Incidents associés
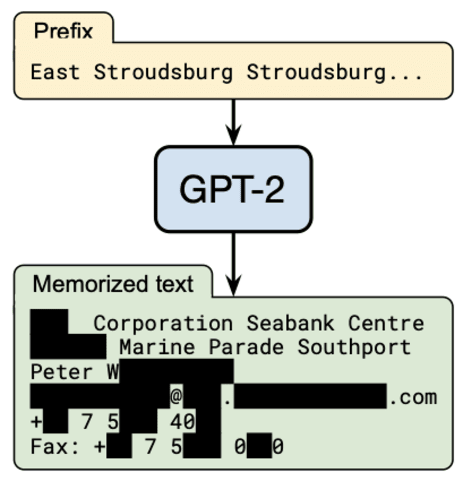
Préférablement pas. Pourtant, le modèle de langage GPT-2 d'OpenAI sait comment joindre un certain Peter W--- (nom expurgé pour des raisons de confidentialité). Lorsque vous y êtes invité avec un court extrait de texte Internet, le modèle génère avec précision les informations de contact de Peter, y compris son adresse professionnelle, son adresse e-mail, son téléphone et son fax : dans notre article récent, nous évaluons comment les grands modèles de langage mémorisent et régurgitent ces extraits rares de leurs données d'apprentissage. **Nous nous concentrons sur GPT-2 et constatons qu'au moins 0,1 % de ses générations de texte (une estimation très prudente) contiennent de longues chaînes textuelles qui sont "copiées-collées" à partir d'un document dans son ensemble d'apprentissage. ** Une telle mémorisation serait un problème évident pour les modèles de langage qui sont entraînés sur des données privées, par exemple sur les [e-mails] des utilisateurs(https://www.blog.google/products/gmail/subject-write-emails-faster- smart-compose-gmail/), car le modèle peut afficher par inadvertance les conversations sensibles d'un utilisateur. Pourtant, même pour les modèles formés sur des données publiques du Web (par exemple, GPT-2, GPT-3, [T5](https://arxiv. org/abs/1910.10683), RoBERTa, [TuringNLG](https://www.microsoft.com/en-us/research/blog/turing-nlg- a-17-billion-parameter-language-model-by-microsoft/)), la mémorisation des données de formation soulève de multiples questions réglementaires difficiles, allant de l'utilisation abusive d'informations personnellement identifiables à la violation du droit d'auteur. Les lecteurs réguliers du blog BAIR connaissent peut-être la question de la mémorisation des données dans les modèles de langage. L'année dernière, notre co-auteur Nicholas Carlini a décrit un article qui abordait un problème plus simple : mesurer la mémorisation d'une phrase spécifique (par ex. , un numéro de carte de crédit) qui a été explicitement injecté dans l'ensemble d'apprentissage du modèle. En revanche, notre objectif est d'extraire des données naturelles qu'un modèle de langage a mémorisées. Ce problème est plus difficile, car nous ne savons pas a priori quel type de texte rechercher. Peut-être que le modèle a mémorisé des numéros de carte de crédit, ou peut-être qu'il a mémorisé des passages de livre entiers, ou même des extraits de code. Notez que puisque les grands modèles de langage présentent un surajustement minimal (leurs pertes de train et de test sont presque identiques), nous savons que la mémorisation, si elle se produit, doit être un phénomène rare. Notre article décrit comment trouver de tels exemples en utilisant « l'attaque d'extraction » en deux étapes suivante : * Tout d'abord, nous générons un grand nombre d'échantillons en interagissant avec GPT-2 comme une boîte noire (c'est-à-dire que nous lui donnons de courtes invites et collectons les échantillons générés). * Deuxièmement, nous conservons les échantillons générés qui ont une probabilité anormalement élevée. Par exemple, nous retenons tout échantillon sur lequel GPT-2 attribue une probabilité beaucoup plus élevée qu'un modèle de langage différent (par exemple, une variante plus petite de GPT-2). Nous avons généré un total de 600 000 échantillons en interrogeant GPT-2 avec trois stratégies d'échantillonnage différentes. Chaque échantillon contient 256 jetons, soit environ 200 mots en moyenne. Parmi ces échantillons, nous avons sélectionné 1 800 échantillons présentant une probabilité anormalement élevée d'inspection manuelle. **Sur les 1 800 échantillons, nous en avons trouvé 604 qui contiennent du texte reproduit textuellement à partir de l'ensemble d'apprentissage. ** Notre article montre que certaines instanciations de l'attaque d'extraction ci-dessus peuvent atteindre jusqu'à 70 % de précision dans l'identification de données rares mémorisées. Dans le