
*Cet article est publié avec le soutien de The Capitol Forum. * L'ensemble de données d'apprentissage automatique LAION-5B utilisé par Stable Diffusion et d'autres produits majeurs d'IA a été supprimé par l'organisation qui l'a créé après qu'une étude de Stanford a révélé qu'il contenait 3 226 cas suspects de matériel d'abus sexuel sur des enfants, dont 1 008 ont été validés en externe. LAION a déclaré mardi à 404 Media que par « beaucoup de prudence », il supprimait temporairement ses ensembles de données, y compris LAION-5B et un autre appelé LAION-400M « pour garantir leur sécurité avant de les republier ». Selon une nouvelle étude du Stanford Internet Observatory partagée avec 404 Media avant la publication, les chercheurs ont trouvé les cas suspects de CSAM grâce à une combinaison de détection et d'analyse perceptuelle et cryptographique basée sur le hachage des images elles-mêmes. "Nous constatons que la possession d'un ensemble de données LAION-5B peuplé même à la fin de 2023 implique la possession de milliers d'images illégales --- sans compter toutes les images intimes publiées et collectées de manière non consensuelle, dont la légalité est plus variable selon juridiction", indique le journal. "Bien que la quantité de CSAM présente n'indique pas nécessairement que la présence de CSAM influence considérablement les résultats du modèle au-delà de la capacité du modèle à combiner les concepts d'activité sexuelle et d'enfants, elle exerce probablement toujours une influence. des instances identiques de CSAM sont également problématiques, notamment en raison du renforcement des images de victimes spécifiques. Cette découverte met en évidence le danger d’un piratage largement aveugle d’Internet à des fins d’intelligence artificielle générative. Large-scale Artificial Intelligence Open Network, ou LAION, est une organisation à but non lucratif qui crée des outils open source pour l'apprentissage automatique. LAION-5B est l’un de ses produits les plus importants et les plus populaires. Il est composé de plus de cinq milliards de liens vers des images extraites du Web ouvert, y compris des plateformes de médias sociaux générées par les utilisateurs, et est utilisé pour former les modèles de génération d'IA les plus populaires actuellement sur le marché. Stable Diffusion, par exemple, utilise LAION-5B et Stability AI a financé son développement. "Si vous avez téléchargé cet ensemble complet de données dans un but quelconque, pour former un modèle à des fins de recherche, alors oui, vous disposez absolument du CSAM, à moins que vous n'ayez pris des mesures extraordinaires pour l'arrêter", David Thiel, auteur principal de l'étude et technologue en chef. à l'Observatoire Internet de Stanford, a déclaré à 404 Media. Les discussions publiques des dirigeants de LAION sur le serveur Discord officiel de l'organisation montrent qu'ils étaient conscients de la possibilité que du CSAM soit récupéré dans leurs ensembles de données dès 2021. "Je suppose que distribuer un lien vers une image telle que de la pédopornographie peut être considéré comme illégal, " L'ingénieur principal de LAION, Richard Vencu, a écrit en réponse à un chercheur demandant comment LAION gère les données illégales potentielles qui pourraient être incluses dans l'ensemble de données. "Nous avons essayé d'éliminer de telles choses, mais rien ne garantit qu'elles le seront toutes." [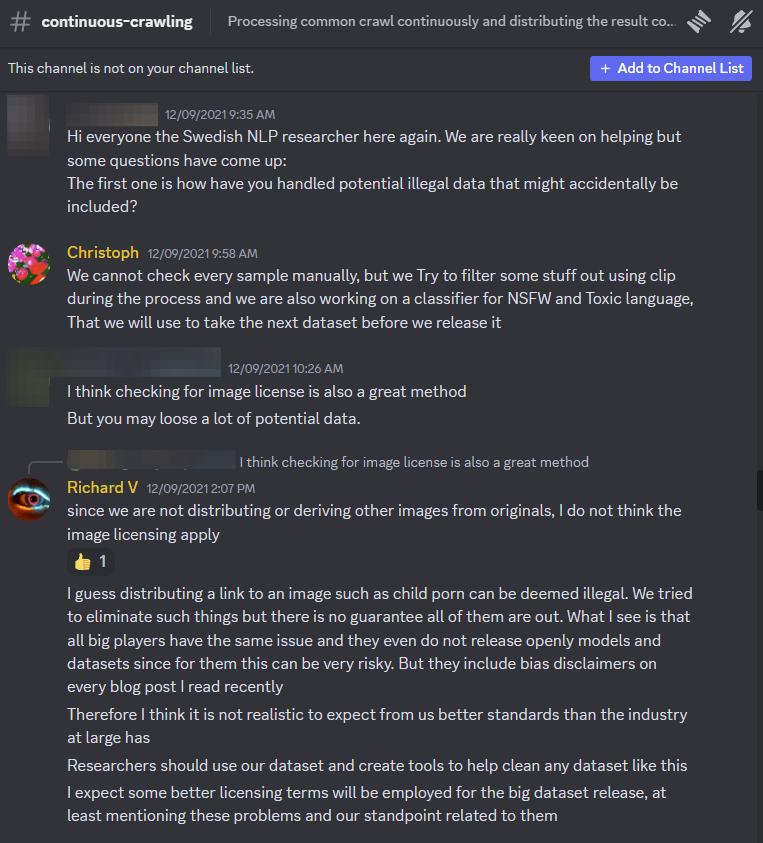 ](https://www.404media.co/content/images/2023/12/laion_discord_1 -1.png) CAPTURE D'ÉCRAN VIA LAION DISCORD La plupart des institutions aux États-Unis, y compris l'équipe de Thiel, ne sont pas légalement autorisées à visualiser le CSAM afin de le vérifier elles-mêmes. Pour effectuer des recherches CSAM, les experts s'appuient souvent sur le hachage perceptuel, qui extrait une signature numérique unique ou une empreinte digitale. , à partir d'une image ou d'une vidéo. PhotoDNA est une technologie qui crée des hachages uniques pour les images d'exploitation d'enfants afin de retrouver ces images ailleurs sur le Web et de les faire supprimer ou de poursuivre les agresseurs ou les proliférateurs. "Dans le but de quantifier le degré de présence du CSAM dans l'ensemble de données d'entraînement ainsi que de l'éliminer des ensembles de données LAION-5B et dérivés, nous utilisons diverses techniques complémentaires pour identifier le CSAM potentiel dans l'ensemble de données : détection basée sur le hachage perceptuel, détection cryptographique basée sur le hachage et analyse des voisins les plus proches exploitant les intégrations d'images dans l'ensemble de données lui-même », indique le document. Grâce à ce processus, ils ont identifié au moins 2 000 entrées d’ensembles de données suspectées de CSAM et ont confirmé ces entrées auprès de tiers. Pour faire ses recherches, Thiel a déclaré qu'il s'était concentré sur les URL identifiées par le classificateur de sécurité de LAION comme « non sûres pour le travail » et avait envoyé ces URL à PhotoDNA. Les correspondances de hachage indiquent un CSAM certain et connu et ont été envoyées à l'API du projet Arachnid Shield et validées par le Centre canadien de protection de l'enfance, qui est en mesure de visualiser, vérifier et signaler ces images aux autorités. Une fois ces images vérifiées, ils ont également pu trouver des correspondances de « voisin le plus proche » dans l'ensemble de données, où les images associées des victimes étaient regroupées. LAION aurait pu utiliser une méthode similaire à celle-ci avant de publier le plus grand ensemble de données de formation à l'IA au monde, a déclaré Thiel, mais ce n'est pas le cas. "[LAION] a initialement utilisé CLIP pour essayer de filtrer certaines choses, mais il ne semble pas qu'ils l'aient fait en consultation avec des experts en sécurité des enfants au départ. C'était bien qu'ils aient essayé. Mais les mécanismes qu'ils ont utilisés n'étaient tout simplement pas super. impressionnant", a déclaré Thiel. "Ils ont fait une tentative qui était loin d'être suffisante, et ce n'est pas ainsi que je l'aurais fait si j'avais essayé de concevoir un système sûr." Un porte-parole de LAION a déclaré à 404 Media dans une déclaration à propos de l'article de Stanford : *"LAION est une organisation à but non lucratif qui fournit des ensembles de données, des outils et des modèles pour l'avancement de la recherche sur l'apprentissage automatique. Nous nous engageons en faveur d'une éducation publique ouverte et d'une protection de l'environnement. utilisation des ressources grâce à la réutilisation d'ensembles de données et de modèles existants. Les ensembles de données LAION (plus de 5,85 milliards d'entrées) proviennent de l'index Web Common Crawl disponible gratuitement et offrent uniquement des liens vers du contenu sur le Web public, sans images. Nous avons développé et publié nos propres filtres rigoureux pour détecter et supprimer le contenu illégal des ensembles de données LAION avant de les publier. Nous collaborons avec des universités, des chercheurs et des ONG pour améliorer ces filtres et travaillons actuellement avec l'Internet Watch Foundation (IWF) pour identifier et supprimer les contenus soupçonnés de violer les lois. . Nous invitons les chercheurs de Stanford à rejoindre LAION pour améliorer nos ensembles de données et développer des filtres efficaces pour détecter les contenus préjudiciables. LAION a une politique de tolérance zéro pour les contenus illégaux et, par prudence, nous supprimons temporairement les ensembles de données LAION pour nous assurer qu'ils sont en sécurité avant de les republier. qui a examiné le paysage des modèles génératifs visuels qui pourraient être utilisés pour créer du CSAM. Thiel m'a dit qu'il avait continué à approfondir le sujet après un conseil du chercheur en IA Alex Champandard, [qui a trouvé l'URL d'une image dans LAION-5B](https://huggingface.co/datasets/laion/laion2B-multi/discussions/ 3?ref=404media.co ) sur Hugging Face qui était sous-titré avec une phrase en espagnol qui semblait décrire du matériel d'exploitation des enfants. LAION-5B est disponible en téléchargement sur Hugging Face en tant qu'outil open source. Champandard m'a dit il a remarqué un rapport à