Incidents associés

Il y a trois jours, Drew DeVault, fondateur et PDG de SourceHut, a publié un article de blog intitulé « Arrêtez de me facturer vos coûts directement », dans lequel il se plaignait que les entreprises de LLM exploraient les données sans respecter le fichier robosts.txt, provoquant de graves pannes de SourceHut.

J'ai répondu : « Intéressant ! » et je suis passé à autre chose.
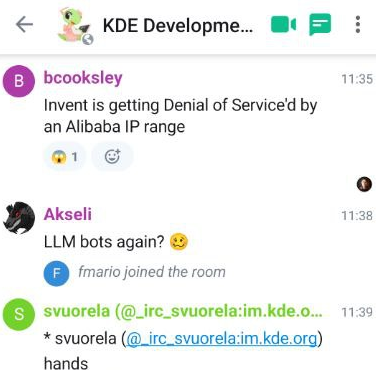
Hier matin, l'infrastructure GitLab de KDE a été submergée par un autre robot d'exploration IA, dont les adresses IP provenaient d'une plage Alibaba. GitLab est alors devenu temporairement inaccessible aux développeurs KDE.
J'ai ensuite découvert qu'il y a une semaine, une fille animée est apparue sur l'instance GitLab de GNOME, au moment du chargement de la page. Il s'avère qu'il s'agit de la page de chargement par défaut d'Anubis, un challenger de preuve de travail qui bloque les scrapers d'IA responsables des pannes.
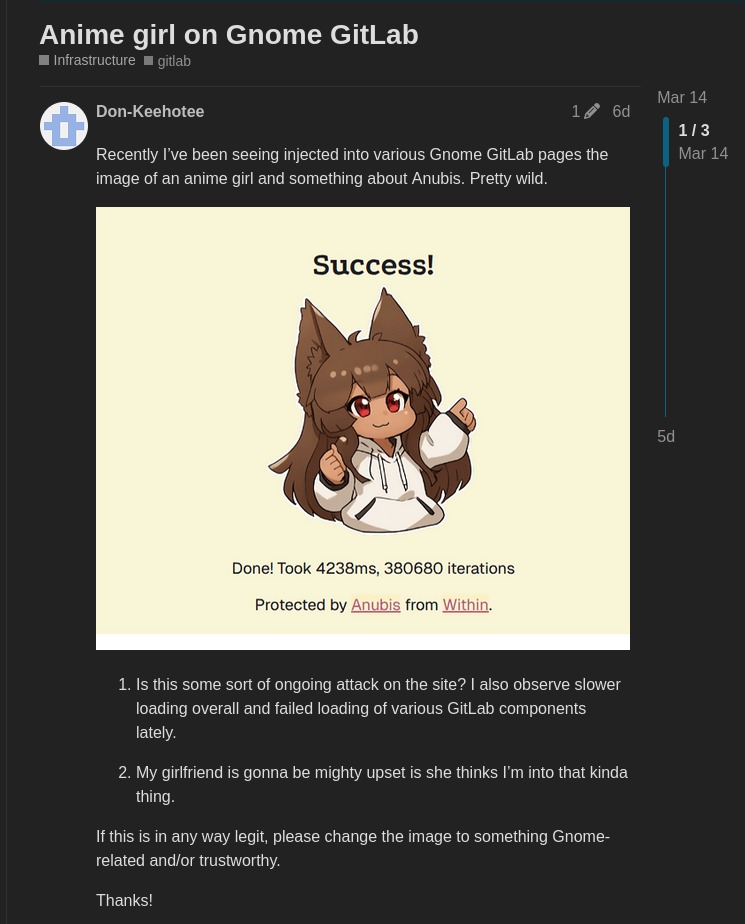
Il est désormais clair que ce n'est pas une coïncidence. Les robots d'exploration IA deviennent de plus en plus agressifs et, comme les logiciels libres et open source reposent sur la collaboration publique, contrairement aux entreprises privées, cela représente une charge supplémentaire pour les communautés open source.
Essayons donc d'obtenir plus de détails, en revenant à l'article de Drew. Selon lui, les robots d'exploration LLM ne respectent pas les exigences du fichier robots.txt et incluent des points de terminaison coûteux comme git blame, chaque page de chaque journal Git et chaque commit de votre dépôt. Pour ce faire, ils utilisent des agents utilisateurs aléatoires provenant de dizaines de milliers d'adresses IP, chacun n'effectuant qu'une seule requête HTTP, essayant de se fondre dans le trafic utilisateur.

