Problème 6784

Mardi, des chercheurs de Stanford et de Yale ont révélé une information que les entreprises d'IA préféreraient garder secrète. Quatre grands modèles de langage populaires – GPT d'OpenAI, Claude d'Anthropic, Gemini de Google et Grok de xAI – ont stocké d'importantes portions de certains des livres sur lesquels ils ont été entraînés et peuvent en reproduire de longs extraits.
En effet, sollicité de manière stratégique par les chercheurs, Claude a restitué le texte quasi intégral de Harry Potter à l'école des sorciers, Gatsby le Magnifique, 1984 et Frankenstein, ainsi que des milliers de mots tirés d'ouvrages tels que Hunger Games et L'Attrape-cœurs. Les trois autres modèles ont également reproduit des extraits de ces livres, dans des proportions variables. Treize livres ont été testés.
Ce phénomène a été baptisé « mémorisation », et les entreprises spécialisées en IA ont longtemps nié son existence à grande échelle. Dans une lettre adressée en 2023 au Bureau du droit d'auteur des États-Unis, OpenAI a déclaré que « les modèles ne stockent pas de copies des informations dont ils tirent des enseignements ». De même, Google a affirmé au Bureau du droit d'auteur qu'« aucune copie des données d'entraînement – qu'il s'agisse de texte, d'images ou d'autres formats – n'est présente dans le modèle lui-même ». Anthropic, Meta, Microsoft et d'autres ont formulé des affirmations similaires. (Aucune des entreprises d'IA mentionnées dans cet article n'a accepté de répondre à mes demandes d'entretien.)
L'étude de Stanford prouve l'existence de telles copies dans les modèles d'IA, et elle n'est que la plus récente d'une série d'études à le démontrer. Mes propres recherches ont révélé que les modèles basés sur l'image peuvent reproduire certaines œuvres d'art et photographies sur lesquelles ils sont entraînés. Cela pourrait représenter un risque juridique considérable pour les entreprises d'IA, susceptible de leur coûter des milliards de dollars en condamnations pour violation de droits d'auteur et d'entraîner le retrait de certains produits du marché. Cela contredit également l'explication de base fournie par l'industrie de l'IA quant au fonctionnement de sa technologie.
L'IA est souvent expliquée par métaphore ; les entreprises technologiques aiment à dire que leurs produits apprennent, que les LLM, par exemple, ont développé une compréhension de l'écriture anglaise sans qu'on leur ait explicitement enseigné les règles de grammaire. Cette nouvelle recherche, ainsi que plusieurs autres études menées ces deux dernières années, remettent en question cette métaphore. L'IA n'absorbe pas l'information comme le fait l'esprit humain. Elle la stocke et y accède.
De fait, de nombreux développeurs d'IA utilisent un terme plus précis techniquement pour parler de ces modèles : la compression avec perte. Ce terme commence également à se répandre en dehors de l'industrie. Il a récemment été invoqué par un tribunal allemand qui a statué contre OpenAI dans une affaire intentée par la GEMA, une société de gestion des droits musicaux. GEMA a démontré que ChatGPT pouvait produire des imitations fidèles de paroles de chansons. Le jury a comparé le modèle aux fichiers MP3 et JPEG, qui stockent votre musique et vos photos dans des fichiers plus petits que les originaux bruts et non compressés. Par exemple, lorsqu'une photo de haute qualité est enregistrée au format JPEG, la qualité de l'image obtenue est légèrement inférieure, avec parfois du flou ou des artefacts visuels. Un algorithme de compression avec perte conserve la photo, mais il s'agit d'une approximation et non du fichier exact. On parle de compression avec perte car certaines données sont perdues.
D'un point de vue technique, ce processus de compression est très similaire à ce qui se passe au sein des modèles d'IA, comme me l'ont expliqué des chercheurs de plusieurs entreprises et universités spécialisées en IA ces derniers mois. Ces modèles traitent du texte et des images, et produisent du texte et des images qui en sont une approximation.
Mais cette description simpliste est moins utile aux entreprises d'IA que la métaphore de l'apprentissage, utilisée pour affirmer que les algorithmes statistiques connus sous le nom d'IA finiront par faire de nouvelles découvertes scientifiques, s'amélioreront sans cesse et s'entraîneront de manière récursive, menant potentiellement à une « explosion d'intelligence ». Toute l'industrie repose sur une métaphore fragile.