Hugging Face sur LAION-5B en août 2022, signalant « un exemple qui décrit quelque chose lié à la pédophilie. L'un des ingénieurs qui ont travaillé sur LAION-5B a répondu en mars 2023, affirmant que le lien était mort mais qu'ils l'avaient quand même supprimé car la légende était inappropriée. "Il a fallu 7 mois pour que ce rapport soit traité par Hugging Face ou LAION --- ce que j'ai trouvé très discutable", a déclaré Champandard. [](https://lh7-us.googleusercontent.com/JvxvXAe7vYRGQl8fGb0lPy3X7uzqGL1NAuxzKRcoZ_0TGSxQRn7eCBjRBS7Pz0Vx0YSAHhrxbGVyBq6KjCbkY3-GscWVLHw8 TMJVd6qHiqHQufPz5YBG9DzVJ24-oiBeEVZU49AN-_RyYbWgScWayEo) Suite aux tweets de Champandard , Margaret Mitchell, scientifique en chef de l'éthique chez Hugging Face a écrit sur Mastodon : "Je voulais juste intervenir pour dire qu'il y a eu beaucoup de du temps et de l'énergie consacrés à essayer de trouver des CSAM, et aucun n'a été trouvé. Certaines personnes de HF sont attaquées comme s'il s'agissait de pédophiles, mais c'est juste... une cruauté inappropriée. J'ai demandé à Hugging Face si, à la lumière de cette étude et avant que LAION ne supprime lui-même les ensembles de données, il prendrait des mesures contre les datasts qui auraient des liens avec CSAM. Un porte-parole de l'entreprise a répondu : « Oui ». "Les ensembles de données ne peuvent pas être vus par le personnel de Hugging Face (ni par toute personne accédant au Hub) jusqu'à ce qu'ils soient téléchargés, et celui qui télécharge peut décider de rendre le contenu public. Une fois partagé, la plateforme effectue une analyse du contenu pour identifier les problèmes potentiels. Les utilisateurs sont responsables du téléchargement. et maintenir le contenu, et le personnel résout les problèmes en suivant les directives de contenu de la plateforme Hugging Face, que nous continuons à [adapter](https://huggingface .co/blog/content-guidelines-update?ref=404media.co ). La plate-forme s'appuie sur une combinaison d'analyse de contenu technique pour valider que les directives sont effectivement suivies, de modération de la communauté et de fonctionnalités de reporting pour permettre aux utilisateurs de faire part de leurs préoccupations. Nous surveillons les signalements et prenons des mesures lorsqu'un contenu en infraction est signalé", a déclaré le porte-parole de Hugging Face. « Il est essentiel pour cette discussion de noter que l'ensemble de données LAION-5B contient des URL vers du contenu externe, et non des images, ce qui pose des défis supplémentaires. Nous travaillons avec la société civile et les partenaires industriels pour développer de bonnes pratiques pour gérer ce type de questions multiplateformes. " L'article de Stanford indique que le matériel détecté au cours de leur processus est « intrinsèquement un sous-dénombrement important en raison du caractère incomplet des ensembles de hachage de l'industrie, de l'attrition du contenu hébergé en direct, du manque d'accès aux ensembles d'images de référence LAION d'origine et de la précision limitée des informations « dangereuses ». 'classificateurs de contenu." Plusieurs grandes sociétés d'IA générative, Stable Diffusion, utilisent LAION-5B, tandis que d'autres ont utilisé les produits de LAION à différents stades de développement. "Les ensembles de données LAION ont également été utilisés pour entraîner d'autres modèles, tels que Imagen de Google, qui a été formé sur une combinaison d'ensembles de données internes et de LAION-400M", indique l'article de Stanford. « Notamment, lors d'un audit du LAION-400M, les développeurs d'Imagen ont découvert « un large éventail de contenus inappropriés, notamment des images pornographiques, des insultes racistes et des stéréotypes sociaux préjudiciables », et les ont jugés impropres à un usage public. Suite à la publication de l'article, un porte-parole de Google a déclaré à 404 Media : « Imagen n'a jamais utilisé LAION-5B. Plus précisément, LAION-400M a été utilisé uniquement pour entraîner le premier modèle de recherche Imagen, qui n'a jamais été publié. Aucune des itérations suivantes de le modèle utilise n'importe quelle version des ensembles de données LAION. 400-M a également été supprimé par LAION, par « excès de prudence » concernant les conclusions du document. Un porte-parole de Stable Diffusion a déclaré à 404 Media après la publication de l'article : « Stable Diffusion 1.5 a été publié par RunwayML, et non par Stability AI. Ce rapport se concentre sur l'ensemble de données LAION-5b dans son ensemble. Les modèles d'IA de stabilité ont été formés sur un sous-ensemble filtré de cet ensemble de données. En outre, nous avons ensuite affiné ces modèles pour atténuer les comportements résiduels. Nous nous engageons à prévenir l’utilisation abusive de l’IA et à interdire l’utilisation de nos modèles d’image et de nos services à des fins d’activités illégales, y compris les tentatives de modification ou de création de CSAM. AI héberge uniquement les versions de Stable Diffusion qui incluent des filtres sur son API. Ces filtres empêchent le contenu dangereux d'atteindre les modèles. En supprimant ce contenu avant qu'il n'atteigne le modèle, nous pouvons aider à empêcher le modèle de générer du contenu dangereux. De plus, nous Nous avons mis en œuvre des filtres pour intercepter les invites ou les sorties dangereuses lorsque les utilisateurs interagissent avec des modèles sur notre plateforme. Nous avons également investi dans des fonctionnalités d'étiquetage de contenu pour aider à identifier les images générées sur notre plateforme. Ces niveaux d'atténuation rendent plus difficile l'utilisation abusive de l'IA par les acteurs malveillants. le domaine du « dark web », mais prolifère sur le web ouvert et sur de nombreuses plateformes grand public. [En 2022](https://www.missingkids.org/content/dam/missingkids/pdfs/2022-reports-by- esp.pdf?ref=404media.co ), Facebook a signalé plus de 21 millions de cas d'exploitation sexuelle et d'exploitation sexuelle à la ligne d'information du Centre national pour les enfants disparus et exploités (NCMEC), tandis qu'Instagram a effectué 5 millions de signalements et Twitter en a signalé 98 050. Aux États-Unis, les fournisseurs de services électroniques [ESP] sont tenus par la loi de signaler la « pornographie juvénile apparente » au CyberTipline du NCMEC lorsque ils en prennent conscience, mais "il n'y a aucune exigence légale pour des efforts proactifs pour détecter ce contenu ou quelles informations un ESP doit inclure dans un rapport CyberTipline", selon le NCMEC. Un ensemble de données est toutefois différent d’un site Web, même s’il est composé de données provenant d’un grand nombre de sites Web. "Parce qu'il s'agit d'Internet, il y aura des ensembles de données contenant de la pédopornographie. Twitter l'a. Vous savez, Facebook l'a. Tout est là. Ils ne font pas un bon travail de surveillance, même s'ils prétendent " C'est ce qu'ils font. Et cela va maintenant être utilisé pour former ces modèles", a déclaré Marcus Rogers, vice-doyen pour les initiatives de cybersécurité à l'Université Purdue, à 404 Media. Cependant, les organisations qui créent des ensembles de données peuvent ignorer intentionnellement la possibilité que le CSAM puisse polluer leurs modèles, a-t-il déclaré. "Les entreprises ne veulent tout simplement pas savoir. Certaines d'entre elles le sont tout simplement, même si elles voulaient savoir, elles ont littéralement perdu le contrôle de tout." "Je pense que la raison pour laquelle ils l'ignorent probablement est qu'ils n'ont pas de solution", a déclaré à 404 Media Bryce Westlake, professeur agrégé au Département des études judiciaires et membre du corps professoral du programme de sciences médico-légales du département. "Donc, ils ne veulent pas attirer l'attention sur cela. Parce que s'ils attirent l'attention sur cela, alors quelque chose devra être fait à ce sujet." Les interventions que les créateurs d'ensembles de données pourraient faire nécessiteraient beaucoup de main d'œuvre, a-t-il déclaré, et même avec ces efforts en place, ils pourraient ne pas débarrasser les ensembles de tout cela, a-t-il déclaré. "Il leur est impossible de se débarrasser de tout cela. La seule réponse que la société acceptera