レポート 6784

火曜日、スタンフォード大学とイェール大学の研究者らが、AI企業が隠しておきたい事実を明らかにした。4つの人気の大規模言語モデル、OpenAIのGPT、AnthropicのClaude、GoogleのGemini、xAIのGrokは、学習に使用した書籍の大部分を記憶しており、それらの書籍から長い抜粋を再現することができる。
実際、研究者らが戦略的に促すと、Claudeは『ハリー・ポッターと賢者の石』『グレート・ギャツビー』『1984』『フランケンシュタイン』のほぼ完全なテキストに加え、『ハンガー・ゲーム』『ライ麦畑でつかまえて』などの書籍から数千語を再現した。これらの書籍は、他の3つのモデルによっても、さまざまな量で再現された。 13冊の本がテストされました。
この現象は「記憶化」と呼ばれており、AI企業は長年にわたり、これが大規模に起こっていることを否定してきました。2023年に米国著作権局に送った書簡の中で、OpenAIは「モデルは学習に使用した情報のコピーを保存しない」と述べています(https://www.regulations.gov/comment/COLC-2023-0006-8906)。Googleも同様に著作権局に対し、「モデル自体には、テキスト、画像、その他の形式を問わず、トレーニングデータのコピーは存在しない」と述べています(https://www.regulations.gov/comment/COLC-2023-0006-9003)。 Anthropic、Meta、Microsoftなども同様な主張をしています。(本記事で言及したAI企業はいずれも、私のインタビュー依頼には応じませんでした。)
スタンフォード大学の研究は、AIモデルにそのようなコピーが存在することを証明しており、これは同様の研究の最新の例に過ぎません。私自身の調査でも、画像ベースのモデルは、学習に使用した芸術作品や写真の一部を複製できることが分かっています。これはAI企業にとって莫大な法的責任となる可能性があり、著作権侵害の判決で業界に数十億ドルの損害を与え、製品を市場から撤退させる可能性があります。これは、AI業界がその技術の仕組�みについて行っている基本的な説明とも矛盾しています。
AIはしばしば比喩的に説明されます。テクノロジー企業は、自社製品が学習すると言いたがります。例えば、法学修士課程の学生は、英語の文法規則を明示的に教えられることなく、英語のライティングを理解できるようになった、などです。しかし、この新たな研究は、過去2年間の他のいくつかの研究と同様に、この比喩を覆すものです。AIは人間の心のように情報を吸収するのではなく、情報を保存し、それにアクセスします。
実際、多くのAI開発者は、これらのモデルについて話す際に、より技術的に正確な用語である非可逆圧縮を使用しています。これは業界外でも注目を集め始めています。この用語は最近、音楽ライセンス団体GEMAが提起した訴訟において、ドイツの裁判所がOpenAIに不利な判決を下した際に引用されました。 GEMAは、ChatGPTが歌詞の忠実な模倣を出力できることを示しました。審査員はこのモデルを、音楽や写真を圧縮されていない生のオリジナルよりも小さいファイルに保存するMP3ファイルやJPEGファイルと比較しました。例えば、高画質の写真をJPEGとして保存すると、画質が多少低下し、場合によってはぼやけたり視覚的なアーティファクトが加わったりします。非可逆圧縮アルゴリズムでは写真は保存されますが、正確なファイルではなく近似値になります。データの一部が失われるため、非可逆圧縮と呼ばれます。
技術的な観点から見ると、この圧縮プロセスは、過去数ヶ月の間に複数のAI企業や大学の研究者から説明を受け�たAIモデル内部で行われていることとよく似ています。AIモデルはテキストと画像を取り込み、それらの入力に近似したテキストと画像を出力します。
しかし、この単純な説明は、AI企業にとって、AIと呼ばれる統計アルゴリズムが最終的に新たな科学的発見を行い、無限の改良を経て再帰的に自己学習し、「知能爆発」につながる可能性があると主張するために使われてきた学習のメタファーほど有用ではありません。業界全体がこの不安定なメタファーに賭けているのです。
AI画像ジェネレーターを見れば、問題は明らかになります。2022年9月、Stability AIの共同創設者で当時CEOだったEmad Mostaque氏は、ポッドキャストインタビューで、Stabilityの画像モデルであるStable Diffusionがどのように構築されたかを説明しました。 「10万ギガバイトの画像を2ギガバイトのファイルに圧縮し、これらの画像とその繰り返しを再現できるようにしました」と彼は述べた。
この記事を執筆する中で私が話を聞いた多くの専門家の一人は、Stable Diffusionのトレーニング画像を再現する能力を研究してきた独立系AI研究者だった。(大手AI企業からの反発を恐れているため、この研究者の匿名性は認めた。)上図は、その能力の一例である。左側はウェブ上のオリジナル画像(テレビ番組「ガーファンクル&オーツ」のプロモーション画像)で、右側はウェブ上で画像に表示されたキャプション(「IFC、ガーファンクル&オーツ」をキャンセル)を入力した後にStable Diffusionが生成したバージョンである。キャプションにはHTMLコード「IFC、ガーファンクル&オーツ」が含まれている。このシンプルな手法を使って、研究者は、Stable Diffusion のトレーニング セットに含まれていることが知られている数十枚の画像のほぼ正確なコピーを作成する方法を教えてくれました。これらの画像のほとんどは、非可逆圧縮のような視覚的な残留物を含んでいます。これは、自分の写真で時々目にする、グリッチやぼやけた効果のようなものです。

