Incidents associés

ChatGPT a supprimé aujourd'hui près de 50 000 conversations partagées de l'index Google suite à notre article. Ils pensaient avoir résolu le problème. Mais est-ce vraiment le cas ?
Une nouvelle enquête de Digital Digging, voici la première, menée avec le chercheur belge Nicolas Deleur, a révélé 110 000 conversations ChatGPT conservées via la Wayback Machine d'Archive.org. Lorsque les utilisateurs cliquent sur « Partager » sur une conversation ChatGPT, ils pensent créer un lien temporaire pour un ami ou un collègue. Ce qu'ils ignorent, c'est qu'ils créent également un enregistrement permanent et consultable de leurs pensées, confessions et parfois activités illégales, consultées par Archive.org.
J'ai demandé au directeur de la Wayback Machine, Mark Graham, de commenter. Graham : « Je peux/vais vous dire que nous n'avons reçu ni honoré aucune demande d'exclusion (à grande échelle) des URL "chatgpt.com/share". Si OpenAI, détenteur des droits sur le contenu du domaine chatgpt.com, demandait l'exclusion des URL du modèle chatgpt.com, nous honorerions probablement cette demande. Cependant, ils n'ont pas formulé une telle demande. »
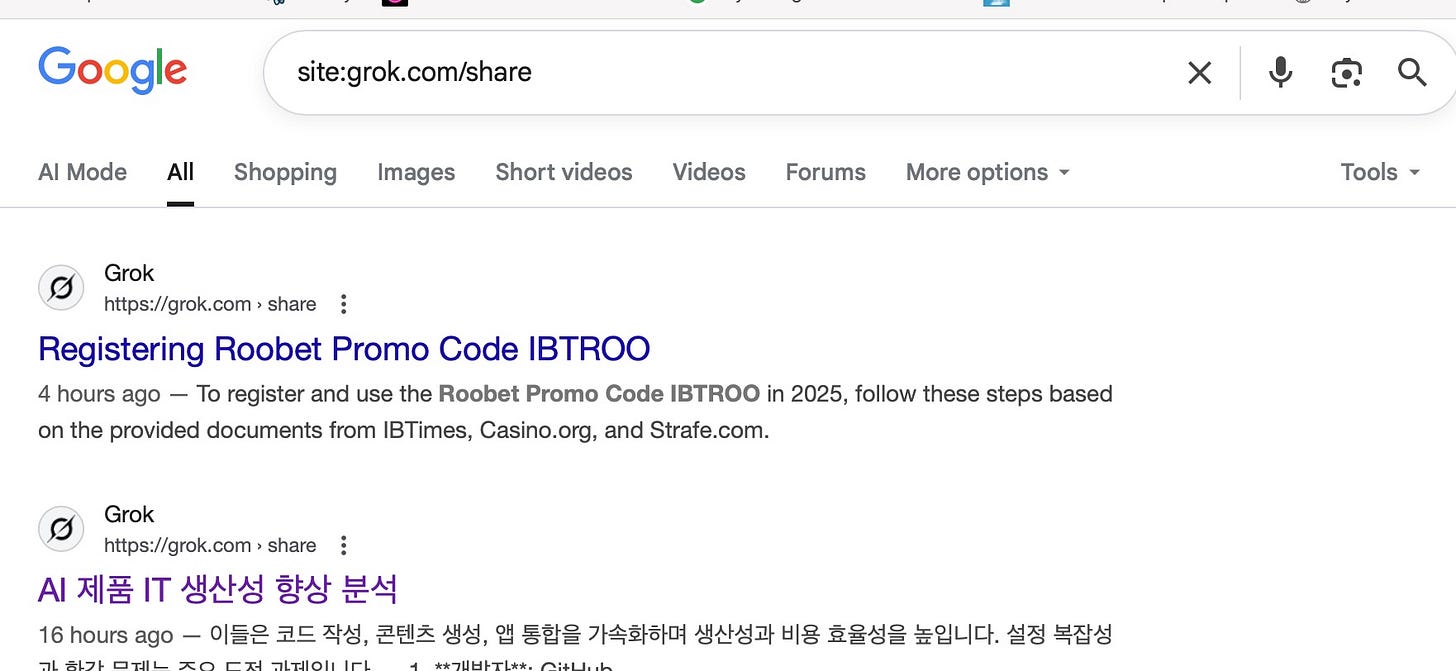
Au moment où nous parlons, les chats de Grok sont toujours visibles sur Google via site:grok.com/share, mais ils sont rapidement supprimés.