est qu'il y a 0% là-dedans, et c'est impossible à faire. Ils sont dans une situation sans issue, alors ils pensent qu'il vaut mieux que les gens ne le savent tout simplement pas. » ### COMMENT LE CSAM DANS LES ENSEMBLES DE DONNÉES AFFECTE LES PERSONNES RÉELLES Dans un ensemble de données de cinq milliards d'entrées, 3 226 peuvent sembler une goutte dans un océan de données. Mais il existe plusieurs façons dont le CSAM intégré aux ensembles de données de LAION pourrait aggraver la situation des victimes réelles. Dan Sexton, directeur de la technologie à l'Internet Watch Foundation, basée au Royaume-Uni, m'a expliqué que l'objectif des groupes de sécurité sur Internet est d'empêcher davantage de personnes de consulter ou de diffuser des contenus abusifs et de les mettre complètement hors ligne. Nous avons parlé des mois avant la publication de l'article de Stanford, alors que nous n'étions pas sûrs que le matériel pédopornographique était récupéré dans de grands ensembles de données. "[Les victimes] sachant que leur contenu se trouve dans un ensemble de données qui permet à une machine de créer d'autres images --- qui ont appris de leurs abus --- ce n'est pas quelque chose que quiconque aurait pu s'attendre, mais ce n'est clairement pas le bienvenu. "Pour tout enfant qui a été maltraité et dont les images ont circulé, l'exclure partout sur Internet, y compris les ensembles de données, est énorme", a-t-il déclaré. > "Il n'y a aucune raison pour que des images d'enfants victimes d'abus sexuels figurent dans ces ensembles de données" Lloyd Richardson, directeur des technologies de l'information au Centre canadien de protection de l'enfance (C3P), m'a dit qu'il imaginait que les anciennes victimes d'abus sexuels sur enfants seraient « absolument dégoûtées, sans aucun doute, mais probablement pas nécessairement surprises » d'apprendre que leurs images sont liées. dans un ensemble de données comme LAION-5B. "Ils savent depuis si longtemps qu'ils doivent gérer leurs images ou leurs images et vidéos qui circulent sur Internet. Certaines choses techniques raisonnables qui pourraient être faites depuis plus d'une décennie, elles n'ont tout simplement pas été réalisées. c'est bien fait", a-t-il déclaré. "Je ne pense pas que quiconque veuille créer un outil qui crée des images d'enfants victimes d'abus sexuels, même si c'est accidentel", a déclaré Sexton. "L'IA consiste à disposer de bonnes données, et si vous y mettez de mauvaises données, vous en obtiendrez de mauvaises. Bien sûr, ce sont de mauvaises données. Vous ne voulez pas générer ou supprimer des images d'abus sexuels sur des enfants. " Jusqu'à présent, il a été théorisé que les modèles d'IA capables de créer des images d'abus sexuels sur des enfants combinaient des concepts de matériel explicite pour adultes et d'images non explicites d'enfants pour créer du CSAM généré par l'IA. Selon le rapport de Stanford, les images réelles d'abus aident à former des modèles. Les CSAM générés artificiellement sont en augmentation et peuvent potentiellement encombrer les lignes d'assistance téléphonique et dissuader les agences d'information qui travaillent avec les forces de l'ordre pour trouver les auteurs et les mettre hors ligne. L'Internet Watch Foundation [a récemment publié un rapport disant](https://www.iwf.org.uk/about-us/why-we-exist/our-research/how-ai-is-being-abused-to- create-child-sexual-abuse-imagery/?ref=404media.co ) que le CSAM AI est « visuellement impossible à distinguer du vrai CSAM », même pour les analystes qualifiés. Plus tôt ce mois-ci, une enquête de 404 Media a été trouvée, les personnes utilisant la populaire plateforme de génération d'images Civitai créaient ce qui "pourrait être considéré comme de la pornographie enfantine". Et en mai, le Centre national pour les enfants disparus et exploités, une organisation de défense des victimes qui gère une ligne d'assistance téléphonique pour signaler des abus sexuels, [a déclaré qu'il se préparait à une « inondation »](https://www.bloomberg.com/news/articles /2023-05-23/predators-exploit-ai-tools-to-depict-abuse-prompting-warnings?ref=404media.co ) de contenu généré artificiellement. Richardson m'a dit que les modèles de formation CSAM réels pourraient signifier des deepfakes abusifs plus réalistes des victimes. "Vous pourriez demander à un délinquant de télécharger Stable Diffusion, de créer une LoRA [Low-Rank Adaptation, a plus finement-tuned deep learning model] pour une victime spécifique et de commencer à générer de nouvelles images sur cette victime", a-t-il déclaré. Même si les abus de la victime remontent à longtemps et qu'elle est désormais adulte, "maintenant, de nouveaux contenus sont créés à son sujet sur la base du CSAM existant", a-t-il déclaré. "C'est donc extrêmement problématique." "Il n'y a aucune raison pour que des images d'enfants victimes d'abus sexuels figurent dans ces ensembles de données, à la fois pour être sûr que les modèles eux-mêmes ne créent pas de résultats indésirables, mais aussi pour que ces victimes s'assurent que leurs images ne soient pas continuellement et toujours utilisées à des fins malveillantes. à des fins nuisibles", a déclaré Sexton. OctoML, le moteur qui alimente Civitai, financé par a16z, pensait que les images pouvaient être qualifiées de « pornographie juvénile », mais a finalement décidé de continuer à travailler avec l'entreprise, les discussions internes de Slack et d'autres émissions matérielles. "Compte tenu de l'utilité de l'entraînement, vous ne pouvez pas affirmer que c'est comme avoir une copie d'Internet, donc vous allez avoir des éléments qui sont mauvais ou illégaux", a déclaré Thiel. "Vous l'opérationnalisez en entraînant les modèles sur ces choses. Et étant donné que vous avez des images qui se répéteront encore et encore dans cet ensemble de données, cela rend le modèle plus susceptible non seulement de représenter le matériau, mais vous auriez le potentiel de le faire." ressemblance avec des personnes réelles qui ont été introduites dans l'ensemble de données. ### QUI EST RESPONSABLE ? Légalement, il n’existe pas encore de précédent quant à savoir qui est responsable lorsqu’un outil de scraping collecte des images illégales. Comme Vencu l'a noté dans son message Discord en 2021, LAION diffuse des liens, pas de véritables copies d'images. "Puisque nous ne distribuons pas ou ne dérivons pas d'autres images à partir des originaux, je ne pense pas que la licence d'image s'applique", a-t-il déclaré dans Discord à la question de savoir si du matériel illégal se trouvait dans l'ensemble de données. La violation du droit d'auteur est une préoccupation majeure pour les artistes et les créateurs de contenu dont les images sont utilisées pour former des modèles d'IA. En avril, un photographe allemand [a demandé à LAION d'exclure ses photos de ses ensembles de données](https://www.vice.com/en/article/pkapb7/a-photographer-tried-to-get-his-photos-removed -from-an-ai-dataset-he-got-an-invoice-instead?ref=404media.co ), et LAION a répondu en lui facturant 979 $, affirmant qu'il avait déposé une réclamation injustifiée pour atteinte aux droits d'auteur. Plus tôt cette année, un groupe d'artistes a déposé un recours collectif contre Stability AI, DeviantArt et Midjourney pour leur utilisation du générateur d'images Stable Diffusion, qui utilise les ensembles de données de LAION. Et Getty Images a récemment poursuivi Stability AI , affirmant que l'entreprise avait copié plus de 12 millions d'images sans autorisation. "Nous avons des problèmes avec ces services, comment ils ont été construits, sur quoi ils ont été construits, comment ils respectent ou non les droits des créateurs, et comment ils alimentent réellement les deepfakes et d'autres choses comme ça", a déclaré Craig Peters, PDG de Getty Images, à Associated. Presse](https://apnews.com/article/getty-images-artificial-intelligence-ai-image-generator-stable-diffusion-a98eeaaeb2bf13c5e8874ceb6a8ce196?ref=404media.co). La diffusion de CSAM est un crime fédéral et les lois américaines à ce sujet sont extrêmement strictes. Il est bien sûr illégal de posséder ou de transmettre des fichiers, mais « les films non développés, les bandes vidéo non développées et les données