Le problème devient évident lorsqu'on examine les générateurs d'images par IA. En septembre 2022, Emad Mostaque, cofondateur et alors PDG de Stability AI, a expliqué dans une interview podcast comment Stable Diffusion, le modèle d'image de Stability, avait été conçu. « Nous avons compressé 100 000 gigaoctets d'images en un fichier de deux gigaoctets capable de recréer n'importe laquelle de ces images, ainsi que leurs variantes », a-t-il déclaré.
Parmi les nombreux experts que j'ai consultés pour cet article figurait un chercheur indépendant en IA qui a étudié la capacité de Stable Diffusion à reproduire ses images d'entraînement. (J'ai accepté de préserver son anonymat, car il craint des représailles de la part des grandes entreprises du secteur.) L'image ci-dessus illustre cette capacité : à gauche, l'originale provenant du web – une image promotionnelle de l'émission télévisée Garfunkel and Oates – et à droite, une version générée par Stable Diffusion à partir de la légende qui accompagne l'image sur le web, contenant du code HTML : « IFC annule Garfunkel and Oates ». Grâce à cette technique simple, le chercheur m'a montré comment produire des copies quasi exactes de plusieurs dizaines d'images connues pour figurer dans l'ensemble d'entraînement de Stable Diffusion. La plupart de ces images présentent des résidus visuels qui ressemblent à une compression avec perte — le genre d'effet flou et irrégulier que l'on peut parfois observer sur ses propres photos.

Source : Karla Ortiz
Œuvre originale de Karla Ortiz (The Death I Bring, 2016) Graphite)

Source : Cour de district des États-Unis, district nord de Californie
Résultat du produit Reimagine XL de Stability (basé sur Stable Diffusion XL)
Ci-dessus, deux autres images issues d'une action en justice intentée contre Stability AI et d'autres entreprises. À gauche, une œuvre originale de Karla Ortiz ; à droite, une variation issue de Stable Diffusion. Ici, l'image est légèrement plus éloignée de l'originale. Certains éléments ont été modifiés. Au lieu de compresser au niveau du pixel, l'algorithme semble copier et manipuler des objets provenant de plusieurs images, tout en conservant une certaine continuité visuelle.
Comme l'expliquent les entreprises, les algorithmes d'IA extraient des « concepts » à partir de données d'entraînement et apprennent à créer des œuvres originales. Or, l'image de droite ne résulte pas uniquement de concepts. Il ne s'agit pas d'une image générique représentant, par exemple, « un ange avec des oiseaux ». Il est difficile de déterminer précisément pourquoi un modèle d'IA appose une marque spécifique sur une image, mais on peut raisonnablement supposer que la diffusion stable parvient à générer l'image de droite en partie grâce aux éléments visuels qu'elle a stockés à partir de l'image de gauche. Il ne s'agit pas d'un collage au sens physique du terme, mais il ne s'agit pas non plus d'un apprentissage au sens humain du terme. Le modèle ne possède ni sens ni expérience consciente lui permettant de formuler ses propres jugements esthétiques.
Google a déclaré (https://www.regulations.gov/comment/COLC-2023-0006-9003) que les modèles de langage humain (LLM) ne stockent pas des copies de leurs données d'entraînement, mais plutôt les « structures du langage humain ». Cette affirmation est vraie en apparence, mais trompeuse lorsqu'on l'analyse en profondeur. Comme cela a été largement documenté (https://huggingface.co/learn/llm-course/en/chapter2/4), lorsqu'une entreprise utilise un livre pour développer un modèle d'IA, elle segmente le texte en tokens, ou fragments de mots. Par exemple, la phrase « bonjour, mon ami » peut être représentée par les tokens « il », « s'il », « mon », « ami » et « fin ». Certains tokens sont des mots à part entière ; d'autres sont simplement des groupes de lettres, d'espaces et de signes de ponctuation. Le modèle stocke ces tokens et les contextes dans lesquels ils apparaissent dans les livres. Le LLM ainsi obtenu est essentiellement une immense base de données de contextes et des tokens les plus susceptibles d'apparaître ensuite.
Ce modèle peut être visualisé sous forme de carte. Voici un exemple, avec les tokens les plus probables issus de Llama-3.1-70B de Meta :
Source : The Atlantic / Llama
Lorsqu'un LLM « écrit » une phrase, il parcourt un vaste ensemble de séquences de tokens possibles, en choisissant la plus probable à chaque étape. La description de Google est trompeuse, car les prédictions des tokens suivants ne proviennent pas d'une entité vague comme le « langage humain », mais des livres, articles et autres textes analysés par le modèle.
