Incidents associés

🧵 Quelques réflexions sur la récente sortie de Galactica par @MetaAI (tout ici est mon opinion personnelle) 👀
Commençons par le positif / Ce qui s'est bien passé
{kind=link}
[1] Le modèle a été publié et Open Source*
Contrairement à la tendance selon laquelle les recherches très intéressantes sont fermées ou simplement accessibles via des API payantes, en ouvrant les modèles et en s'appuyant sur les outils de système d'exploitation existants, l'évaluation peut être effectuée de manière fiable, transparente et ouverte [](https:// pbs.twimg.com/media/FiCEq0sVEAAwcJD.jpg)
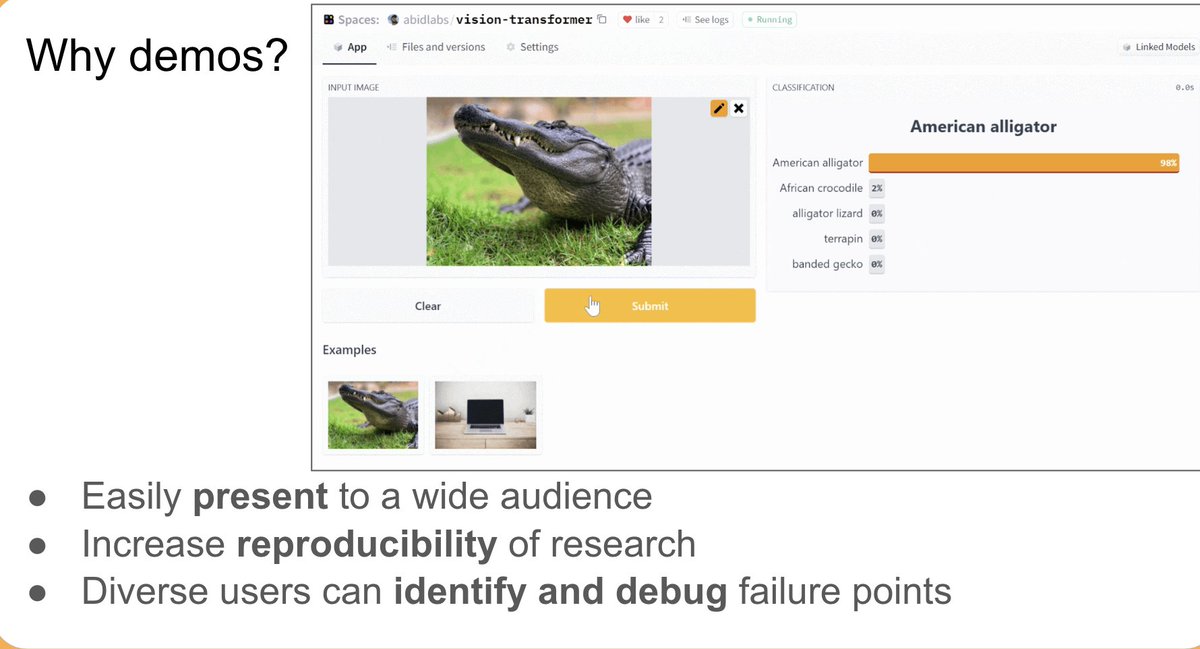
[2] Il y avait une démo avec la version**
Les démos permettent à un public beaucoup plus large de comprendre le fonctionnement des modèles. En ayant une démo avec la sortie, un public beaucoup plus diversifié peut explorer le modèle, identifier les points de défaillance, les nouveaux préjugés, etc.
{kind=link}
[3] Techniquement impressionnant !
Gros bravo là où c'est mérité. Le modèle est techniquement impressionnant, avec de solides performances dans différents benchmarks, une précision de citation de 50 %, la génération de formules latex et SMILES, et plus encore.
{kind=link}
/ Qu'est-ce qui n'a pas fonctionné ? [1] Hype dans les annonces, mêlant produit final et recherche. L'annonce et la page parlent de "résoudre" la surcharge d'informations en science et que cela peut être utilisé pour écrire du code scientifique.
Ce style de communication est très trompeur et entraînera une mauvaise utilisation
{kind=link}
[2] Filtre de sécurité dans la démonstration d'effacement des communautés
Bien que j'imagine que c'était bien intentionné, le filtre de sécurité (non transparent) a supprimé le contenu sur la théorie queer et le SIDA
OpenAI a fait de même avec Dalle 2 et a également reçu des réactions négatives
Le filtre de sécurité - Censure le contenu sur les minorités, marginalisant davantage les gens - Contredit l'idée de stocker et de raisonner sur les connaissances scientifiques
Voir plus à
https://twitter.com/mmitchell_ai/status/1593351384573038592?s=20&t=8W0DbEqaln7hDKPY_xGhYQ
[3] Les cas d'utilisation n'étaient pas clairs, non documentés ou trompeurs
Les limitations indiquées dans le site et le document sont assez limitées et quelque peu floues. Le document indique que "nous ne conseillerions pas de l'utiliser pour des tâches qui nécessitent ce type de connaissances car ce n'est pas le cas d'utilisation prévu".
{kind=link}
Il existe également une carte modèle quelque peu cachée dans github.com/paperswithcode…
Mais je trouve encore une fois que la documentation sur les limites, les biais et les cas d'utilisation est trop limitée, compte tenu de la puissance du modèle.
[4] Démo Même si avoir une démo était bien, elle aurait pu faire un meilleur travail en - Ajoutant des clauses de non-responsabilité plus claires - Modification de l'interface utilisateur pour qu'elle ressemble moins à des vrais papiers - Disposant d'un mécanisme pour identifier ce contenu généré
- Ajout d'un moyen de signaler le contenu toxique et erroné
[5] En lien avec le point précédent, la communauté n'a pas eu la possibilité de discuter et de signaler des problèmes, uniquement via Twitter.
Sur @huggingface, nous avons appris qu'il est essentiel de créer un espace pour des discussions publiques, ouvertes et transparentes sur les modèles.
thread#showTweet data-screenname=osanseviero data-tweet=1594420190619439104 dir=auto> En tant que tel, les utilisateurs disposent de mécanismes pour signaler les sorties générées par la démo, explorer le code utilisé pour la créer et discuter avec la communauté du travail de manière ouverte et transparente .
Alors TL; DR, qu'est-ce qui pourrait être mieux fait - Des cas d'utilisation et des limitations plus explicites - Une meilleure documentation du modèle - Considérez les licences OpenRAIL, qui plongent dans les cas d'utilisation beaucoup plus que les licences logicielles classiques