stockées électroniquement qui peuvent être converties en une image visuelle de pédopornographie » sont également illégales [en vertu de la loi fédérale](https://www. justice.gov/criminal/criminal-ceos/citizens-guide-us-federal-law-child-pornography?ref=404media.co). Il n’est pas clair où les URL renvoyant à des images d’exploitation d’enfants aboutiraient en vertu des lois actuelles, ni à quel moment toute personne utilisant ces ensembles de données pourrait potentiellement être en danger juridique. Parce que les lois anti-CSAM sont naturellement si strictes, les chercheurs ont dû trouver de nouvelles façons d’étudier sa propagation sans enfreindre eux-mêmes la loi. Westlake m'a dit qu'il comptait confier certaines recherches à des collègues au Canada, comme le C3P, pour vérifier ou nettoyer les données, là où il existe des lois CSAM qui prévoient des exceptions à des fins de recherche. Stanford a également envoyé sa méthodologie au C3P pour vérification. L'Internet Watch Foundation a un protocole d'accord qui lui a été accordé par le Crown Prosecution Service, la principale agence publique de poursuite pénale au Royaume-Uni, pour télécharger, visualiser et conserver du contenu dans le cadre de ses fonctions, ce qui lui permet de rechercher de manière proactive des contenus abusifs et signalez-le aux autorités. Aux États-Unis, visionner, rechercher ou posséder du matériel sur l’exploitation des enfants, même accidentellement, constitue un crime fédéral. > "Les lieux ne devraient plus héberger ces ensembles de données à télécharger." Rogers et sa collègue Kathryn Seigfried-Spellar du département médico-légal de Purdue se trouvent dans une situation unique : ils sont suppléés et bénéficient du statut d'application de la loi qui leur est accordé par les forces de l'ordre locales pour faire leur travail. Ils disposent d’un espace physique dans un établissement sécurisé des forces de l’ordre, avec des caméras de surveillance, des porte-clés, un réseau sécurisé et une identification à 12 facteurs où ils doivent se rendre s’ils souhaitent effectuer des tâches telles que nettoyer des ensembles de données ou consulter des CSAM à des fins de recherche ou d’enquête. Malgré tout, ils font extrêmement attention à ce qu’ils collectent avec des outils de grattage. Siegfried-Spellar m'a dit qu'elle travaillait sur l'étude des jointures et des mains parce qu'elles apparaissent souvent dans les images d'abus et sont aussi identifiables que des visages, et qu'elle pourrait récupérer des images des forums NSFW Reddit où les gens publient des images d'eux-mêmes en train de se masturber, mais elle ne le fait pas à cause du risque d’attraper des images de mineurs sur le net. "Même s'il faut avoir plus de 18 ans pour utiliser Reddit, je ne vais jamais récupérer ces données et les utiliser, ni les analyser pour mes recherches, car je ne peux pas vérifier que quelqu'un a vraiment dépassé l'âge de 18 ans. sur 18 qui ont posté cela", a-t-elle déclaré. "Il y a eu des discussions à ce sujet également : 'il y a des images sur Internet, pourquoi ne puis-je pas simplement les gratter et les utiliser pour mon entraînement aux algorithmes ?' Mais c'est parce que j'ai besoin de connaître l'âge des sources." ### QUE FAIRE MAINTENANT Parce que LAION-5B est open-source, de nombreuses copies circulent publiquement, y compris sur Hugging Face. Supprimer l'ensemble de données de Hugging Face, extraire les liens CSAM vers des images abusives de l'ensemble de données, puis le télécharger à nouveau, par exemple, créerait essentiellement une feuille de route pour une personne déterminée à afficher ces fichiers en comparant les différences entre les deux. Thiel m'a dit qu'il s'était lancé dans cette étude en pensant que l'objectif pourrait être d'extraire des éléments abusifs des ensembles de données, mais il pense maintenant qu'il est trop tard. "Maintenant, je suis plutôt d'avis que [les ensembles de données LAION] ont juste besoin d'être effacés", a-t-il déclaré. "Les endroits ne devraient plus héberger ces ensembles de données pour le téléchargement. Il y a peut-être un argument en faveur d'en conserver des copies pour des raisons de recherche, puis vous pourrez les parcourir et prendre quelques mesures pour les nettoyer." Il existe un précédent à ce sujet, notamment en ce qui concerne les données sur les enfants. La Federal Trade Commission a un terme pour la suppression de modèles afin de contrôler les dommages : le dégorgement de l'algorithme. En tant que stratégie d'application de la loi, la FTC a eu recours à la restitution d'algorithmes dans cinq cas impliquant des partenaires technologiques qui ont construit des modèles à partir de données obtenues de manière inappropriée, y compris [un règlement avec Amazon en mai](https://www.ftc.gov/news-events/ news/press-releases/2023/05/ftc-doj-charge-amazon-violating-childrens-privacy-law-keeping-kids-alexa-voice-recordings-forever?ref=404media.co ) concernant les accusations liées aux enregistrements vocaux d'Alexa violé la vie privée des enfants, et un règlement entre la FTC et le ministère de la Justice et une application de perte de poids pour enfants qui [n'aurait pas réussi à vérifier correctement](https://cyberscoop.com/ftc-settlement-ww-weight-watchers-kurbo-children -prvacy/?ref=404media.co ) consentement parental. Les deux affaires invoquaient la loi sur la protection de la vie privée en ligne des enfants (COPPA). La sécurité des enfants et l’IA deviennent rapidement le prochain champ de bataille majeur d’Internet. En avril, le sénateur démocrate Dick Durbin [a présenté la loi « STOP CSAM Act](https://www.judiciary.senate.gov/press/dem/releases/durbin-introduces-stop-csam-act-to-crack-down- on-the-prolifération-of-child-sex-abuse-material-online?ref=404media.co )", ce qui érigerait en infraction le fait pour les fournisseurs d'"héberger ou stocker sciemment" des contenus pédopornographiques ou de "promouvoir ou faciliter sciemment" le l'exploitation sexuelle des enfants, créer un nouveau crime fédéral pour les services en ligne qui « favorisent ou facilitent sciemment » les crimes d'exploitation des enfants, et modifier l'article 230 --- la loi qui protège les plateformes de toute responsabilité pour les actions de leurs utilisateurs --- pour permettre des poursuites civiles. poursuites intentées par des victimes de crimes d’exploitation d’enfants contre des fournisseurs de services en ligne. Des défenseurs de la vie privée, notamment l'[Electronic Frontier Foundation](https://www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media. co ) et le [Centre pour la démocratie et la technologie](https://cdt.org/insights/the-stop-csam-act-threatens-free-expression-and-privacy-rights-of-children-and-adults/ ?ref=404media.co ) s'opposent à cette loi, avertissant qu'elle pourrait nuire aux services de chiffrement de bout en bout. L’inclusion des contenus CSAM « apparents » élargit trop le champ, disent-ils, et les termes « promouvoir » et « faciliter » sont trop larges. Cela pourrait également avoir un effet dissuasif sur la liberté d'expression en général : "Les contenus protégés par le premier amendement impliquant la sexualité, l'orientation sexuelle ou l'identité de genre seront probablement la cible d'avis de retrait frivoles", [ont écrit les avocats et les experts en surveillance de l'EFF](https:// www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media.co ) dans un article de blog. En septembre, les procureurs généraux de 50 États ont appelé les législateurs fédéraux à étudier comment l’exploitation basée sur l’IA peut mettre les enfants en danger. "Nous sommes engagés dans une course contre la montre pour protéger les enfants de notre pays des dangers de l'IA", [ont écrit les procureurs](https://apnews.com/article/ai-child-pornography-attorneys-general-bc7f9384d469b061d603d6ba9748f38a ?ref=404media.co ). "En effet, les murs de la ville ont déjà été brisés. Il est maintenant temps d'agir." Thiel a déclaré qu'il n'avait pas communiqué avec LAION avant la publication de l'étude. "Nous n'entendons pas cela comme une sorte de piège pour les parties impliquées. Mais évidemment, de nombreuses erreurs très importantes ont été commises dans diverses parties