De ce fait, il est difficile de proposer des mesures d'atténuation efficaces. Drew indique que plusieurs tâches prioritaires ont été retardées de plusieurs semaines, voire de plusieurs mois, en raison de ces interruptions, que des utilisateurs ont parfois été affectés (car il est difficile de distinguer les robots des humains) et, bien sûr, que cela entraîne des pannes occasionnelles de SourceHut.

Drew ne fait pas ici de distinction entre les entreprises d'IA qui respectent plus ou moins les fichiers robots.txt, ou qui sont plus précises dans leurs rapports sur les agents utilisateurs ; nous pourrons approfondir ce sujet ultérieurement.
Enfin, Drew souligne qu'il ne s'agit pas d'un problème isolé. Il déclare :
Tous mes amis administrateurs système sont confrontés aux mêmes problèmes, [et] chaque fois que je m'assois pour boire un verre ou dîner avec eux, nous nous plaignons rapidement des bots. [...] Le désespoir dans ces conversations est palpable.

Ce qui me ramène aux problèmes rencontrés hier sur GitLab de KDE. Selon Ben, membre de l'équipe d'administration système de KDE, toutes les adresses IP responsables de ce DDoS prétendaient être MS Edge et appartenaient à des entreprises chinoises d'IA. Il mentionne que les opérateurs LLM occidentaux, comme OpenAI et Anthropic, avaient au moins défini une autorisation d'utilisateur appropriée. Nous y reviendrons plus tard.
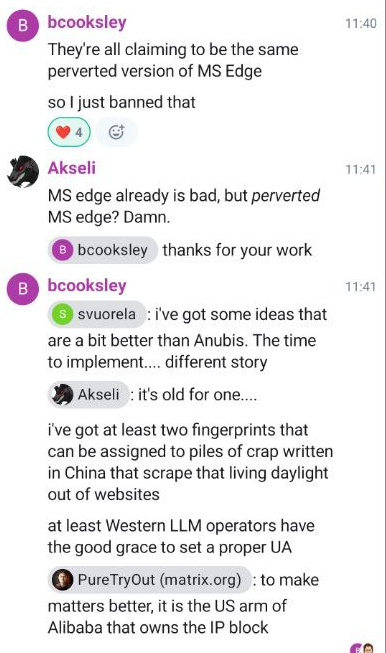
La solution, pour l'instant, consistait à bannir la version d'Edge que les bots prétendaient être, même s'il est difficile de croire que ce soit une solution définitive ; ces bots semblent en effet désireux de changer d'agent utilisateur pour s'intégrer au mieux.
