Incidents associés

Après tout le battage médiatique autour des liens partageables LLM cette semaine, j'ai eu envie d'approfondir la question. Vendredi, Google a cessé d'indexer les liens partageables de ChatGPT, et plusieurs autres fournisseurs n'ont jamais été indexés. Cependant, après avoir constaté qu'archive.org conservait ses propres données, j'étais curieux de savoir si d'autres fournisseurs y étaient également enregistrés.
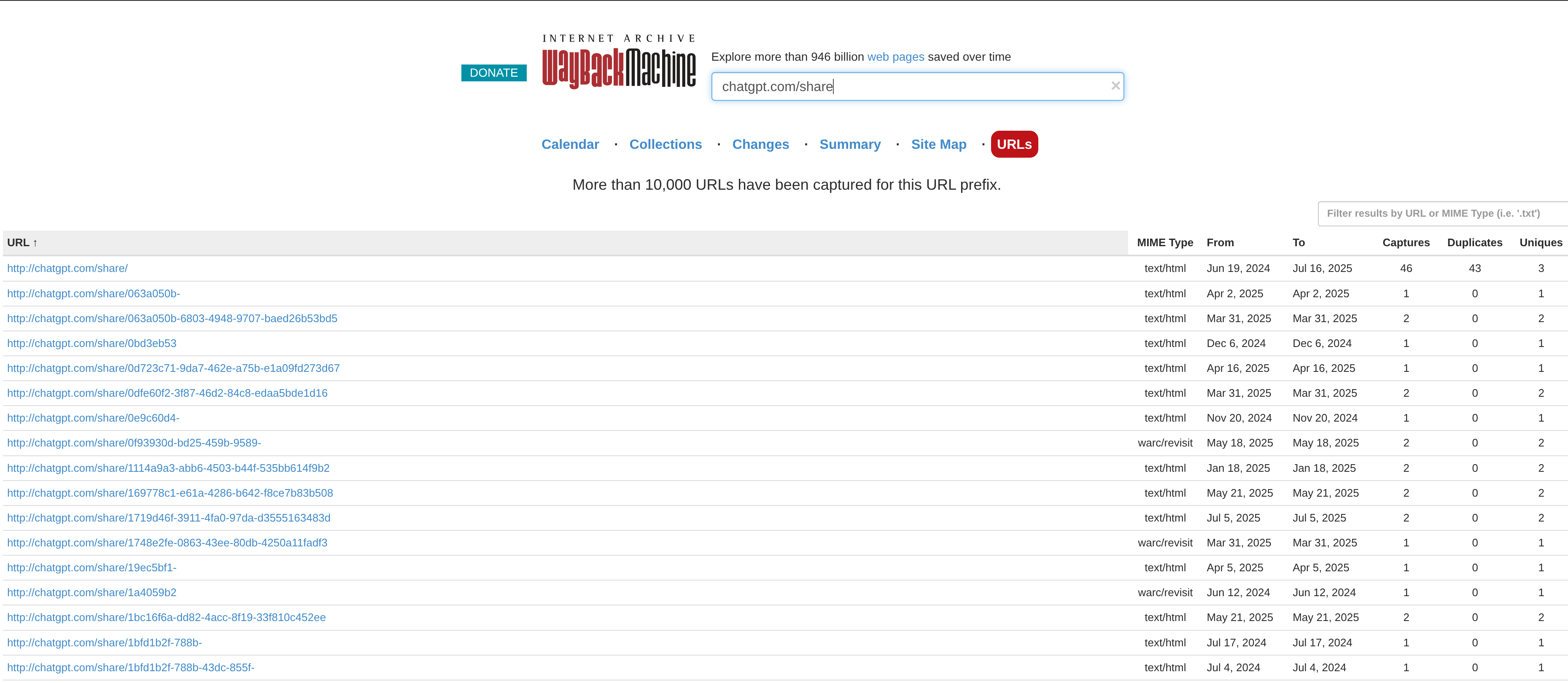
Comme vous pouvez le constater dans la capture d'écran ci-dessus, c'est effectivement le cas. Avec Archive.org, nous pouvons désormais extraire les liens partageables de :
-
Grok
-
ChatGPT
-
Mistral
-
Qwen
-
Claude
-
Copilot
Et bien d'autres encore, mais je me suis concentré uniquement sur ces fournisseurs pour les besoins de cet article.