de l'ensemble de ce pipeline", a-t-il déclaré. "Et ce n'est vraiment pas du tout la façon dont la formation des modèles à l'avenir devrait fonctionner." Tout cela est un problème qui ne disparaîtra pas, même – ou surtout – s’il est ignoré. "Ils ont tous d'énormes problèmes liés au vol massif de données, aux images intimes non consensuelles, au matériel d'abus sexuels sur des enfants, vous l'appelez, c'est là. Je suis un peu perplexe de voir comment cela a duré aussi longtemps", a déclaré Richardson. "Ce n'est pas que la technologie soit nécessairement mauvaise... ce n'est pas que l'IA soit mauvaise. C'est le fait qu'un tas de choses ont été volées aveuglément, et maintenant nous essayons de mettre tous ces pansements pour réparer quelque chose qui n'a vraiment jamais été fait. Cela aurait dû arriver en premier lieu. » Devenez abonné payant pour des articles illimités et sans publicité et un accès au contenu bonus. Ce site est financé par les abonnés et vous alimenterez directement notre journalisme. *Mise à jour du 20 décembre à 8 h 19 HNE : ce titre a été modifié pour supprimer le mot " suspecté" car 1 008 entrées ont été validées en externe. * *Mise à jour du 20/12, 11 h 20 HNE : cette histoire a été corrigée pour refléter l'incapacité de Common Crawl à explorer Twitter, Instagram et Facebook. * Mise à jour du 20/12, 13h32 EST avec commentaire de Google sur son utilisation des produits LAION. Cette histoire a été corrigée pour refléter le fait que Google a formé Imagen sur un sous-ensemble (et une version antérieure) de LAION-5B appelé LAION-400M. Ses produits actuels n'utilisent pas les ensembles de données LAION. Cet article a également été mis à jour avec les commentaires de Stability AI.
](https://www.404media.co/content/images/2023/12/laion_discord_1 -1.png) CAPTURE D'ÉCRAN VIA LAION DISCORD La plupart des institutions aux États-Unis, y compris l'équipe de Thiel, ne sont pas légalement autorisées à visualiser le CSAM afin de le vérifier elles-mêmes. Pour effectuer des recherches CSAM, les experts s'appuient souvent sur le hachage perceptuel, qui extrait une signature numérique unique ou une empreinte digitale. , à partir d'une image ou d'une vidéo. PhotoDNA est une technologie qui crée des hachages uniques pour les images d'exploitation d'enfants afin de retrouver ces images ailleurs sur le Web et de les faire supprimer ou de poursuivre les agresseurs ou les proliférateurs. "Dans le but de quantifier le degré de présence du CSAM dans l'ensemble de données d'entraînement ainsi que de l'éliminer des ensembles de données LAION-5B et dérivés, nous utilisons diverses techniques complémentaires pour identifier le CSAM potentiel dans l'ensemble de données : détection basée sur le hachage perceptuel, détection cryptographique basée sur le hachage et analyse des voisins les plus proches exploitant les intégrations d'images dans l'ensemble de données lui-même », indique le document. Grâce à ce processus, ils ont identifié au moins 2 000 entrées d’ensembles de données suspectées de CSAM et ont confirmé ces entrées auprès de tiers. Pour faire ses recherches, Thiel a déclaré qu'il s'était concentré sur les URL identifiées par le classificateur de sécurité de LAION comme « non sûres pour le travail » et avait envoyé ces URL à PhotoDNA. Les correspondances de hachage indiquent un CSAM certain et connu et ont été envoyées à l'API du projet Arachnid Shield et validées par le Centre canadien de protection de l'enfance, qui est en mesure de visualiser, vérifier et signaler ces images aux autorités. Une fois ces images vérifiées, ils ont également pu trouver des correspondances de « voisin le plus proche » dans l'ensemble de données, où les images associées des victimes étaient regroupées. LAION aurait pu utiliser une méthode similaire à celle-ci avant de publier le plus grand ensemble de données de formation à l'IA au monde, a déclaré Thiel, mais ce n'est pas le cas. "[LAION] a initialement utilisé CLIP pour essayer de filtrer certaines choses, mais il ne semble pas qu'ils l'aient fait en consultation avec des experts en sécurité des enfants au départ. C'était bien qu'ils aient essayé. Mais les mécanismes qu'ils ont utilisés n'étaient tout simplement pas super. impressionnant", a déclaré Thiel. "Ils ont fait une tentative qui était loin d'être suffisante, et ce n'est pas ainsi que je l'aurais fait si j'avais essayé de concevoir un système sûr." Un porte-parole de LAION a déclaré à 404 Media dans une déclaration à propos de l'article de Stanford : *"LAION est une organisation à but non lucratif qui fournit des ensembles de données, des outils et des modèles pour l'avancement de la recherche sur l'apprentissage automatique. Nous nous engageons en faveur d'une éducation publique ouverte et d'une protection de l'environnement. utilisation des ressources grâce à la réutilisation d'ensembles de données et de modèles existants. Les ensembles de données LAION (plus de 5,85 milliards d'entrées) proviennent de l'index Web Common Crawl disponible gratuitement et offrent uniquement des liens vers du contenu sur le Web public, sans images. Nous avons développé et publié nos propres filtres rigoureux pour détecter et supprimer le contenu illégal des ensembles de données LAION avant de les publier. Nous collaborons avec des universités, des chercheurs et des ONG pour améliorer ces filtres et travaillons actuellement avec l'Internet Watch Foundation (IWF) pour identifier et supprimer les contenus soupçonnés de violer les lois. . Nous invitons les chercheurs de Stanford à rejoindre LAION pour améliorer nos ensembles de données et développer des filtres efficaces pour détecter les contenus préjudiciables. LAION a une politique de tolérance zéro pour les contenus illégaux et, par prudence, nous supprimons temporairement les ensembles de données LAION pour nous assurer qu'ils sont en sécurité avant de les republier. qui a examiné le paysage des modèles génératifs visuels qui pourraient être utilisés pour créer du CSAM. Thiel m'a dit qu'il avait continué à approfondir le sujet après un conseil du chercheur en IA Alex Champandard, [qui a trouvé l'URL d'une image dans LAION-5B](https://huggingface.co/datasets/laion/laion2B-multi/discussions/ 3?ref=404media.co ) sur Hugging Face qui était sous-titré avec une phrase en espagnol qui semblait décrire du matériel d'exploitation des enfants. LAION-5B est disponible en téléchargement sur Hugging Face en tant qu'outil open source. Champandard m'a dit il a remarqué un rapport à Hugging Face sur LAION-5B en août 2022, signalant « un exemple qui décrit quelque chose lié à la pédophilie. L'un des ingénieurs qui ont travaillé sur LAION-5B a répondu en mars 2023, affirmant que le lien était mort mais qu'ils l'avaient quand même supprimé car la légende était inappropriée. "Il a fallu 7 mois pour que ce rapport soit traité par Hugging Face ou LAION --- ce que j'ai trouvé très discutable", a déclaré Champandard. [](https://lh7-us.googleusercontent.com/JvxvXAe7vYRGQl8fGb0lPy3X7uzqGL1NAuxzKRcoZ_0TGSxQRn7eCBjRBS7Pz0Vx0YSAHhrxbGVyBq6KjCbkY3-GscWVLHw8 TMJVd6qHiqHQufPz5YBG9DzVJ24-oiBeEVZU49AN-_RyYbWgScWayEo) Suite aux tweets de Champandard , Margaret Mitchell, scientifique en chef de l'éthique chez Hugging Face a écrit sur Mastodon : "Je voulais juste intervenir pour dire qu'il y a eu beaucoup de du temps et de l'énergie consacrés à essayer de trouver des CSAM, et aucun n'a été trouvé. Certaines personnes de HF sont attaquées comme s'il s'agissait de pédophiles, mais c'est juste... une cruauté inappropriée. J'ai demandé à Hugging Face si, à la lumière de cette étude et avant que LAION ne supprime lui-même les ensembles de données, il prendrait des mesures contre les datasts qui auraient des liens avec CSAM. Un porte-parole de l'entreprise a répondu : « Oui ». "Les ensembles de données ne peuvent pas être vus par le personnel de Hugging Face (ni par toute personne accédant au Hub) jusqu'à ce qu'ils soient téléchargés, et celui qui télécharge peut décider de rendre le contenu public. Une fois partagé, la plateforme effectue une analyse du contenu pour identifier les problèmes potentiels. Les utilisateurs sont responsables du téléchargement. et maintenir le contenu, et le personnel