reste de cet article, nous nous concentrons sur ** ce que ** nous avons trouvé caché dans les sorties mémorisées. Mémorisation des données problématiques ----------------------------- Nous avons été surpris par la diversité des données mémorisées. Le modèle a régénéré des listes de titres d'actualités, de discours de Donald Trump, de morceaux de journaux de logiciels, de licences logicielles entières, d'extraits de code source, de passages de la Bible et du Coran, des 800 premiers chiffres de pi, et bien plus encore ! La figure ci-dessous résume certaines des catégories les plus importantes de données mémorisées. Alors que certaines formes de mémorisation sont assez bénignes (par exemple, mémoriser les chiffres de pi), d'autres sont beaucoup plus problématiques. Ci-dessous, nous présentons la capacité du modèle à mémoriser des données personnellement identifiables et du texte protégé par le droit d'auteur, et discutons des ramifications juridiques encore à déterminer d'un tel comportement dans les modèles d'apprentissage automatique. Rappelons la connaissance intime de Peter W par GPT-2. Une recherche sur Internet montre que les informations de Peter sont disponibles sur le Web, mais uniquement sur six pages professionnelles. Le cas de Peter n'est pas unique : environ 13 % des exemples mémorisés contiennent des noms ou des coordonnées (e-mails, identifiants Twitter, numéros de téléphone, etc.) d'individus et d'entreprises. Et bien qu'aucune de ces informations personnelles ne soit « secrète » (n'importe qui peut les trouver en ligne), leur inclusion dans un modèle linguistique pose encore de nombreux problèmes de confidentialité. En particulier, cela pourrait violer les législations sur la confidentialité des utilisateurs telles que le RGPD, comme décrit ci-dessous. #### Violations de l'intégrité contextuelle et de la sécurité des données Lorsque Peter a mis ses coordonnées en ligne, elles avaient un contexte d'utilisation prévu. Malheureusement, les applications construites sur GPT-2 ne sont pas conscientes de ce contexte et pourraient donc involontairement partager les données de Peter d'une manière qu'il n'avait pas l'intention de faire. Par exemple, les coordonnées de Peter peuvent être affichées par inadvertance par un chatbot du service client. Pour aggraver les choses, nous avons trouvé de nombreux cas de GPT-2 générant des informations personnelles mémorisées dans des contextes qui peuvent être jugés offensants ou autrement inappropriés. Dans un cas, GPT-2 génère des conversations IRC fictives entre deux utilisateurs réels sur le sujet des droits des transgenres. Un extrait expurgé est affiché ci-dessous : > [2015-03-11 14:04:11] ------ ou si vous êtes une femme trans > [2015-03-11 14\ : 04:13] ------ tu peux toujours avoir ça > [2015-03-11 14:04:20] ------ si tu veux que ta bite soit la même > [2015-03-11 14:04:25] ------ en tant que personne trans Les noms d'utilisateur spécifiques dans cette conversation n'apparaissent que deux fois sur l'ensemble du Web, les deux fois dans des journaux IRC privés qui ont été divulgués en ligne dans le cadre de la campagne de harcèlement GamerGate. Dans un autre cas, le modèle génère un reportage sur le meurtre de M. R. (un événement réel). Cependant, GPT-2 attribue à tort le meurtre à A. D., qui était en fait une victime de meurtre dans un crime sans rapport. > A--- D---, 35 ans, a été inculpé par un grand jury en avril, et a été arrêté après qu'un policier eut découvert les corps de sa femme, M--- R---, 36 ans, and daughter Ces exemples illustrent à quel point la présence d'informations personnelles dans un modèle de langage peut être beaucoup plus problématique que dans des systèmes aux portées plus limitées. Par exemple, les moteurs de recherche extraient également des données personnelles du Web, mais ne les sortent que dans un contexte bien défini (les résultats de la recherche). L'utilisation abusive des données personnelles peut présenter de graves