En effet, GNOME rencontre des problèmes depuis novembre dernier ; comme solution temporaire, ils avaient limité le nombre d'utilisateurs non connectés qui ne pouvaient pas voir les requêtes de fusion et les commits, ce qui, bien sûr, posait également des problèmes aux invités humains.
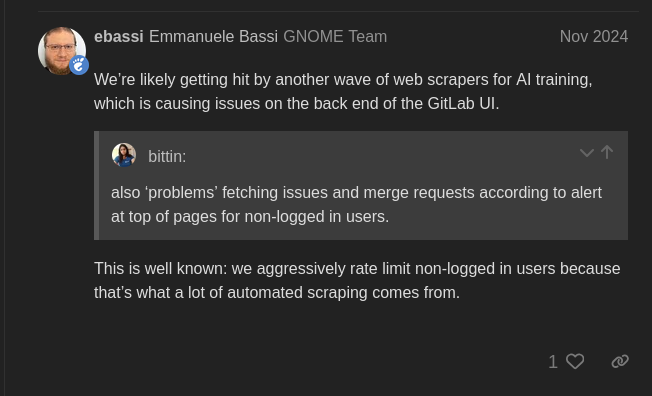
La solution finalement retenue a été de passer à Anubis. Cette page représente un défi pour le navigateur, qui doit alors effectuer des calculs et présenter la solution au serveur. Si la solution est correcte, vous avez accès au site web.
Selon le développeur, ce projet est « une sorte de réponse nucléaire, mais les robots IA scrapeurs qui scrapent si agressivement m'ont forcé la main. Je déteste devoir faire ça, mais c'est ce que nous réserve l'Internet moderne, car les robots ne se conforment pas à des normes comme robots.txt, même lorsqu'ils le prétendent ».
Cependant, cela pose également des problèmes aux utilisateurs. Lorsque plusieurs personnes ouvrent le lien depuis le même endroit, il peut arriver qu'elles se voient proposer un exercice plus difficile, qui prendra un certain temps. Un utilisateur signale un retard d'une minute, tandis qu'un autre, depuis son téléphone, doit attendre environ deux minutes.
Pourquoi ? Eh bien, un lien GitLab a été collé dans une salle de discussion ! De même, la même chose s'est produite lorsque la demande de fusion Triple Buffering GNOME a été publiée sur Hacker News, ce qui a suscité beaucoup d'intérêt. Comme l'a indiqué le développeur, c'est une option radicale pour les robots d'exploration, mais elle a aussi des conséquences humaines.
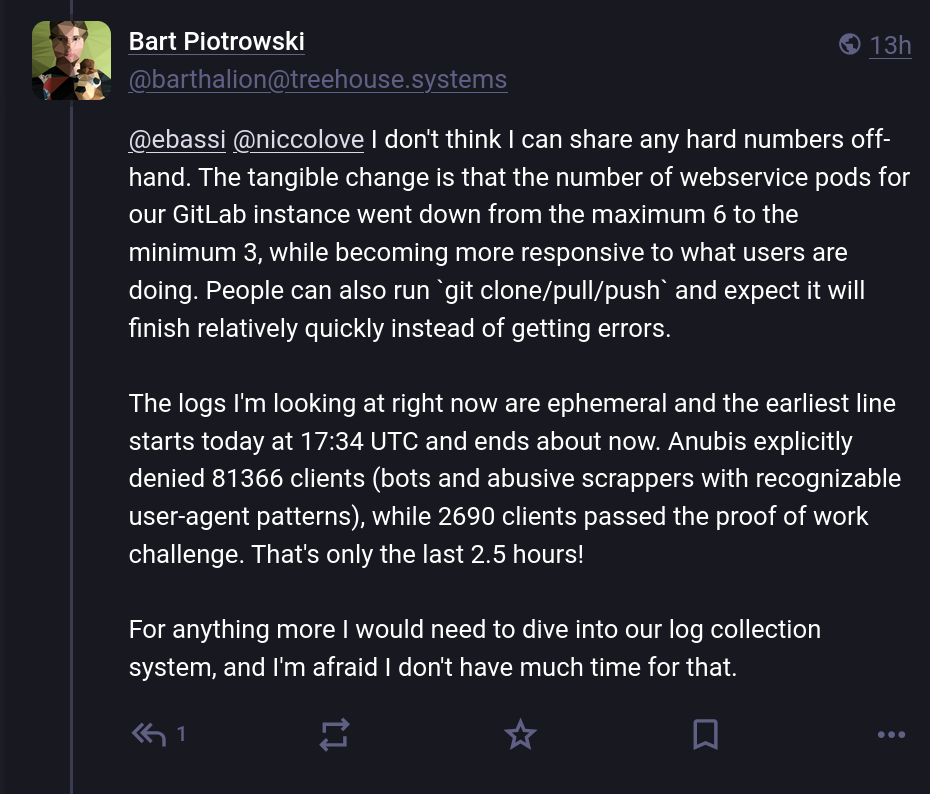