Par défaut, les modèles peuvent parfois s'écarter du jeton suivant le plus probable. Ce comportement est souvent présenté par les entreprises d'IA comme un moyen de rendre les modèles plus « créatifs », mais il a aussi l'avantage de masquer les copies du texte d'entraînement.
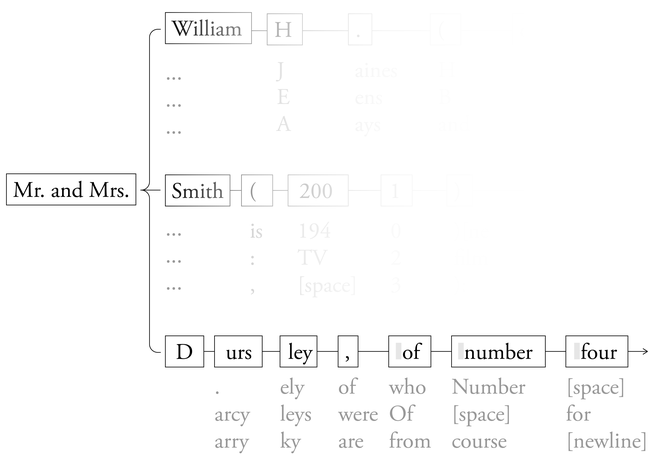
Il arrive que la carte linguistique soit si détaillée qu'elle contienne des copies exactes de livres et d'articles entiers. L'été dernier, une étude (http://arxiv.org/abs/2505.12546v3) portant sur plusieurs modèles de langage (LLM) a révélé que le modèle Llama 3.1-70B de Meta pouvait, à l'instar de Claude, reproduire fidèlement le texte intégral de Harry Potter à l'école des sorciers. Les chercheurs ont fourni au modèle uniquement les premiers jetons du livre : « M. et Mme D. ». Dans la carte linguistique interne de Llama, le texte suivant le plus probable était : « Ursley, du numéro quatre, Privet Drive, étaient fiers de dire qu'ils étaient parfaitement normaux, merci beaucoup. » Il s'agit précisément de la première phrase du livre. En réinjectant sans cesse le résultat du modèle, Llama a poursuivi ce processus jusqu'à produire l'intégralité du livre, à l'exception de quelques courtes phrases.
Grâce à cette technique, les chercheurs ont également démontré que Llama avait compressé sans perte de larges extraits d'autres œuvres, comme le célèbre essai de Ta-Nehisi Coates paru dans The Atlantic, intitulé « The Case for Reparations ». En lui fournissant la première phrase de l'essai, le modèle a extrait textuellement plus de 10 000 mots, soit les deux tiers du texte. Il semble également possible d'extraire de larges quantités de texte de Le Trône de Fer de George R. R. Martin, de Beloved de Toni Morrison, et d'autres ouvrages, avec Llama 3.1-70B.
Les chercheurs de Stanford et de Yale ont également démontré cette semaine qu'un modèle peut paraphraser un livre plutôt que de le reproduire à l'identique. Par exemple, là où Le Trône de Fer dit : « Jon aperçut une forme pâle se déplaçant entre les arbres », les chercheurs ont constaté que GPT-4.1 produisait : « Quelque chose bougeait, juste à la limite de la vision : une forme pâle, glissant entre les troncs. » Comme dans l'exemple de diffusion stable mentionné précédemment, la production du modèle est extrêmement similaire à l'œuvre originale.
Ce n'est pas la seule étude à démontrer le plagiat courant des modèles d'IA. « En moyenne, 8 à 15 % du texte généré par les LLM » se retrouve également sur le web, sous la même forme, selon une étude (http://arxiv.org/abs/2411.10242). Les chatbots enfreignent régulièrement les normes éthiques auxquelles les humains sont normalement soumis.
