons corriger ce cas précis, et, plus largement, construire des algorithmes plus inclusifs est crucial pour apporter les bénéfices du machine learning à tous."
John Giannandrea, responsable de l'intelligence artificielle chez Google, a déclaré lors d'une conférence plus tôt cette année que sa principale préoccupation concernant l'IA n'était pas les robots mortels super intelligents, mais ceux qui discriminent. "La vraie question de sécurité, si vous voulez l'appeler ainsi, est que si nous donnons à ces systèmes des données biaisées, ils seront biaisés", a-t-il déclaré.
Ses craintes semblent s'être déjà glissées dans les propres produits de Google.
En juillet 2016, Google a annoncé le lancement public de la version bêta d'une nouvelle interface de programme d'application (API) d'apprentissage automatique, appelée API Cloud Natural Language. Il permet aux développeurs d'intégrer les modèles d'apprentissage en profondeur de Google dans leurs propres applications. Comme l'entreprise l'a dit dans son annonce de l'API, elle vous permet de "révéler facilement la structure et la signification de votre texte dans une variété de langues".
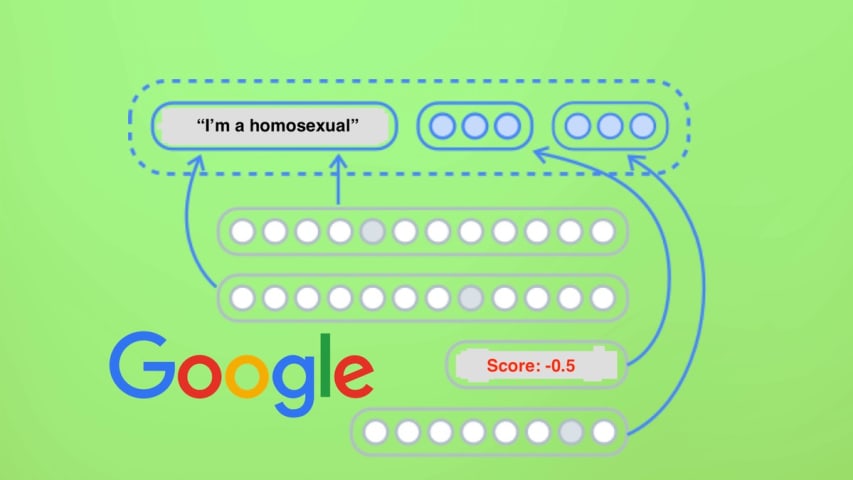
En plus de la reconnaissance d'entités (déchiffrement de ce dont on parle dans un texte) et de l'analyse syntaxique (analyse de la structure de ce texte), l'API comprenait un analyseur de sentiments pour permettre aux programmes de déterminer dans quelle mesure les phrases exprimaient un sentiment négatif ou positif, sur une échelle de -1 à 1. Le problème est que l'API classe les phrases sur les minorités religieuses et ethniques comme négatives, ce qui indique qu'elles sont intrinsèquement biaisées. Par exemple, il qualifie à la fois d'être juif et d'être homosexuel comme négatifs.
L'analyseur de sentiments de Google n'était pas le premier et n'est pas le seul sur le marché. La technologie d'analyse des sentiments est née du groupe de traitement du langage naturel de Stanford, qui propose des outils gratuits et open source de traitement du langage pour les développeurs et les universitaires. La technologie a été intégrée à une multitude de suites d'apprentissage automatique, notamment Azure de Microsoft et Watson d'IBM. Mais les API d'apprentissage automatique de Google, comme ses produits destinés aux consommateurs, sont sans doute les plus accessibles, en partie en raison de leur prix abordable.
Mais l'analyseur de sentiments de Google n'est pas toujours efficace et produit parfois des résultats biaisés.
Il y a deux semaines, j'ai expérimenté l'API pour un projet sur lequel je travaillais. J'ai commencé à lui fournir des exemples de textes, et l'analyseur a commencé à cracher des scores qui semblaient en contradiction avec ce que je lui donnais. Je lui ai ensuite lancé des phrases simples sur différentes religions.
Quand je l'ai nourri "Je suis chrétien", il a dit que la déclaration était positive :
Quand je l'ai nourri "Je suis un sikh", il a dit que la déclaration était encore plus positive :
Mais quand je lui ai donné "Je suis juif", il a déterminé que la phrase était légèrement négative :
Le problème ne semble pas confiné aux religions. Il pensait de la même manière que les déclarations sur le fait d'être homosexuel ou d'être une femme noire gay étaient également négatives :
Être un chien ? Neutre. Être homosexuel ? Négatif:
Je pourrais continuer, mais vous pouvez essayer vous-même : Google Cloud propose une interface facile à utiliser pour tester l'API.
Il semble que l'analyseur de sentiments de Google soit biaisé, comme de nombreux algorithmes artificiellement intelligents l'ont été. Les systèmes d'IA, y compris les analyseurs de sentiments, sont entraînés à l'aide de textes humains tels que des reportages et des livres. Par conséquent, ils reflètent souvent les mêmes préjugés que l'on retrouve dans la société. Nous ne connaissons pas encore la meilleure façon de supprimer complètement les biais de l'intelligence artificielle, mais il est important de continuer à les exposer.
L'année dernière, par exemple, des chercheurs de Princeton ont publié un article sur une technique de traitement du langage naturel de pointe appelée GloVe. Les chercheurs ont recherché des biais dans l'algorithme contre les minorités et les femmes en recherchant les mots avec lesquels ils apparaissaient le plus dans une "exploration à grande échelle du Web, contenant 840 milliards de [mots]". Dans le cas du genre, cela signifiait, dans une expérience, chercher à voir si les noms et attributs féminins (comme "sœur") étaient plus associés à des mots d'arts ou de mathématiques (comme "poésie" ou "maths", respectivement). Dans le cas de la race, une expérience a recherché des associations entre des noms noirs (comme "Jermaine" ou "Tamika") avec des mots dénotant l'agrément ou la négativité (comme "ami" ou "terrible", respectivement).
En classant le sentiment des mots à l'aide de GloVe, les chercheurs "ont trouvé tous les biais linguistiques documentés en psychologie que nous avons recherchés". Les noms noirs étaient fortement associés à des mots désagréables, les noms féminins à des termes artistiques, etc. Les biais dans l'article ne sont pas nécessairement les mêmes que ceux que l'on peut trouver dans l'API Natural Language de Google (les genres et les noms des personnes, par exemple, sont neutres de manière fiable dans l'API), mais le problème est plus ou moins le même : des données biaisées in, classifications biaisées out.
Naturel