Représentation et imagination pour prévenir les dommages causés par l'IA
Cet article est initialement apparu comme un article invité écrit pour [Montreal AI Ethics Institute](https://montrealethics .ai/). Les classifications mises à jour sont désormais disponibles sur la page de taxonomie CSET.
La base de données d'incidents d'IA fut lancée publiquement en novembre 2020 par le Partnership on AI en tant que tableau de bord des dommages causés par l'IA dans le monde réel. Inspirée de bases de données similaires dans l'industrie aéronautique, sa thèse du changement est dérivée de l'aphorisme de Santayana, "Ceux qui ne peuvent pas se souvenir du passé sont condamnés à le répéter". En tant que nouvelle industrie en pleine expansion, l'IA n'a pas d'historique officiel de ses échecs et les préjudices commençaient à [répéter](https://incidentdatabase.ai/cite/ 113). La base de données d'incidents d'IA archive donc les incidents détaillant un vérificateur d'image de passeport indiquant aux Asiatiques que leurs yeux sont fermés, les [préjugés sexistes des modèles linguistiques](https://incidentdatabase. ai/cite/59), et le décès d'un piéton en voiture autonome. Rendre ces incidents détectables aux futurs développeurs d'IA réduit la probabilité de récurrence.
Qu'avons-nous appris ?
Maintenant avec une grande collection d'incidents d'IA et une nouvelle fonctionnalité de taxonomie des incidents du [Center for Security and Emerging Technology] (https://cset.georgetown.edu/), nous avons une idée de notre histoire et deux statistiques méritent d'être soulignées.
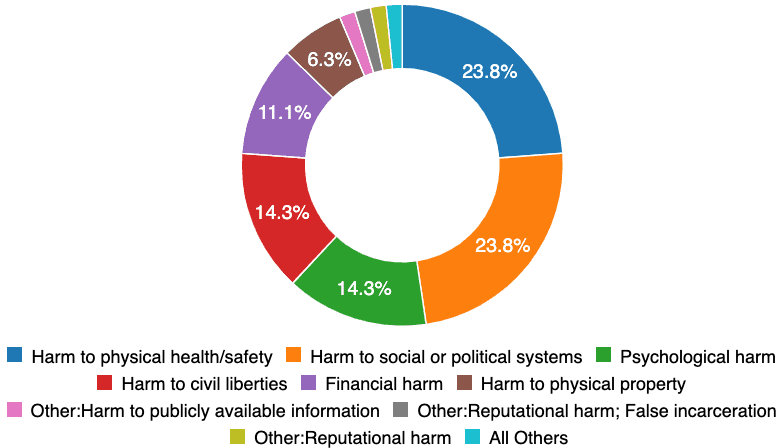
Premièrement, les types de dommages observés dans le monde réel sont très variés. Les processus sociétaux existants (par exemple, des tests de laboratoire formels et une certification indépendante) sont prêts à répondre à seulement 24 % des incidents liés à [la santé et la sécurité physiques](https://incidentdatabase.ai/apps/discover?classifications=CSET%3AHarm %20Type%3AHarm%20to%20physical%20health%2Fsafety). Alors qu'une voiture autonome pose des problèmes de sécurité évidents, les dommages aux systèmes sociaux et politiques, psychologie et [libertés civiles](https://incidentdatabase.ai/apps/discover?classifications =CSET%3AHarm%20Type%3AHarm%20to%20civil%20liberties) représentent plus de la moitié des incidents enregistrés aujourd'hui. Ces incidents sont probablement soit des échecs d'imagination, soit des échecs de représentation. Passons aux "échecs de l'imagination" en observant que la majorité des incidents ne sont pas répartis uniformément sur toutes les données démographiques de la population.
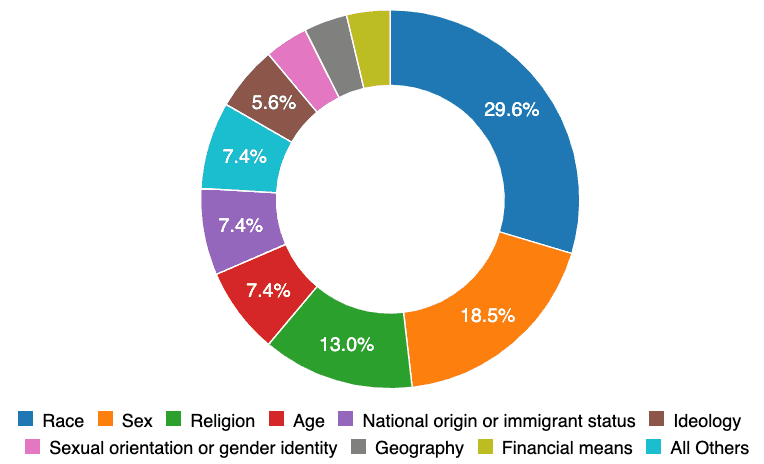
Parmi ces méfaits "inégalement répartis", 30% sont répartis selon la race et 19% selon le sexe. Beaucoup de ces incidents auraient pu être évités sans avoir besoin d'un exemple dans le monde réel si les équipes de conception des systèmes avaient une identité démographique plus variée.
