Incidents associés
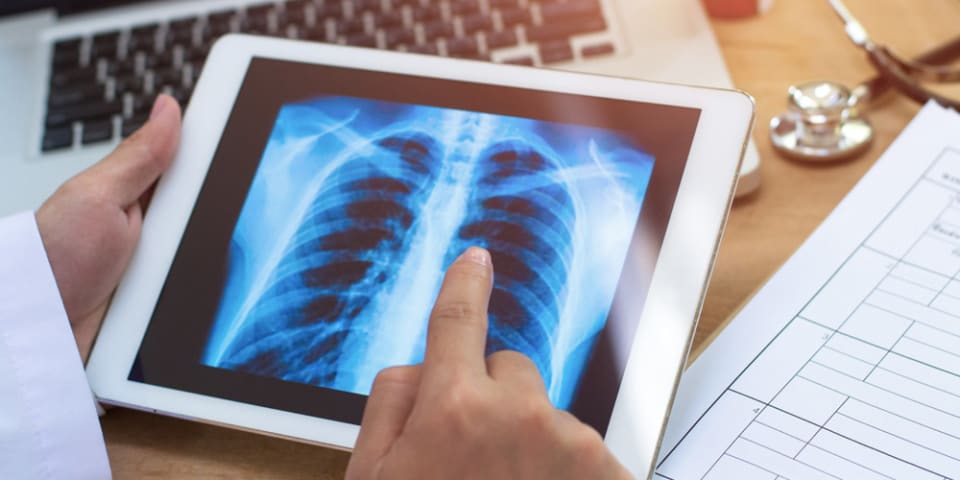
Google et des startups comme Qure.ai, Aidoc et DarwinAI développent des systèmes d'IA et d'apprentissage automatique qui classent les radiographies pulmonaires pour aider à identifier des conditions telles que les fractures et les poumons effondrés. Plusieurs hôpitaux, dont Mount Sinai, ont piloté des algorithmes de vision par ordinateur qui analysent les scans de patients atteints du nouveau coronavirus. Mais des recherches de l'Université de Toronto, du Vector Institute et du MIT révèlent que les ensembles de données de radiographie pulmonaire utilisés pour former des modèles de diagnostic présentent un déséquilibre, les biaisant contre certains groupes de sexe, socio-économiques et raciaux.
En partie en raison d'une réticence à publier du code, des ensembles de données et des techniques, une grande partie des données utilisées aujourd'hui pour former des algorithmes d'IA pour diagnostiquer des maladies peuvent perpétuer les inégalités. Une équipe de scientifiques britanniques a découvert que presque tous les ensembles de données sur les maladies oculaires proviennent de patients d'Amérique du Nord, d'Europe et de Chine, ce qui signifie que les algorithmes de diagnostic des maladies oculaires sont moins sûrs de bien fonctionner pour les groupes raciaux des pays sous-représentés. Dans une autre étude, des chercheurs de l'Université de Stanford ont affirmé que la plupart des données américaines pour les études impliquant des utilisations médicales de l'IA proviennent de Californie, de New York et du Massachusetts. Une étude d'un algorithme du UnitedHealth Group a déterminé qu'il pouvait sous-estimer de moitié le nombre de patients noirs nécessitant des soins plus importants. Et un nombre croissant de travaux suggèrent que les algorithmes de détection du cancer de la peau ont tendance à être moins précis lorsqu'ils sont utilisés sur des patients noirs, en partie parce que les modèles d'IA sont formés principalement sur des images de patients à la peau claire. Les coauteurs de ce dernier article ont cherché à déterminer si les classificateurs d'IA à la pointe de la technologie formés sur des ensembles de données d'imagerie médicale publics étaient équitables dans différents sous-groupes de patients. Ils ont spécifiquement examiné MIMIC-CXR (qui contient plus de 370 000 images), CheXpert de Stanford (plus de 223 000 images), Chest-Xray des National Institutes of Health des États-Unis (plus de 112 000 images) et un ensemble des trois, dont les scans de plus de 129 000 les patients combinés sont étiquetés avec le sexe et la tranche d'âge de chaque patient. MIMIC-CXR contient également des données de type course et assurance; à l'exclusion de 100 000 images, l'ensemble de données précise si les patients sont asiatiques, noirs, hispaniques, blancs, amérindiens ou autres et s'ils bénéficient de Medicare, Medicaid ou d'une assurance privée. performances de classification de pointe, qui excluait la possibilité que toute disparité reflète simplement une mauvaise performance globale, les chercheurs ont calculé et identifié les disparités entre les étiquettes, les ensembles de données et les attributs. Ils ont constaté que les quatre ensembles de données contenaient des schémas «significatifs» de biais et de déséquilibre, les patientes souffrant de la plus