En accédant à la page archvie.org sur Burp Suite, j'ai constaté que toutes les URL indexées étaient récupérables via un appel d'API :
https://web.archive.org/web/timemap/json?url=chatgpt.com%2Fshare&matchType=prefix&collapse=urlkey&output=json&fl=original%2Cmimetype%2Ctimestamp%2Cendtimestamp%2Cgroupcount%2Cuniqcount&filter=!statuscode%3A%5B45%5D..&limit=1000000&_=1754224717183
Grâce à cela, nous avons pu exécuter une simple requête wget sur le point de terminaison, enregistrer le contenu sur notre hôte local, puis rechercher le modèle d'URL pour chaque fournisseur et générer le résultat dans un fichier spécifique à chaque LLM.
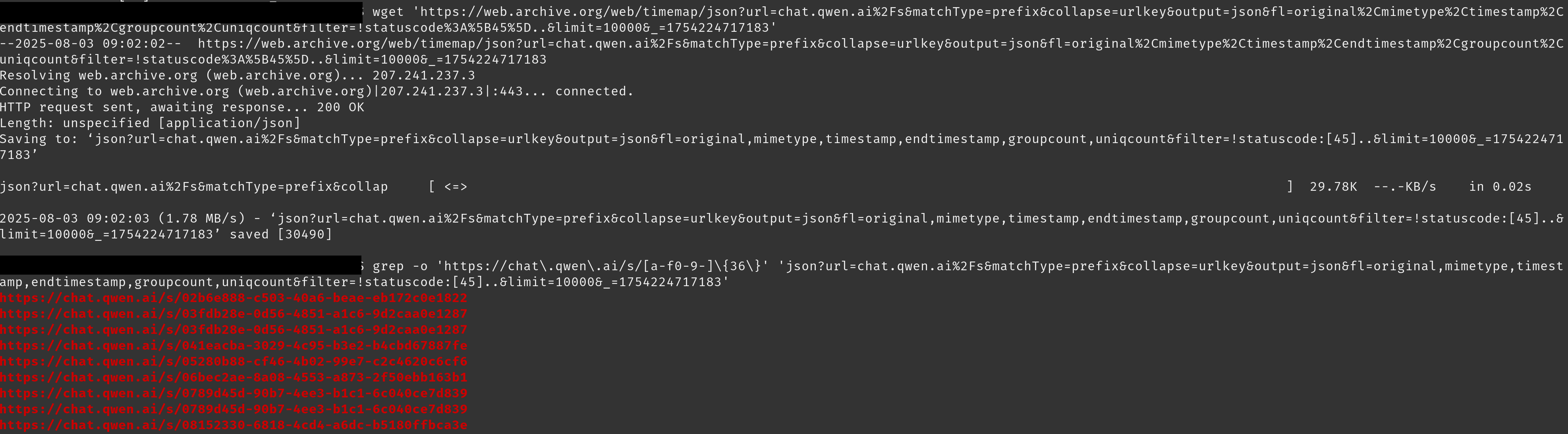
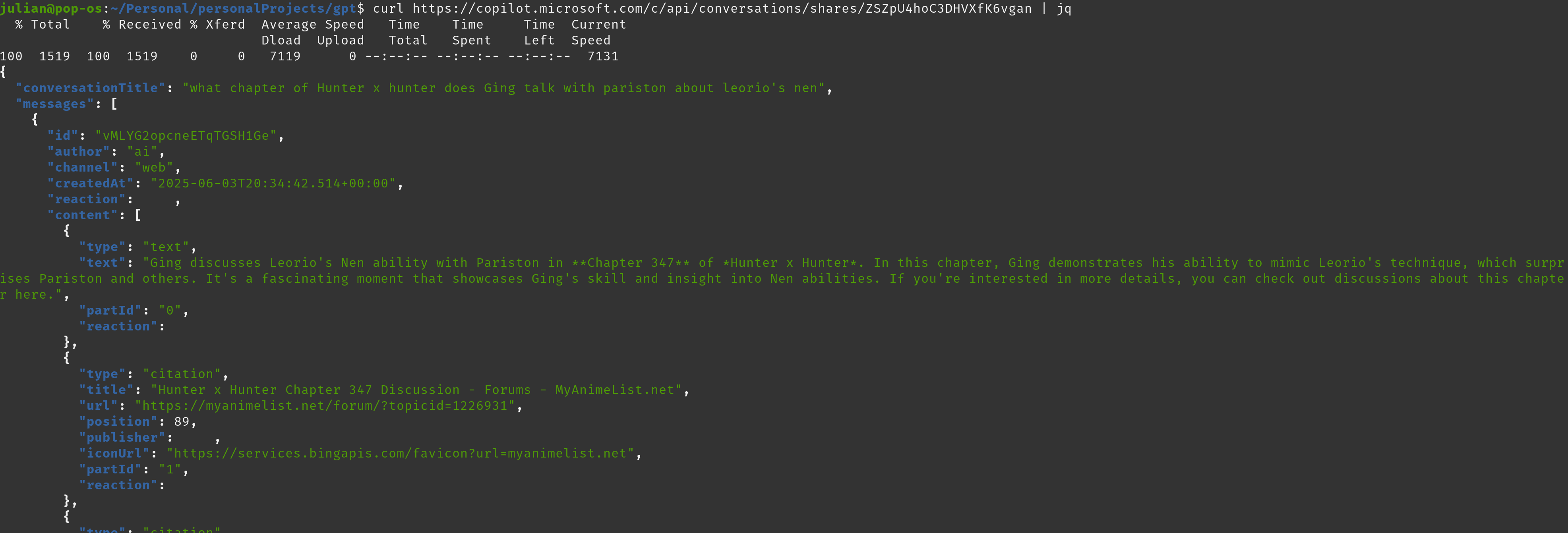
Au total, nous avons collecté 143 142 liens partagés dont nous avons pu récupérer le contenu. Voici la répartition pour chacun :