Sur Mastodon, un administrateur système GNOME, Bart Piotrowski, a aimablement partagé quelques chiffres pour permettre au public de bien comprendre l'ampleur du problème. Selon lui, en environ deux heures et demie, 81 000 requêtes ont été reçues, et parmi celles-ci, seules 3 % ont passé la preuve de travail d'Anubi, ce qui laisse penser que 97 % du trafic provient de bots – un chiffre aberrant !
Cela dit, au moins, ça a fonctionné. D'autres organisations ont plus de mal à gérer ces scrapers.
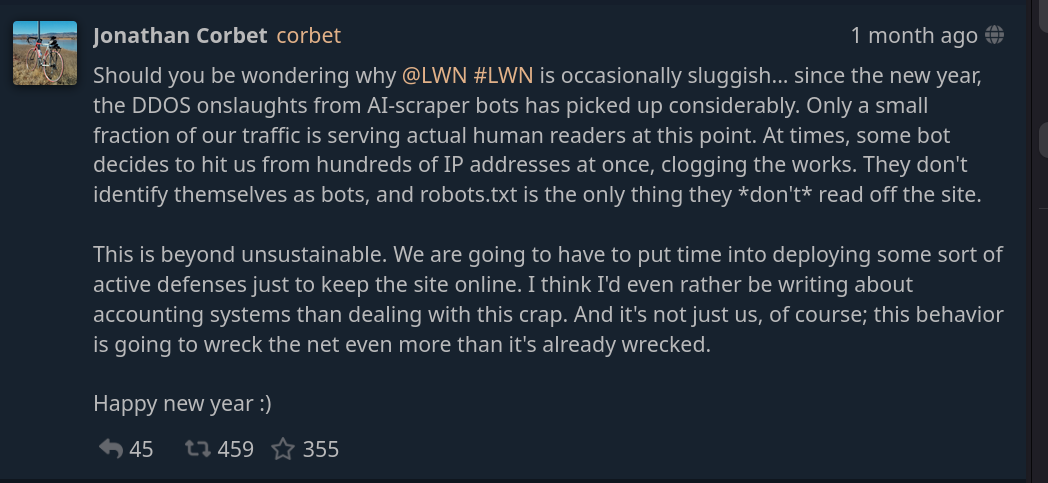
À titre d'exemple, Jonathan Corbet, directeur de la source d'information LWN, spécialisée dans les logiciels libres et open source, avertit les utilisateurs que le site web pourrait être « occasionnellement lent »… en raison d'attaques DDoS provoquées par des robots scrapers IA. Il affirme que « seule une petite fraction de notre trafic est destinée à de véritables lecteurs humains », et qu'à un moment donné, les robots « décident de nous contacter depuis des centaines d'adresses IP à la fois. […] Ils ne s'identifient pas comme des robots, et le fichier robots.txt est le seul élément qu'ils ne lisent pas sur le site ».
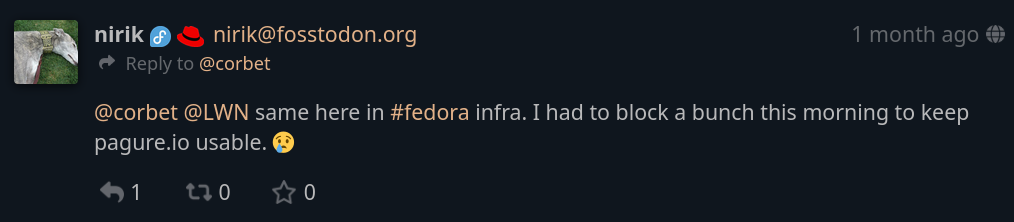
De nombreux internautes ont exprimé leur solidarité, notamment Kevin Fenzi, administrateur système du projet Fedora. Ils ont également rencontré des problèmes avec les scrapers d'IA : il y a un mois, ils ont dû se battre pour maintenir pagure.io en vie :
Cependant, la situation a empiré avec le temps, et ils ont dû bloquer plusieurs sous-réseaux, ce qui a également eu des répercussions sur de nombreux utilisateurs réels. En désespoir de cause, Kevin a décidé d'interdire l'accès à tout le Brésil pour que tout fonctionne à nouveau ; à ma connaissance, cette interdiction est toujours en vigueur, et il est difficile de trouver une solution à long terme.