La mémorisation pourrait avoir des conséquences juridiques d'au moins deux manières. D'une part, si la mémorisation est inévitable, les développeurs d'IA devront empêcher les utilisateurs d'accéder au contenu mémorisé, comme l'ont souligné des juristes (https://scholarship.kentlaw.iit.edu/cklawreview/vol100/iss1/9). De fait, au moins un tribunal l'a déjà exigé (https://www.courtlistener.com/docket/68889092/291/concord-music-group-inc-v-anthropic-pbc/). Cependant, les techniques existantes sont faciles à contourner. Par exemple, 404 Media a signalé que Sora 2 d'OpenAI refusait de générer une vidéo du jeu populaire Animal Crossing, mais fonctionnait correctement si le titre du jeu était simplement « 'crossing aminal' [sic*] 2017 ». Si les entreprises ne peuvent garantir que leurs modèles n'enfreindront jamais les droits d'auteur d'un auteur ou d'un artiste, un tribunal pourrait les contraindre à retirer le produit du marché.
Une autre raison pour laquelle les entreprises d'IA pourraient être tenues responsables de violation de droits d'auteur est qu'un modèle lui-même pourrait être considéré comme une copie illégale. Mark Lemley, professeur de droit à Stanford qui a représenté Stability AI et Meta dans des procès similaires, m'a confié ne pas être certain qu'il soit exact d'affirmer qu'un modèle « contient » une copie d'un livre, ou plutôt qu'« il s'agit d'un ensemble d'instructions permettant de créer une copie à la volée en réponse à une demande ». Même cette dernière affirmation est potentiellement problématique, mais si les juges retiennent la première, les plaignants pourraient exiger la destruction des copies contrefaites. Autrement dit, outre les amendes, les entreprises spécialisées en IA pourraient, dans certains cas, être contraintes légalement de réentraîner leurs modèles de A à Z, avec du contenu dûment autorisé.
Dans une plainte, le New York Times a affirmé que GPT-4 d'OpenAI pouvait reproduire des dizaines d'articles du Times quasiment mot pour mot. OpenAI (qui a un partenariat avec The Atlantic) a réagi en affirmant que le Times avait utilisé des « incitations trompeuses » qui violaient ses conditions d'utilisation et avaient soumis le modèle à des extraits de ces articles. « Les utilisateurs lambda n'utilisent pas les produits d'OpenAI de cette manière », a écrit l'entreprise, qui a même prétendu que « le Times avait payé quelqu'un pour pirater ses produits ». OpenAI a également qualifié ce type de reproduction de « bug rare que nous nous efforçons d'éliminer complètement ».
Cependant, les recherches récentes montrent clairement que la capacité de plagiat est inhérente à GPT-4 et à tous les autres grands modèles de langage. Aucun des chercheurs avec lesquels je me suis entretenu ne pensait que le phénomène sous-jacent, la mémorisation, soit inhabituel ou puisse être éradiqué.
Dans les procès pour violation de droits d'auteur, la métaphore de l'apprentissage permet aux entreprises d'établir des comparaisons trompeuses entre les chatbots et les humains. Au moins un juge a repris ces comparaisons, assimilant le vol et la numérisation de livres par une entreprise d'IA à « l'apprentissage de l'écriture par les écoliers ». Deux procès ont également eu lieu dans lesquels des juges ont statué que l'entraînement d'un LLM sur des livres protégés par le droit d'auteur constituait une utilisation équitable, mais les deux décisions étaient erronées dans leur traitement de la mémorisation : un juge a cité le témoignage d'un expert qui montrait que Llama ne pouvait reproduire que 50 jetons au maximum à partir des livres des plaignants, bien que des recherches publiées depuis prouvent le contraire. L'autre juge a reconnu que Claude avait mémorisé des passages importants de livres, mais a déclaré que les plaignants n'avaient pas démontré que cela posait problème.
Les recherches sur la réutilisation des contenus d'entraînement par les modèles d'IA sont encore rudimentaires, notamment parce que les entreprises du secteur ont intérêt à ce que cela reste ainsi. Plusieurs chercheurs que j'ai interrogés lors de la rédaction de cet article m'ont parlé de recherches sur la mémorisation qui ont été censurées et entravées par les juristes des entreprises. Aucun n'a souhaité s'exprimer publiquement à ce sujet, par crainte de représailles.
Parallèlement, Sam Altman, PDG d'OpenAI, a défendu le « droit d'apprendre » de cette technologie à partir de livres et d'articles, « comme un être humain ». Cette idée trompeuse et séduisante empêche le débat public nécessaire sur la manière dont les entreprises d'IA utilisent les œuvres créatives et intellectuelles dont elles sont totalement dépendantes.