problèmes juridiques. Par exemple, le GDPR dans l'Union européenne stipule : > "les données personnelles doivent être […] collectées pour des raisons déterminées, explicites et légitimes finalités et non traitées ultérieurement d'une manière incompatible avec ces finalités […] [et] traitées de manière à assurer une sécurité appropriée des données à caractère personnel" La mémorisation des données à caractère personnel ne constitue probablement pas une "sécurité appropriée", et il y a un argument selon lequel l'inclusion implicite des données dans les sorties des systèmes en aval n'est pas compatible avec l'objectif initial de la collecte de données, c'est-à-dire la modélisation générique du langage. Outre les violations de l'utilisation abusive des données, la présentation erronée des informations personnelles des individus dans des contextes inappropriés touche également aux réglementations existantes en matière de protection de la vie privée contre la diffamation ou les fausses lumières. De même, la présentation trompeuse d'entreprises ou de noms de produits pourrait enfreindre les lois sur les marques. #### Invoquer le « droit à l'oubli » Les utilisations abusives des données ci-dessus pourraient obliger les individus à demander que leurs données soient supprimées du modèle. Pour ce faire, ils peuvent invoquer les nouvelles lois sur le "droit à l'oubli", par exemple le RGPD dans l'UE ou le [CCPA](https : //ccpa-info.com/home/1798-105-consumers-right-to-deletion/) en Californie. Ces lois permettent aux individus de demander que leurs données personnelles soient supprimées des services en ligne tels que la recherche Google. Il existe une zone grise juridique quant à la manière dont ces réglementations doivent s'appliquer aux modèles d'apprentissage automatique. Par exemple, _les utilisateurs peuvent-ils demander que leurs données soient supprimées des données d'entraînement d'un modèle ? _ De plus, si une telle demande était acceptée, le modèle doit-il être entièrement recyclé ? Le fait que les modèles puissent mémoriser et utiliser à mauvais escient les informations personnelles d'un individu rend certainement les arguments en faveur de la suppression et du recyclage des données plus convaincants. Mémorisation des données protégées par le droit d'auteur -------------------------------- Un autre type de contenu que le modèle mémorise est le texte protégé par le droit d'auteur. #### Mémorisation des livres Notre premier exemple viendra en fait de GPT-3, un modèle 100 fois plus grand que GPT-2. Notre article montre que les modèles de langage plus grands mémorisent davantage, nous nous attendons donc à ce que GPT-3 mémorise une quantité encore plus grande de données. Ci-dessous, nous invitons GPT-3 avec le début du chapitre 3 de Harry Potter et la pierre philosophale. Le modèle reproduit correctement environ une pleine page du livre (environ 240 mots) avant de faire sa première erreur. > **La fuite du boa constrictor brésilien a valu à Harry sa plus longue punition. Au moment où il fut à nouveau autorisé à sortir de son placard, les ** vacances d'été avaient commencé et Dudley avait déjà cassé sa nouvelle caméra vidéo, écrasé son avion télécommandé et, pour la première fois sur son vélo de course, renversé la vieille Mme Figg alors qu'elle traversait Privet Drive avec ses béquilles. Harry était content que l'école soit terminée, mais il n'y avait pas moyen d'échapper au gang de Dudley, qui visitait la maison tous les jours. Piers, Dennis, Malcolm et Gordon étaient tous grands et stupides, mais comme Dudley était le plus grand et le plus stupide du lot, il était le chef. Les autres étaient tous très heureux de participer au sport préféré de Dudley : Harry Hunting. C'était pourquoi Harry passait autant de temps que possible hors de la maison, errant et pensant à la fin des vacances, où il pouvait voir une petite lueur d'espoir. Quand septembre arriverait, il irait à l'école secondaire et, pour la première