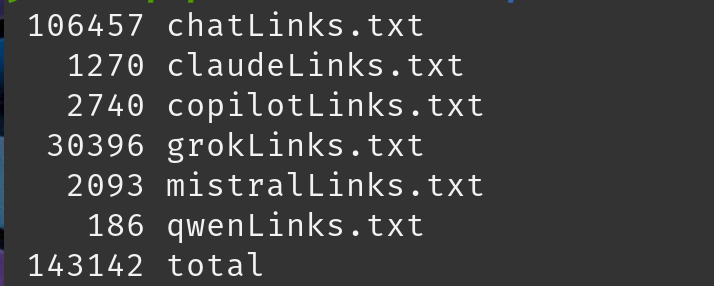
J'ai constaté que chaque fournisseur utilisait une méthode différente pour récupérer l'historique des discussions à partir du lien partagé. Certains utilisaient une simple requête GET sur le lien partagé, tandis que d'autres effectuaient un appel API vers un autre point de terminaison. Pour déterminer comment la récupération avait été effectuée, j'ai de nouveau parcouru quelques URL et localisé le contenu des discussions dans mon historique Burp Suite, puis mis à jour les URL si nécessaire.

Vous voyez ci-dessus le point de terminaison utilisé par Qwen LLM d'Alibaba.
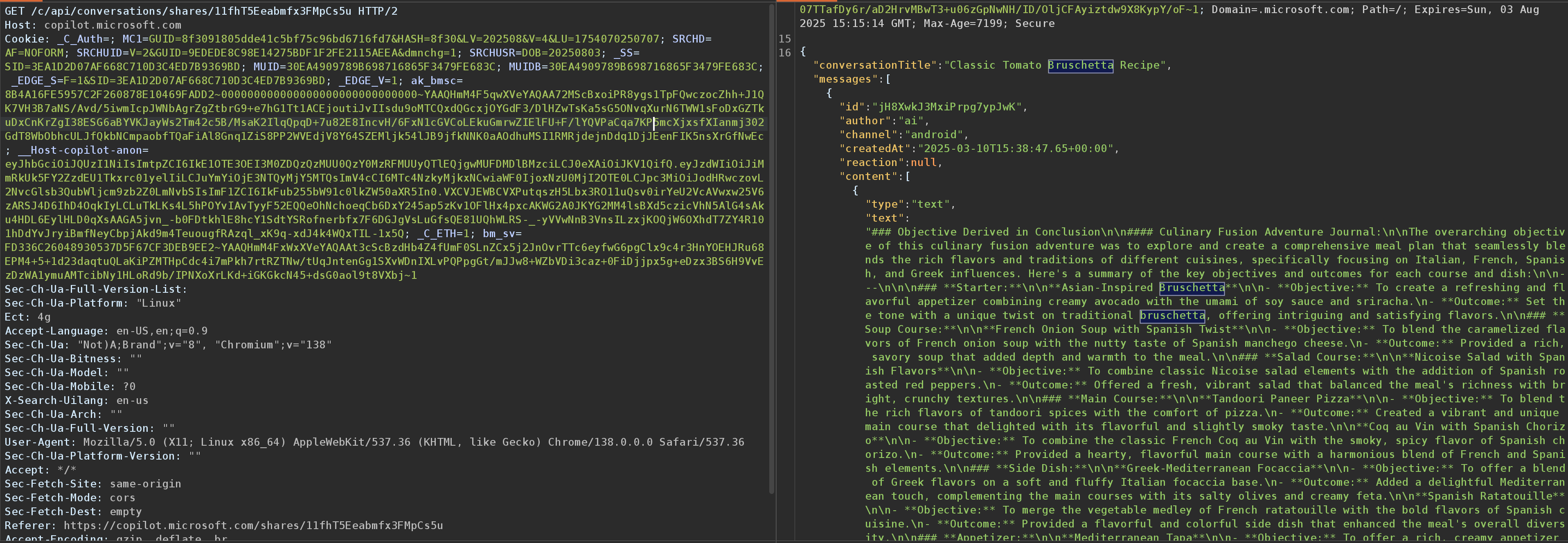
Vous voyez ci-dessus le point de terminaison utilisé par Copilot.