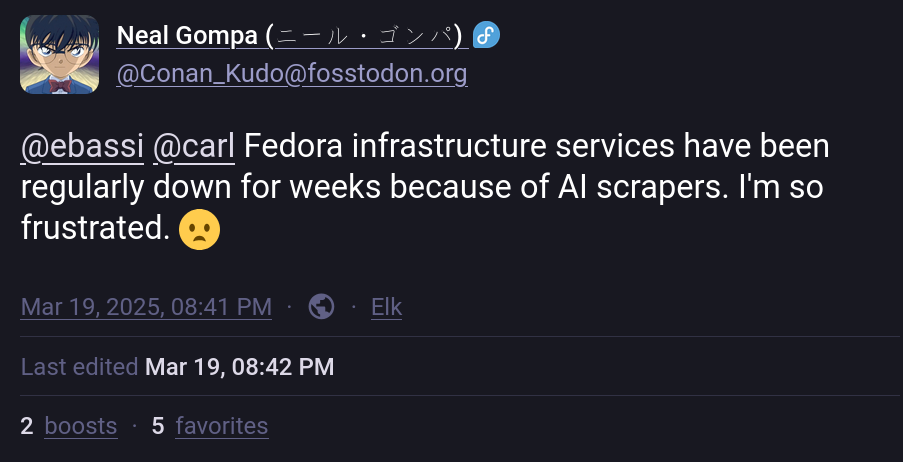
Et, comme le souligne Neal Gompa, même bloquer un pays entier ne suffit pas, et apparemment, l'infrastructure de Fedora est « régulièrement hors service depuis des semaines » à cause des scrapers d'IA.
Inkscape a également été touché par ce problème la semaine dernière. Selon Martin Owens, il ne s'agit pas de « l'attaque DDoS chinoise habituelle de l'année dernière, mais d'un ensemble d'entreprises qui ont commencé à ignorer notre configuration de robot d'indexation et à usurper les informations de leur navigateur. J'ai maintenant une liste de blocage Prodigius. Si vous travaillez pour une grande entreprise spécialisée dans l'IA, vous risquez de ne plus avoir accès à notre site web. »
Et Martin n'est pas le seul développeur à avoir créé une « liste de blocage prodigieuse ». Même BigGrizzly, de Frama Software, a été inondé par un robot d'indexation malveillant et a créé une liste de 460 000 adresses IP contenant des agents utilisateurs usurpés à bannir ; il propose de partager cette liste.
Le projet « ai.robots.txt » est une tentative plus complète de ce type. Il s'agit d'une liste ouverte de robots d'exploration web associés à des entreprises d'IA. Ils proposent un fichier robots.txt implémentant le protocole d'exclusion des robots et un fichier .htaccess qui renvoie une page d'erreur à chaque requête d'un robot d'exploration d'IA figurant sur leur liste.
On peut obtenir plus de chiffres sur les robots d'exploration en remontant quelques mois en arrière. Voici un article de Dennis Schubert sur l'infrastructure de Diaspora (un réseau social décentralisé Open Source), où il explique que « consulter les journaux de trafic l'a mis en colère de façon impressionnante ».
Dans son article, il affirme qu'un quart de son trafic web provient de bots utilisant un agent utilisateur OpenAI, 15 % d'Amazon, 4,3 % d'Anthropic, etc. Au total, environ 70 % des requêtes proviennent d'entreprises d'IA.