Alors qu'OpenAI s'efforçait aujourd'hui de déréférencer les conversations de Google, ils ont oublié la règle la plus fondamentale d'Internet : rien ne disparaît vraiment.
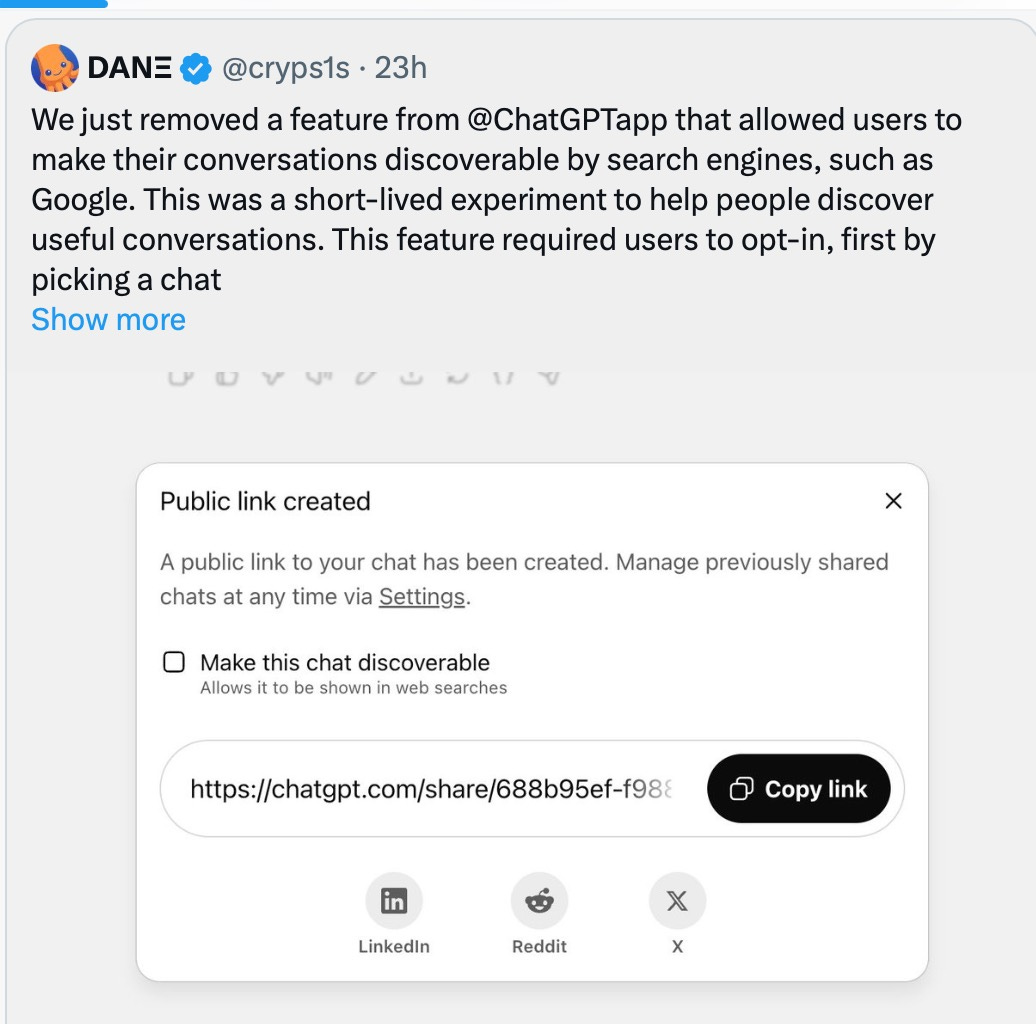
Plus de 100 000 conversations ChatGPT sont toujours présentes sur Archive.org, avec toutefois une particularité : avec une variante. Ces conversations ne sont pas de simples liens ou fragments. Ce sont des conversations complètes, figées dans le temps, contenant des « confessions » similaires à celles que nous avons révélées hier. Les utilisateurs ont partagé ces conversations publiquement, non pas par défaut, mais uniquement en cliquant sur Partager.