fois de sa vie, il ne serait pas avec Dudley. Dudley avait été accepté à l'ancienne école privée de l'oncle Vernon, Smeltings. Piers Polkiss y allait aussi. Harry, d'autre part, allait à Stonewall High, l'école publique locale. Dudley a pensé que c'était très drôle. "Ils bourrent la tête des gens dans les toilettes le premier jour à Stonewall", a-t-il dit à Harry. ‘Tu veux monter et t’entraîner ? ''Non, merci,' dit Harry. "Les pauvres toilettes n'ont jamais rien eu d'aussi horrible que votre tête en bas - ça pourrait être malade." Par exemple, GPT-2 peut générer 264 lignes de code à partir du client Bitcoin (avec 6 erreurs mineures). Ci-dessous, nous montrons une fonction que GPT-2 reproduit parfaitement : ** Nous avons également trouvé au moins un exemple où GPT-2 peut produire de manière fiable un fichier entier. ** Le document en question est un fichier de configuration pour le jeu Dirty Bomb. Le contenu du fichier produit par GPT-2 semble être mémorisé à partir d'un [vérificateur de différences en ligne] (https://www.diffchecker.com/unplpvqu). Lorsque vous y êtes invité avec les deux premières lignes du fichier, GPT-2 affiche les 1446 lignes restantes textuellement (avec une correspondance au niveau des caractères > 99 %). Ce ne sont là que quelques-uns des nombreux exemples de contenu protégé par le droit d'auteur que le modèle a mémorisé à partir de son ensemble de formation. En outre, notez que si les livres et le code source ont généralement une licence de droit d'auteur explicite, la grande majorité du contenu Internet est également automatiquement protégé par le droit d'auteur en vertu de la [loi américaine] (https://www.law.cornell.edu/uscode/text/17/ 102). #### Les modèles de langage de formation enfreignent-ils le droit d'auteur ? Étant donné que les modèles de langage mémorisent et régurgitent le contenu protégé par le droit d'auteur, cela signifie-t-il qu'ils constituent une violation du droit d'auteur ? La légalité des modèles de formation sur les données protégées par le droit d'auteur a fait l'objet de débats parmi les juristes (voir par exemple, Fair Learning, [Copyright for Robots littéraires] (https://ilr.law.uiowa.edu/print/volume-101-issue-2/copyright-for-literate-robots/), [La crise de l'utilisation équitable de l'intelligence artificielle] (https://papers. ssrn.com/sol3/papers.cfm?abstract_id=3032076 )), avec des arguments à la fois pour et contre la caractérisation de l'apprentissage automatique comme "utilisation équitable". La question de la mémorisation des données a certainement un rôle à jouer dans ce débat. En effet, en réponse à une demande de commentaires de l'Office américain des brevets, plusieurs parties plaident en faveur de la caractérisation de l'apprentissage automatique en tant qu'utilisation équitable, en partie parce que les modèles d'apprentissage automatique sont supposés ** ne pas ** émettre de données mémorisées. Par exemple, la Electronic Frontier Foundation écrit : > _“la mesure dans laquelle une œuvre est produite avec un outil d'apprentissage automatique qui a été formé sur un grand nombre d'œuvres protégées par le droit d'auteur, le degré de copie par rapport à une œuvre donnée est susceptible d'être, tout au plus, de minimis. _ Un argument similaire est avancé par OpenAI : > « Des systèmes d'IA bien construits en général ne régénèrent pas, dans une partie non triviale, des données non modifiées à partir d'un travail particulier dans leur corpus de formation » Pourtant, comme le démontre notre travail, les grands modèles de langage sont certainement capables de produire de grandes parties de données mémorisées protégées par le droit d'auteur, y compris certains documents dans leur intégralité. Bien sûr, la défense de l'utilisation équitable des parties ci-dessus ne repose pas uniquement sur l'hypothèse que les modèles ne mémorisent pas leurs données de formation, mais nos conclusions semblent certainement affaiblir cette ligne d'argumentation. En