résout les problèmes en suivant les directives de contenu de la plateforme Hugging Face, que nous continuons à [adapter](https://huggingface .co/blog/content-guidelines-update?ref=404media.co ). La plate-forme s'appuie sur une combinaison d'analyse de contenu technique pour valider que les directives sont effectivement suivies, de modération de la communauté et de fonctionnalités de reporting pour permettre aux utilisateurs de faire part de leurs préoccupations. Nous surveillons les signalements et prenons des mesures lorsqu'un contenu en infraction est signalé", a déclaré le porte-parole de Hugging Face. « Il est essentiel pour cette discussion de noter que l'ensemble de données LAION-5B contient des URL vers du contenu externe, et non des images, ce qui pose des défis supplémentaires. Nous travaillons avec la société civile et les partenaires industriels pour développer de bonnes pratiques pour gérer ce type de questions multiplateformes. " L'article de Stanford indique que le matériel détecté au cours de leur processus est « intrinsèquement un sous-dénombrement important en raison du caractère incomplet des ensembles de hachage de l'industrie, de l'attrition du contenu hébergé en direct, du manque d'accès aux ensembles d'images de référence LAION d'origine et de la précision limitée des informations « dangereuses ». 'classificateurs de contenu." Plusieurs grandes sociétés d'IA générative, Stable Diffusion, utilisent LAION-5B, tandis que d'autres ont utilisé les produits de LAION à différents stades de développement. "Les ensembles de données LAION ont également été utilisés pour entraîner d'autres modèles, tels que Imagen de Google, qui a été formé sur une combinaison d'ensembles de données internes et de LAION-400M", indique l'article de Stanford. « Notamment, lors d'un audit du LAION-400M, les développeurs d'Imagen ont découvert « un large éventail de contenus inappropriés, notamment des images pornographiques, des insultes racistes et des stéréotypes sociaux préjudiciables », et les ont jugés impropres à un usage public. Suite à la publication de l'article, un porte-parole de Google a déclaré à 404 Media : « Imagen n'a jamais utilisé LAION-5B. Plus précisément, LAION-400M a été utilisé uniquement pour entraîner le premier modèle de recherche Imagen, qui n'a jamais été publié. Aucune des itérations suivantes de le modèle utilise n'importe quelle version des ensembles de données LAION. 400-M a également été supprimé par LAION, par « excès de prudence » concernant les conclusions du document. Un porte-parole de Stable Diffusion a déclaré à 404 Media après la publication de l'article : « Stable Diffusion 1.5 a été publié par RunwayML, et non par Stability AI. Ce rapport se concentre sur l'ensemble de données LAION-5b dans son ensemble. Les modèles d'IA de stabilité ont été formés sur un sous-ensemble filtré de cet ensemble de données. En outre, nous avons ensuite affiné ces modèles pour atténuer les comportements résiduels. Nous nous engageons à prévenir l’utilisation abusive de l’IA et à interdire l’utilisation de nos modèles d’image et de nos services à des fins d’activités illégales, y compris les tentatives de modification ou de création de CSAM. AI héberge uniquement les versions de Stable Diffusion qui incluent des filtres sur son API. Ces filtres empêchent le contenu dangereux d'atteindre les modèles. En supprimant ce contenu avant qu'il n'atteigne le modèle, nous pouvons aider à empêcher le modèle de générer du contenu dangereux. De plus, nous Nous avons mis en œuvre des filtres pour intercepter les invites ou les sorties dangereuses lorsque les utilisateurs interagissent avec des modèles sur notre plateforme. Nous avons également investi dans des fonctionnalités d'étiquetage de contenu pour aider à identifier les images générées sur notre plateforme. Ces niveaux d'atténuation rendent plus difficile l'utilisation abusive de l'IA par les acteurs malveillants. le domaine du « dark web », mais prolifère sur le web ouvert et sur de nombreuses plateformes grand public. [En 2022](https://www.missingkids.org/content/dam/missingkids/pdfs/2022-reports-by- esp.pdf?ref=404media.co ), Facebook a signalé plus de 21 millions de cas d'exploitation sexuelle et d'exploitation sexuelle à la ligne d'information du Centre national pour les enfants disparus et exploités (NCMEC), tandis qu'Instagram a effectué 5 millions de signalements et Twitter en a signalé 98 050. Aux États-Unis, les fournisseurs de services électroniques [ESP] sont tenus par la loi de signaler la « pornographie juvénile apparente » au CyberTipline du NCMEC lorsque ils en prennent conscience, mais "il n'y a aucune exigence légale pour des efforts proactifs pour détecter ce contenu ou quelles informations un ESP doit inclure dans un rapport CyberTipline", selon le NCMEC. Un ensemble de données est toutefois différent d’un site Web, même s’il est composé de données provenant d’un grand nombre de sites Web. "Parce qu'il s'agit d'Internet, il y aura des ensembles de données contenant de la pédopornographie. Twitter l'a. Vous savez, Facebook l'a. Tout est là. Ils ne font pas un bon travail de surveillance, même s'ils prétendent " C'est ce qu'ils font. Et cela va maintenant être utilisé pour former ces modèles", a déclaré Marcus Rogers, vice-doyen pour les initiatives de cybersécurité à l'Université Purdue, à 404 Media. Cependant, les organisations qui créent des ensembles de données peuvent ignorer intentionnellement la possibilité que le CSAM puisse polluer leurs modèles, a-t-il déclaré. "Les entreprises ne veulent tout simplement pas savoir. Certaines d'entre elles le sont tout simplement, même si elles voulaient savoir, elles ont littéralement perdu le contrôle de tout." "Je pense que la raison pour laquelle ils l'ignorent probablement est qu'ils n'ont pas de solution", a déclaré à 404 Media Bryce Westlake, professeur agrégé au Département des études judiciaires et membre du corps professoral du programme de sciences médico-légales du département. "Donc, ils ne veulent pas attirer l'attention sur cela. Parce que s'ils attirent l'attention sur cela, alors quelque chose devra être fait à ce sujet." Les interventions que les créateurs d'ensembles de données pourraient faire nécessiteraient beaucoup de main d'œuvre, a-t-il déclaré, et même avec ces efforts en place, ils pourraient ne pas débarrasser les ensembles de tout cela, a-t-il déclaré. "Il leur est impossible de se débarrasser de tout cela. La seule réponse que la société acceptera est qu'il y a 0% là-dedans, et c'est impossible à faire. Ils sont dans une situation sans issue, alors ils pensent qu'il vaut mieux que les gens ne le savent tout simplement pas. » ### COMMENT LE CSAM DANS LES ENSEMBLES DE DONNÉES AFFECTE LES PERSONNES RÉELLES Dans un ensemble de données de cinq milliards d'entrées, 3 226 peuvent sembler une goutte dans un océan de données. Mais il existe plusieurs façons dont le CSAM intégré aux ensembles de données de LAION pourrait aggraver la situation des victimes réelles. Dan Sexton, directeur de la technologie à l'Internet Watch Foundation, basée au Royaume-Uni, m'a expliqué que l'objectif des groupes de sécurité sur Internet est d'empêcher davantage de personnes de consulter ou de diffuser des contenus abusifs et de les mettre complètement hors ligne. Nous avons parlé des mois avant la publication de l'article de Stanford, alors que nous n'étions pas sûrs que le matériel pédopornographique était récupéré dans de grands ensembles de données. "[Les victimes] sachant que leur contenu se trouve dans un ensemble de données qui permet à une machine de créer d'autres images --- qui ont appris de leurs abus --- ce n'est pas quelque chose que quiconque aurait pu s'attendre, mais ce n'est clairement pas le bienvenu. "Pour tout enfant qui a été maltraité et dont les images ont circulé, l'exclure partout sur Internet, y compris les ensembles de données, est énorme", a-t-il déclaré. > "Il n'y a aucune raison pour que des images d'enfants victimes d'abus sexuels figurent dans ces ensembles de données" Lloyd Richardson, directeur des technologies de l'information au Centre canadien de protection de l'enfance (C3P), m'a dit qu'il imaginait que les anciennes victimes