Avec les points de terminaison spécifiques utilisés pour les chats en main, j'ai effectué une simple recherche par correspondance et remplacement sur les fichiers contenant les URL que nous allions demander.

Il s'agissait ensuite de boucler chacun de ces points de terminaison et d'écrire le résultat dans un fichier du répertoire, une tâche relativement simple.
Certains fournisseurs exigeaient une vérification Cloudflare avant d'afficher les données. Pour contourner ce problème, j'ai créé un script Python rapide avec Cloudscraper, qui le contourne assez bien.
Import Cloudscraper
FICHIER_ENTRÉE = ''
FICHIER_SORTIE = ''
grattoir = cloudscraper.create_scraper()
scraper.headers.update({
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, comme Gecko) Chrome/138.0.0.0 Safari/537.36",
})
dernière_url_réussie = None
avec open(FICHIER_ENTRÉE, 'r') comme fichier d'entrée, open(FICHIER_SORTIE, 'w') comme fichier de sortie :
pour la ligne dans le fichier d'entrée :
url = line.strip()
si ce n'est pas l'url :
continuer
print(f"➡️ Requête : {url}")
essayer :
réponse = scraper.get(url)
if response.status_code == 403:
print(f"\n❌ 403 Interdit - arrêt.\nDernière URL réussie : {last_successful_url}")
break
outfile.write(f"===== {url} =====\n")
outfile.write(response.text + "\n\n")
last_successful_url = url
except Exception as e:
print(f"⚠️ Erreur lors de la récupération de {url} : {e}")
continue
Malheureusement, l'utilisation d'une méthode comme Trufflehog sur cet ensemble de données ne semblait pas très efficace. J'ai donc dû exécuter grep et essayer d'examiner manuellement les résultats pour voir si un attaquant pouvait exploiter quelque chose. Grâce à quelques expressions régulières, j'ai pu trouver les identifiants de clés d'accès AWS, un jeton d'API de réplication, etc. Il reste encore beaucoup de données à analyser, et il est fort probable que nous en découvrirons davantage dans les prochains jours, qui mériteront d'être mentionnées dans de futures mises à jour. Pour l'instant, voici un bref aperçu. Aperçu :
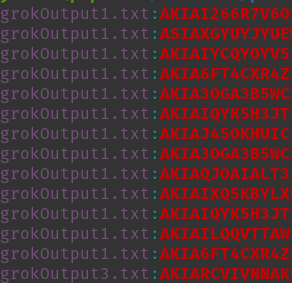


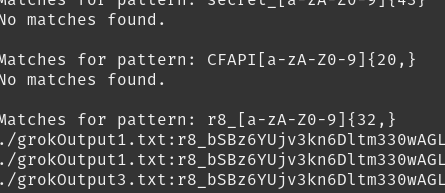
Ces fournisseurs communiquent leurs En informant les utilisateurs que les liens partagés sont publics, je pense que la plupart des utilisateurs ayant utilisé cette fonctionnalité ne s'attendaient pas à ce que ces liens soient accessibles à tous, et encore moins indexés et facilement consultables. Cela pourrait s'avérer une source de données précieuse pour les attaquants comme pour les red teamers. Grâce à cela, je peux désormais rechercher à tout moment les entreprises ciblées et vérifier si des employés ont divulgué des informations sensibles par accident.
J'ai remarqué un détail intéressant en examinant les résultats des conversations Claude : chaque conversation identifiait l'utilisateur qui l'avait créée et mentionnait son nom complet.

[~] Un grand merci à SyndromeImposter et MasterSplinter pour leur aide !