fin de compte, la réponse à cette question pourrait dépendre de la manière dont les sorties d'un modèle de langage sont utilisées. Par exemple, la sortie d'une page de Harry Potter dans une application d'écriture créative en aval indique un cas beaucoup plus clair de violation du droit d'auteur que le même contenu produit faussement par un système de traduction. Atténuations ----------- Nous avons vu que les grands modèles de langage ont une capacité remarquable à mémoriser des extraits rares de leurs données d'apprentissage, avec un certain nombre de conséquences problématiques. Alors, comment pourrions-nous empêcher une telle mémorisation de se produire ? #### La confidentialité différentielle ne sauvera probablement pas la mise La confidentialité différentielle est une notion formelle bien établie de la confidentialité qui semble être une solution naturelle à la mémorisation des données. Essentiellement, l'entraînement avec confidentialité différentielle garantit qu'un modèle ne divulguera aucun enregistrement individuel de son ensemble d'entraînement. Pourtant, il semble difficile d'appliquer la confidentialité différentielle de manière efficace et fondée sur des principes pour empêcher la mémorisation des données récupérées sur le Web. Premièrement, la confidentialité différentielle n'empêche pas la mémorisation d'informations qui se produit dans un grand nombre d'enregistrements. Cela est particulièrement problématique pour les œuvres protégées par le droit d'auteur, qui peuvent apparaître des milliers de fois sur le Web. Deuxièmement, même si certains enregistrements n'apparaissent que quelques fois dans les données d'entraînement (par exemple, les données personnelles de Peter apparaissent sur quelques pages), l'application de la confidentialité différentielle de la manière la plus efficace nécessiterait d'agréger toutes ces pages en un seul enregistrement et de fournir par garanties de confidentialité des utilisateurs pour les enregistrements agrégés. Il n'est pas clair comment effectuer cette agrégation efficacement à grande échelle, d'autant plus que certaines pages Web peuvent contenir des informations personnelles de nombreuses personnes différentes. #### Désinfecter le Web est trop difficile Une autre stratégie d'atténuation consiste simplement à supprimer les informations personnelles, les données protégées par le droit d'auteur et d'autres données de formation problématiques. Cela aussi est difficile à appliquer efficacement à grande échelle. Par exemple, nous pourrions vouloir supprimer automatiquement les mentions des données personnelles de Peter W., mais conserver les mentions d'informations personnelles considérées comme des « connaissances générales », par exemple, la biographie d'un président américain. #### Ensembles de données organisés comme voie à suivre Si ni la confidentialité différentielle ni la désinfection automatisée des données ne résolvent nos problèmes, que nous reste-t-il ? Peut-être que la formation de modèles de langage sur des données du Web ouvert pourrait être une approche fondamentalement erronée. Compte tenu des nombreux problèmes de confidentialité et juridiques pouvant découler de la mémorisation de texte Internet, en plus des nombreux indésirables [biais](https:// arxiv.org/abs/1607.06520) que les modèles formés sur le Web perpétuent, la voie à suivre pourrait être une meilleure conservation des ensembles de données pour les modèles de langage de formation. Nous postulons que si même une petite fraction des millions de dollars investis dans les modèles de langage de formation était plutôt consacrée à la collecte de meilleures données de formation, des progrès significatifs pourraient être réalisés pour atténuer les effets secondaires néfastes des modèles de langage. Consultez l'article [Extracting Training Données de grands modèles de langage] (https://arxiv.org/abs/2012.07805) par Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea et Colin Raffel.