d'abus sexuels sur enfants seraient « absolument dégoûtées, sans aucun doute, mais probablement pas nécessairement surprises » d'apprendre que leurs images sont liées. dans un ensemble de données comme LAION-5B. "Ils savent depuis si longtemps qu'ils doivent gérer leurs images ou leurs images et vidéos qui circulent sur Internet. Certaines choses techniques raisonnables qui pourraient être faites depuis plus d'une décennie, elles n'ont tout simplement pas été réalisées. c'est bien fait", a-t-il déclaré. "Je ne pense pas que quiconque veuille créer un outil qui crée des images d'enfants victimes d'abus sexuels, même si c'est accidentel", a déclaré Sexton. "L'IA consiste à disposer de bonnes données, et si vous y mettez de mauvaises données, vous en obtiendrez de mauvaises. Bien sûr, ce sont de mauvaises données. Vous ne voulez pas générer ou supprimer des images d'abus sexuels sur des enfants. " Jusqu'à présent, il a été théorisé que les modèles d'IA capables de créer des images d'abus sexuels sur des enfants combinaient des concepts de matériel explicite pour adultes et d'images non explicites d'enfants pour créer du CSAM généré par l'IA. Selon le rapport de Stanford, les images réelles d'abus aident à former des modèles. Les CSAM générés artificiellement sont en augmentation et peuvent potentiellement encombrer les lignes d'assistance téléphonique et dissuader les agences d'information qui travaillent avec les forces de l'ordre pour trouver les auteurs et les mettre hors ligne. L'Internet Watch Foundation [a récemment publié un rapport disant](https://www.iwf.org.uk/about-us/why-we-exist/our-research/how-ai-is-being-abused-to- create-child-sexual-abuse-imagery/?ref=404media.co ) que le CSAM AI est « visuellement impossible à distinguer du vrai CSAM », même pour les analystes qualifiés. Plus tôt ce mois-ci, une enquête de 404 Media a été trouvée, les personnes utilisant la populaire plateforme de génération d'images Civitai créaient ce qui "pourrait être considéré comme de la pornographie enfantine". Et en mai, le Centre national pour les enfants disparus et exploités, une organisation de défense des victimes qui gère une ligne d'assistance téléphonique pour signaler des abus sexuels, [a déclaré qu'il se préparait à une « inondation »](https://www.bloomberg.com/news/articles /2023-05-23/predators-exploit-ai-tools-to-depict-abuse-prompting-warnings?ref=404media.co ) de contenu généré artificiellement. Richardson m'a dit que les modèles de formation CSAM réels pourraient signifier des deepfakes abusifs plus réalistes des victimes. "Vous pourriez demander à un délinquant de télécharger Stable Diffusion, de créer une LoRA [Low-Rank Adaptation, a plus finement-tuned deep learning model] pour une victime spécifique et de commencer à générer de nouvelles images sur cette victime", a-t-il déclaré. Même si les abus de la victime remontent à longtemps et qu'elle est désormais adulte, "maintenant, de nouveaux contenus sont créés à son sujet sur la base du CSAM existant", a-t-il déclaré. "C'est donc extrêmement problématique." "Il n'y a aucune raison pour que des images d'enfants victimes d'abus sexuels figurent dans ces ensembles de données, à la fois pour être sûr que les modèles eux-mêmes ne créent pas de résultats indésirables, mais aussi pour que ces victimes s'assurent que leurs images ne soient pas continuellement et toujours utilisées à des fins malveillantes. à des fins nuisibles", a déclaré Sexton. OctoML, le moteur qui alimente Civitai, financé par a16z, pensait que les images pouvaient être qualifiées de « pornographie juvénile », mais a finalement décidé de continuer à travailler avec l'entreprise, les discussions internes de Slack et d'autres émissions matérielles. "Compte tenu de l'utilité de l'entraînement, vous ne pouvez pas affirmer que c'est comme avoir une copie d'Internet, donc vous allez avoir des éléments qui sont mauvais ou illégaux", a déclaré Thiel. "Vous l'opérationnalisez en entraînant les modèles sur ces choses. Et étant donné que vous avez des images qui se répéteront encore et encore dans cet ensemble de données, cela rend le modèle plus susceptible non seulement de représenter le matériau, mais vous auriez le potentiel de le faire." ressemblance avec des personnes réelles qui ont été introduites dans l'ensemble de données. ### QUI EST RESPONSABLE ? Légalement, il n’existe pas encore de précédent quant à savoir qui est responsable lorsqu’un outil de scraping collecte des images illégales. Comme Vencu l'a noté dans son message Discord en 2021, LAION diffuse des liens, pas de véritables copies d'images. "Puisque nous ne distribuons pas ou ne dérivons pas d'autres images à partir des originaux, je ne pense pas que la licence d'image s'applique", a-t-il déclaré dans Discord à la question de savoir si du matériel illégal se trouvait dans l'ensemble de données. La violation du droit d'auteur est une préoccupation majeure pour les artistes et les créateurs de contenu dont les images sont utilisées pour former des modèles d'IA. En avril, un photographe allemand [a demandé à LAION d'exclure ses photos de ses ensembles de données](https://www.vice.com/en/article/pkapb7/a-photographer-tried-to-get-his-photos-removed -from-an-ai-dataset-he-got-an-invoice-instead?ref=404media.co ), et LAION a répondu en lui facturant 979 $, affirmant qu'il avait déposé une réclamation injustifiée pour atteinte aux droits d'auteur. Plus tôt cette année, un groupe d'artistes a déposé un recours collectif contre Stability AI, DeviantArt et Midjourney pour leur utilisation du générateur d'images Stable Diffusion, qui utilise les ensembles de données de LAION. Et Getty Images a récemment poursuivi Stability AI , affirmant que l'entreprise avait copié plus de 12 millions d'images sans autorisation. "Nous avons des problèmes avec ces services, comment ils ont été construits, sur quoi ils ont été construits, comment ils respectent ou non les droits des créateurs, et comment ils alimentent réellement les deepfakes et d'autres choses comme ça", a déclaré Craig Peters, PDG de Getty Images, à Associated. Presse](https://apnews.com/article/getty-images-artificial-intelligence-ai-image-generator-stable-diffusion-a98eeaaeb2bf13c5e8874ceb6a8ce196?ref=404media.co). La diffusion de CSAM est un crime fédéral et les lois américaines à ce sujet sont extrêmement strictes. Il est bien sûr illégal de posséder ou de transmettre des fichiers, mais « les films non développés, les bandes vidéo non développées et les données stockées électroniquement qui peuvent être converties en une image visuelle de pédopornographie » sont également illégales [en vertu de la loi fédérale](https://www. justice.gov/criminal/criminal-ceos/citizens-guide-us-federal-law-child-pornography?ref=404media.co). Il n’est pas clair où les URL renvoyant à des images d’exploitation d’enfants aboutiraient en vertu des lois actuelles, ni à quel moment toute personne utilisant ces ensembles de données pourrait potentiellement être en danger juridique. Parce que les lois anti-CSAM sont naturellement si strictes, les chercheurs ont dû trouver de nouvelles façons d’étudier sa propagation sans enfreindre eux-mêmes la loi. Westlake m'a dit qu'il comptait confier certaines recherches à des collègues au Canada, comme le C3P, pour vérifier ou nettoyer les données, là où il existe des lois CSAM qui prévoient des exceptions à des fins de recherche. Stanford a également envoyé sa méthodologie au C3P pour vérification. L'Internet Watch Foundation a un protocole d'accord qui lui a été accordé par le Crown Prosecution Service, la principale agence publique de poursuite pénale au Royaume-Uni, pour télécharger, visualiser et conserver du contenu dans le cadre de ses fonctions, ce qui lui permet de rechercher de manière proactive des contenus abusifs et signalez-le aux autorités. Aux États-Unis, visionner, rechercher ou posséder du matériel sur l’exploitation des enfants, même accidentellement, constitue un crime fédéral. > "Les lieux ne devraient plus héberger ces ensembles de données à télécharger." Rogers et sa collègue Kathryn Seigfried-Spellar du département médico-légal de Purdue se trouvent dans une situation unique : ils sont suppléés et bénéficient du