La représentation est-elle donc une panacée aux méfaits des systèmes intelligents ? Non. Même s'il était possible d'avoir toutes les identités représentées, il y aura encore des incidents prouvant les limites de notre imaginaire collectif. Pour ces "échecs de l'imagination", la base de données d'incidents d'IA est prête à garantir qu'ils ne peuvent se produire qu'une seule fois.
Quelle est la prochaine étape ?
Si vous comparez la base de données d'incidents d'IA à la Common Vulnerabilities and Exposures database (base de données sur les vulnérabilités et les expositions communes) et à la [US Aviation Accident Database (base de données sur les accidents de l'aviation aux États-Unis)](https://www.ntsb.gov/_layouts/ntsb .aviation/index.aspx) disposent tous deux de logiciels, de processus, d'intégrations communautaires et d'autorités étendus accumulés au cours de décennies d'investissements privés et publics. Comparativement, la base de données d'incidents d'IA n'en est qu'au début de ses travaux, garantissant que l'IA soit plus socialement bénéfique. Trois domaines thématiques sont particulièrement importants pour s'appuyer sur les premiers succès de l'AIID dans sa forme actuelle. Ceux-ci inclus,
-
Gouvernance et processus. L'AIID opère dans un espace dépourvu de définitions établies et largement acceptées des technologies, des processus de réponse aux incidents et des impacts sur la communauté. La régularisation de ces éléments avec un organe de surveillance composé d'experts en la matière garantit un produit de travail de qualité et son adoption dans les sphères corporatives et gouvernementales.
-
** Étendre la profondeur technique. ** La base de données d'incidents d'IA n'offre pas une source canonique de vérité concernant les incidents d'IA. En effet, les parties raisonnables auront des raisons bien fondées pour lesquelles un incident devrait être signalé ou classé différemment. Par conséquent, la base de données prend en charge plusieurs perspectives sur les incidents à la fois en ingérant plusieurs rapports (à ce jour, 1 199 auteurs de 547 publications) et en prenant en charge plusieurs taxonomies pour lesquelles la taxonomie CSET est un exemple précoce. Les taxonomies AIID sont des collections flexibles de classifications gérées par des individus et des organisations experts. Les taxonomies sont les moyens par lesquels la société travaille collectivement pour comprendre à la fois les incidents individuels, ainsi que les statistiques au niveau de la population pour ces classifications. Des taxonomies d'incidents d'IA bien structurées et rigoureusement appliquées ont la capacité d'éclairer les priorités de recherche et d'élaboration de politiques pour une IA plus sûre, ainsi qu'aider les ingénieurs à comprendre les vulnérabilités et les problèmes produits par des systèmes intelligents de plus en plus complexes. La taxonomie CSET est une taxonomie générale des incidents d'IA impliquant plusieurs étapes d'examen et d'audit de classification pour assurer la cohérence entre les annotateurs. L'intention derrière la taxonomie CSET est d'informer les décideurs des impacts. Même avec le succès de la taxonomie CSET pour les créateurs de politiques, l'AIID manque toujours d'une taxonomie technique rigoureuse. De nombreuses classifications techniques indiquant où l'IA est susceptible de produire de futurs incidents ne sont pas actuellement saisies. Identifier l'IA non sûre et motiver le développement d'une IA sûre nécessite une classification technique.
-
Développez l'étendue de la base de données. La base de données d'incidents d'IA est construite sur une base de données de documents et une collection d'applications de navigateur sans serveur. Cela signifie que la base de données est hautement extensible à de nouveaux types d'incidents et évolutive à un très grand nombre de rapports d'incidents. En bref, l'architecture de la base de données anticipe la nécessité d'enregistrer un nombre croissant d'incidents d'IA très variés et complexes. Alors qu'un grand nombre d'incidents actuellement dans la base de données ont été fournis par la communauté open source, nous savons qu'il nous manque actuellement de nombreux incidents qui devraient être inclus avec les critères actuels. C'est un domaine où chacun a un rôle à jouer dans le développement réussi de notre point de vue collectif sur les incidents d'IA.
Comment pouvez-vous aider ?
La base de données d'incidents d'IA ne réussira pas sans votre contribution aux incidents et à l'analyse. Lorsque vous rencontrez un incident d'IA dans le monde, nous vous implorons de soumettre un nouvel incident enregistré dans la base de données. Nous demandons également aux ingénieurs en logiciel et aux chercheurs de travailler avec codebase et dataset de concevoir un avenir pour l'humanité qui profite au maximum des systèmes intelligents.