Selon lui,
ils ne se contentent pas d'explorer une page une fois pour passer à autre chose. Oh non, ils reviennent toutes les 6 heures, pourquoi pas ? Ils se fichent complètement de « robots.txt », pourquoi le feraient-ils ? [...] Si vous essayez de les limiter, ils changeront constamment d'adresse IP. Si vous essayez de les bloquer par chaîne d'agent utilisateur, ils passeront simplement à une chaîne d'agent utilisateur non liée à un robot (non, vraiment). C'est une véritable attaque DDoS sur Internet.

Le projet Read the Docs avance un chiffre similaire. Dans un article de blog intitulé « Les robots d'exploration IA doivent être plus respectueux », ils affirment que le blocage de tous les robots d'exploration IA a immédiatement réduit leur trafic de 75 %, passant de 800 Go à 200 Go par jour. Cela a permis au projet d'économiser environ 1 500 $ par mois.

Le reste de l'article est également assez impressionnant : il est question de robots d'exploration qui téléchargent des dizaines de téraoctets de données en quelques jours, voire plus. Il est difficile de les bloquer complètement, car ils utilisent différentes adresses IP.

Je me demande quelle part de ce travail est consacrée à la récupération de données d'entraînement, et quelle part est plutôt liée à la fonction de recherche proposée par la plupart des LLM ; néanmoins, selon Schubert, les robots d'exploration « normaux » comme ceux de Google et de Bing ne représentent qu'une fraction d'un point de pourcentage, ce qui suggère que d'autres entreprises abusent effectivement de leur pouvoir sur le web.
Mais il ne s'agit pas seulement de scrapers, sinon j'aurais appelé cela « scrapers d'IA », et non « entreprises d'IA ». Un autre problème auquel la communauté Open Source est confrontée est celui des rapports de bugs générés par l'IA, par exemple.
Ce phénomène a été signalé pour la première fois par Daniel Stenberg, du projet Curl, dans un article de blog intitulé « Le I de LLM signifie Intelligence ». Curl propose un programme de bug bounty, mais l'équipe a récemment constaté que de nombreux rapports de bugs sont générés par l'IA. Ces rapports semblent crédibles et leur vérification prend beaucoup de temps aux développeurs, mais ils contiennent aussi les hallucinations typiques des IA.
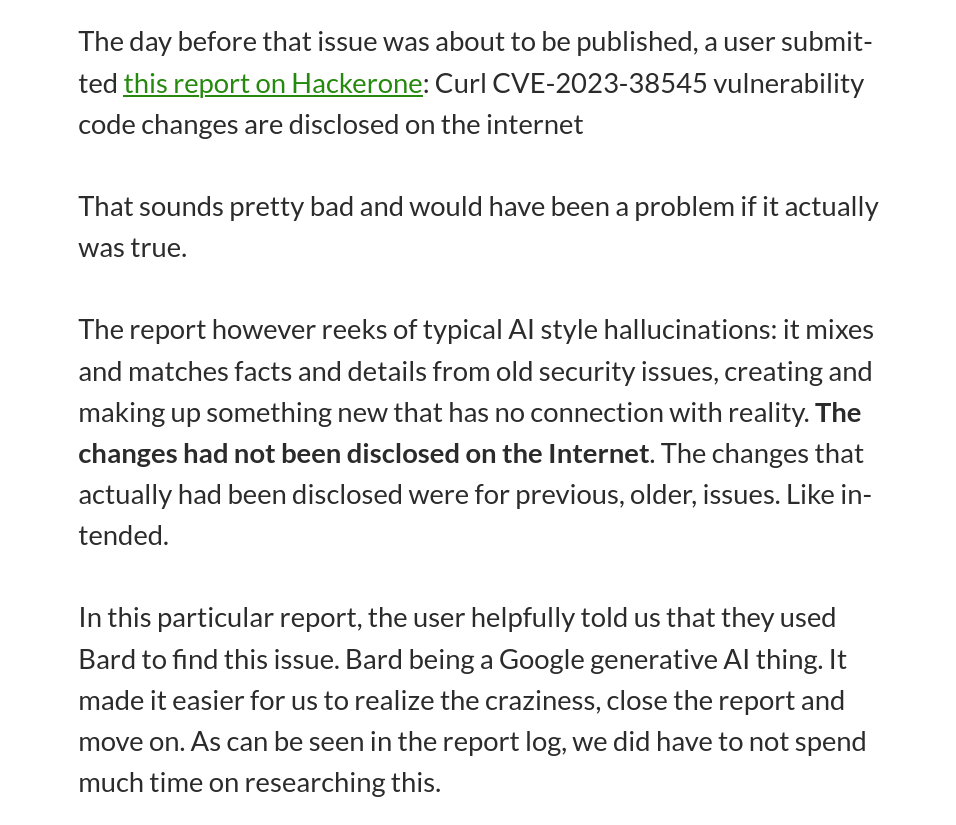
C'est assez fou de devoir analyser son propre code parce qu'un rapport de bug vous indique avec certitude qu'il y a un problème de sécurité critique à corriger, et… de ne pas le trouver, car tout le problème n'est qu'une hallucination de l'IA.

Un problème similaire a été signalé par Seth Larson, membre de l'équipe de tri des rapports de sécurité pour CPython, pip, urllib3, Requests, etc. Il déclare :
J'ai récemment constaté une augmentation des rapports de sécurité de très mauvaise qualité, contenant du spam et des hallucinations de LLM, concernant les projets open source. Le problème se pose à l'ère des LLM : ces rapports semblent à première vue potentiellement légitimes et nécessitent donc du temps pour être réfutés.

Il s'agit d'un problème majeur. Comme il le souligne, répondre aux rapports de sécurité coûte cher, et répondre à des rapports de bugs inventés mais crédibles représente une charge de travail supplémentaire considérable pour les mainteneurs, ce qui pourrait les pousser à quitter le monde de l'Open Source.

L'article se termine par une demande : veuillez ne pas utiliser l'IA ou les systèmes LLM pour détecter les vulnérabilités. Il précise : « Ces systèmes actuels ne peuvent pas comprendre le code. Trouver des vulnérabilités de sécurité nécessite de comprendre le code et de comprendre des concepts humains tels que l'intention, l'usage courant et le contexte. »

Je tiens à souligner une fois de plus que ces problèmes ont un impact disproportionné sur le monde des logiciels libres et open source. Non seulement les projets open source disposent souvent de moins de ressources que les produits commerciaux, mais, s'agissant de projets communautaires, une grande partie de leur infrastructure est publique et donc vulnérable aux robots d'exploration et aux rapports de bugs ou problèmes générés par l'IA.