statut d'application de la loi qui leur est accordé par les forces de l'ordre locales pour faire leur travail. Ils disposent d’un espace physique dans un établissement sécurisé des forces de l’ordre, avec des caméras de surveillance, des porte-clés, un réseau sécurisé et une identification à 12 facteurs où ils doivent se rendre s’ils souhaitent effectuer des tâches telles que nettoyer des ensembles de données ou consulter des CSAM à des fins de recherche ou d’enquête. Malgré tout, ils font extrêmement attention à ce qu’ils collectent avec des outils de grattage. Siegfried-Spellar m'a dit qu'elle travaillait sur l'étude des jointures et des mains parce qu'elles apparaissent souvent dans les images d'abus et sont aussi identifiables que des visages, et qu'elle pourrait récupérer des images des forums NSFW Reddit où les gens publient des images d'eux-mêmes en train de se masturber, mais elle ne le fait pas à cause du risque d’attraper des images de mineurs sur le net. "Même s'il faut avoir plus de 18 ans pour utiliser Reddit, je ne vais jamais récupérer ces données et les utiliser, ni les analyser pour mes recherches, car je ne peux pas vérifier que quelqu'un a vraiment dépassé l'âge de 18 ans. sur 18 qui ont posté cela", a-t-elle déclaré. "Il y a eu des discussions à ce sujet également : 'il y a des images sur Internet, pourquoi ne puis-je pas simplement les gratter et les utiliser pour mon entraînement aux algorithmes ?' Mais c'est parce que j'ai besoin de connaître l'âge des sources." ### QUE FAIRE MAINTENANT Parce que LAION-5B est open-source, de nombreuses copies circulent publiquement, y compris sur Hugging Face. Supprimer l'ensemble de données de Hugging Face, extraire les liens CSAM vers des images abusives de l'ensemble de données, puis le télécharger à nouveau, par exemple, créerait essentiellement une feuille de route pour une personne déterminée à afficher ces fichiers en comparant les différences entre les deux. Thiel m'a dit qu'il s'était lancé dans cette étude en pensant que l'objectif pourrait être d'extraire des éléments abusifs des ensembles de données, mais il pense maintenant qu'il est trop tard. "Maintenant, je suis plutôt d'avis que [les ensembles de données LAION] ont juste besoin d'être effacés", a-t-il déclaré. "Les endroits ne devraient plus héberger ces ensembles de données pour le téléchargement. Il y a peut-être un argument en faveur d'en conserver des copies pour des raisons de recherche, puis vous pourrez les parcourir et prendre quelques mesures pour les nettoyer." Il existe un précédent à ce sujet, notamment en ce qui concerne les données sur les enfants. La Federal Trade Commission a un terme pour la suppression de modèles afin de contrôler les dommages : le dégorgement de l'algorithme. En tant que stratégie d'application de la loi, la FTC a eu recours à la restitution d'algorithmes dans cinq cas impliquant des partenaires technologiques qui ont construit des modèles à partir de données obtenues de manière inappropriée, y compris [un règlement avec Amazon en mai](https://www.ftc.gov/news-events/ news/press-releases/2023/05/ftc-doj-charge-amazon-violating-childrens-privacy-law-keeping-kids-alexa-voice-recordings-forever?ref=404media.co ) concernant les accusations liées aux enregistrements vocaux d'Alexa violé la vie privée des enfants, et un règlement entre la FTC et le ministère de la Justice et une application de perte de poids pour enfants qui [n'aurait pas réussi à vérifier correctement](https://cyberscoop.com/ftc-settlement-ww-weight-watchers-kurbo-children -prvacy/?ref=404media.co ) consentement parental. Les deux affaires invoquaient la loi sur la protection de la vie privée en ligne des enfants (COPPA). La sécurité des enfants et l’IA deviennent rapidement le prochain champ de bataille majeur d’Internet. En avril, le sénateur démocrate Dick Durbin [a présenté la loi « STOP CSAM Act](https://www.judiciary.senate.gov/press/dem/releases/durbin-introduces-stop-csam-act-to-crack-down- on-the-prolifération-of-child-sex-abuse-material-online?ref=404media.co )", ce qui érigerait en infraction le fait pour les fournisseurs d'"héberger ou stocker sciemment" des contenus pédopornographiques ou de "promouvoir ou faciliter sciemment" le l'exploitation sexuelle des enfants, créer un nouveau crime fédéral pour les services en ligne qui « favorisent ou facilitent sciemment » les crimes d'exploitation des enfants, et modifier l'article 230 --- la loi qui protège les plateformes de toute responsabilité pour les actions de leurs utilisateurs --- pour permettre des poursuites civiles. poursuites intentées par des victimes de crimes d’exploitation d’enfants contre des fournisseurs de services en ligne. Des défenseurs de la vie privée, notamment l'[Electronic Frontier Foundation](https://www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media. co ) et le [Centre pour la démocratie et la technologie](https://cdt.org/insights/the-stop-csam-act-threatens-free-expression-and-privacy-rights-of-children-and-adults/ ?ref=404media.co ) s'opposent à cette loi, avertissant qu'elle pourrait nuire aux services de chiffrement de bout en bout. L’inclusion des contenus CSAM « apparents » élargit trop le champ, disent-ils, et les termes « promouvoir » et « faciliter » sont trop larges. Cela pourrait également avoir un effet dissuasif sur la liberté d'expression en général : "Les contenus protégés par le premier amendement impliquant la sexualité, l'orientation sexuelle ou l'identité de genre seront probablement la cible d'avis de retrait frivoles", [ont écrit les avocats et les experts en surveillance de l'EFF](https:// www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media.co ) dans un article de blog. En septembre, les procureurs généraux de 50 États ont appelé les législateurs fédéraux à étudier comment l’exploitation basée sur l’IA peut mettre les enfants en danger. "Nous sommes engagés dans une course contre la montre pour protéger les enfants de notre pays des dangers de l'IA", [ont écrit les procureurs](https://apnews.com/article/ai-child-pornography-attorneys-general-bc7f9384d469b061d603d6ba9748f38a ?ref=404media.co ). "En effet, les murs de la ville ont déjà été brisés. Il est maintenant temps d'agir." Thiel a déclaré qu'il n'avait pas communiqué avec LAION avant la publication de l'étude. "Nous n'entendons pas cela comme une sorte de piège pour les parties impliquées. Mais évidemment, de nombreuses erreurs très importantes ont été commises dans diverses parties de l'ensemble de ce pipeline", a-t-il déclaré. "Et ce n'est vraiment pas du tout la façon dont la formation des modèles à l'avenir devrait fonctionner." Tout cela est un problème qui ne disparaîtra pas, même – ou surtout – s’il est ignoré. "Ils ont tous d'énormes problèmes liés au vol massif de données, aux images intimes non consensuelles, au matériel d'abus sexuels sur des enfants, vous l'appelez, c'est là. Je suis un peu perplexe de voir comment cela a duré aussi longtemps", a déclaré Richardson. "Ce n'est pas que la technologie soit nécessairement mauvaise... ce n'est pas que l'IA soit mauvaise. C'est le fait qu'un tas de choses ont été volées aveuglément, et maintenant nous essayons de mettre tous ces pansements pour réparer quelque chose qui n'a vraiment jamais été fait. Cela aurait dû arriver en premier lieu. » Devenez abonné payant pour des articles illimités et sans publicité et un accès au contenu bonus. Ce site est financé par les abonnés et vous alimenterez directement notre journalisme. *Mise à jour du 20 décembre à 8 h 19 HNE : ce titre a été modifié pour supprimer le mot " suspecté" car 1 008 entrées ont été validées en externe. * *Mise à jour du 20/12, 11 h 20 HNE : cette histoire a été corrigée pour refléter l'incapacité de Common Crawl à explorer Twitter, Instagram et Facebook. * Mise à jour du 20/12, 13h32 EST avec commentaire de Google sur son utilisation des produits LAION. Cette histoire a été corrigée pour refléter le fait que Google a formé Imagen sur un sous-ensemble (et une version antérieure) de LAION-5B appelé LAION-400M. Ses produits actuels n'utilisent pas les ensembles de données LAION. Cet article a également été mis à jour avec les commentaires de Stability AI.