grande disparité malgré le fait que la proportion de femmes n'était que légèrement inférieure à celle des hommes. Les patients blancs – la majorité, avec 67,6% de toutes les images radiographiques – étaient le sous-groupe le plus favorisé, où les patients hispaniques étaient les moins favorisés. Et les préjugés existaient contre les patients assurés par Medicaid, la population minoritaire avec seulement 8,98% des images radiographiques. Les classificateurs ont souvent fourni aux patients de Medicaid des diagnostics incorrects. Les chercheurs notent que leur étude présente des limites découlant de la nature des étiquettes dans les ensembles de données. Chaque étiquette a été extraite des rapports de radiologie à l'aide de techniques de traitement du langage naturel, ce qui signifie qu'une partie d'entre elles aurait pu être erronée. Les coauteurs admettent également que la qualité des appareils d'imagerie eux-mêmes, la région de la collecte de données et les données démographiques des patients sur chaque site de collecte pourraient avoir confondu les résultats.
Cependant, ils affirment que même l'implication d'un biais est suffisante pour justifier un examen plus approfondi des ensembles de données et de tous les modèles formés sur eux. "Les sous-groupes avec un sous-diagnostic chronique sont ceux qui subissent des déterminants sociaux de la santé plus négatifs, en particulier les femmes, les minorités et les personnes de faible statut socio-économique. Ces patients peuvent utiliser moins les services de santé que d'autres », ont écrit les chercheurs. "Il existe un certain nombre de raisons pour lesquelles les ensembles de données peuvent induire des disparités dans les algorithmes, des ensembles de données déséquilibrés aux différences de bruit statistique dans chaque groupe en passant par les différences d'accès aux soins de santé pour les patients de différents groupes... Bien que les techniques de" débiaisage "peuvent réduire les disparités, nous ne doit pas ignorer les biais importants inhérents aux grands ensembles de données publics existants. "Au-delà des défis de base des ensembles de données, les classificateurs qui manquent d'un examen par les pairs suffisant peuvent rencontrer des obstacles imprévus lorsqu'ils sont déployés dans le monde réel. Les scientifiques de Harvard ont découvert que les algorithmes formés pour reconnaître et classer les tomodensitogrammes pouvaient devenir biaisés pour numériser les formats de certains fabricants de machines de tomodensitométrie. Pendant ce temps, un livre blanc publié par Google a révélé les défis liés à la mise en œuvre d'un système de prédiction des maladies oculaires dans les hôpitaux thaïlandais, y compris les problèmes de précision des analyses. Et des études menées par des entreprises comme Babylon Health, une startup de télémédecine bien financée qui prétend être capable de trier une gamme de maladies à partir de SMS, ont été remises en question à plusieurs reprises. Les chercheurs de cette étude recommandent aux praticiens d'appliquer une équité "rigoureuse". analyses avant le déploiement comme une solution au biais. Ils suggèrent également que des clauses de non-responsabilité claires concernant le processus de collecte des ensembles de données et le biais algorithmique potentiel qui en résulte pourraient améliorer les évaluations à usage clinique.