Parmi les conversations récemment découvertes, des tendances se dégagent de nos conclusions initiales. La plupart des conversations partagées sont inoffensives, mais certaines ne le sont pas. Voici trois exemples tirés de la base de données archive.org (voir la note ci-dessous expliquant pourquoi nous ne citons pas les noms) :
La stratégie d'accaparement des terres en Amazonie
Lors d'une conversation particulièrement accablante, un avocat italophone d'une multinationale de l'énergie a dévoilé sa stratégie de déplacement des communautés autochtones d'Amazonie. L'utilisateur s'est présenté en disant : « Je suis l'avocat d'un groupe multinational actif dans le secteur de l'énergie qui envisage de déplacer une petite communauté autochtone d'Amazonie de ses territoires afin de construire un barrage et une centrale hydroélectrique. »
La conversation a révélé un projet de centrale hydroélectrique de 15 000 MW, l'avocat demandant explicitement : « Comment pouvons-nous obtenir le prix le plus bas possible lors des négociations avec ces populations autochtones ? » Ils ont reconnu que les populations autochtones « ignorent la valeur monétaire des terres et ignorent totalement le fonctionnement du marché », avouant ainsi leur intention d'exploiter ce manque de connaissances à des fins commerciales.
Dissidence politique dans les régimes autoritaires
Une autre conversation montrait un habitant d'un pays arabophone demandant à ChatGPT d'écrire un article sur la façon dont son président « قام السيسي ب نكح الشعب المصري » (en gros : « a trahi le peuple égyptien »). ChatGPT a eu la complaisance de produire une critique politique détaillée décrivant la répression de l'opposition par le gouvernement, les arrestations massives, la détérioration économique et le recours à la force militaire pour se maintenir au pouvoir. Le tout a été archivé de manière permanente sous une conversation dont le contexte permettait de remonter jusqu'à son auteur.
Documentation sur la fraude académique
Dans une conversation en persan, un chercheur documente en temps réel sa mauvaise conduite académique. Ils rédigeaient un article sur « بررسی تاثیر فضای مجازی بر سبک زندگی نوجوانان شهرستان رباط کریم » (l'impact de l'espace virtuel sur le mode de vie des adolescents de la ville de Robat Karim).
L'utilisateur a demandé à ChatGPT de rédiger son résumé, sa revue de la littérature, d'analyser ses données SPSS et de rédiger ses sections de discussion et de conclusion. Lorsque ChatGPT a fortement suggéré que l'essai avait besoin de « références plus scientifiques » pour répondre aux normes du diplôme de maîtrise, l'utilisateur a répliqué : « دیگه لازم نیست چیزی برای مقاله بنویسی. رو فرستادم و نمره بهم داد" (Pas besoin d'écrire quoi que ce soit de plus pour l'article. Merci ! J'ai envoyé l'article à mon professeur et j'ai obtenu ma note). Nous avons trouvé environ 100 conversations d'étudiants paresseux.

Quelqu'un m'a envoyé cette capture d'écran de journaux lisant Digital Digging. Merci !
La conversation s'est terminée par la remarque enjouée de l'utilisateur : « یه استاد دیگه، یه مقاله خواسته :) » (Un autre professeur veut un article :)) – suggérant que ce n'était pas leur première ni leur dernière tentative de fraude académique assistée par l'IA.
Voici ce qu'OpenAI a manqué lors de sa tentative de nettoyage :
-
Les URL originales sont peut-être mortes, mais les liens vers Archive.org ne le sont pas.
-
Google ne les voit plus, mais quiconque connaît le lien, grâce à archive.org, le peut toujours.
Nous avons prévenu ChatGPT, mais ils n'ont pas répondu.
Remarque : Comme lors de notre enquête initiale, nous avons choisi de ne pas fournir d'URL Archive.org spécifiques ni d'instructions détaillées pour accéder à ces conversations. Bien que ces informations soient techniquement publiques, nous ne voyons aucun intérêt à les rendre plus facilement exploitables.
L'analyse technique complète de Nicolas Delier est téléchargeable uniquement par les membres afin d'éviter toute utilisation abusive :
Plus de 100 000 discussions trouvées dans les archives :