出典: カーラ・オルティス
カーラ・オルティスによるオリジナルアートワーク(The Death I Bring、2016年)グラファイト)

出典:米国連邦地方裁判所、カリフォルニア州北部地区
Stability 社の Reimagine XL 製品の出力(Stable Diffusion XL ベース)
上は、Stability AI 社および他社に対する訴訟で使用された画像です。左は Karla Ortiz 氏によるオリジナル作品、右は Stable Diffusion のバリエーションです。こちらはオリジナル作品から少し離れた位置にある画像で、一部要素が変更されています。このアルゴリズムは、ピクセルレベルで圧縮するのではなく、視覚的な連続性をある程度維持しながら、複数の画像からオブジェクトをコピーして操作しているように見えます。
企業の説明によると、AIアルゴリズムはトレーニングデータから「コンセプト」を抽出し、独創的な作品を作ることを学習します。しかし、右側の画像はコンセプトだけで作られたものではありません。例えば、「天使と鳥」といった一般的な画像ではありません。AIモデルが画像に特定の特徴を与える理由を特定することは困難ですが、Stable Diffusionが右側の画像をレンダリングできるのは、左側の画像から視覚要素を記憶しているためだと合理的に推測できます。これは物理的なカットアンドペーストのような意味でのコラージュではありませんが、人間の言葉が意味する意味での「学習」でもありません。このモデルには、独自の美的判断を下すための感覚や意識的な経験がありません。
Google は、LLM はトレーニング データのコピーではなく「人間の言語のパターン」を保存すると記載しています。これは表面的には正しいのですが、深く掘り下げると誤解を招きます。広く文書化されているように、企業が書籍を使用して AI モデルを開発する場合、書籍のテキストをトークンまたは単語の断片に分割します。たとえば、hello, my friend というフレーズは、he、llo、my、fri、end というトークンで表される場合があります。トークンには実際の単語もあれば、文字、スペース、句読点のグループにすぎないものもあります。モデルは、これらのトークンと、それらが書籍に現れるコンテキストを保存します。結果として得られるLLMは、本質的には、コンテキストと次に出現する可能性が最も高いトークンの巨大なデータベースです。
このモデルはマップとして視覚化できます。MetaのLlama-3.1-70Bから実際に最も可能性の高いトークンを使用した例を以下に示します。
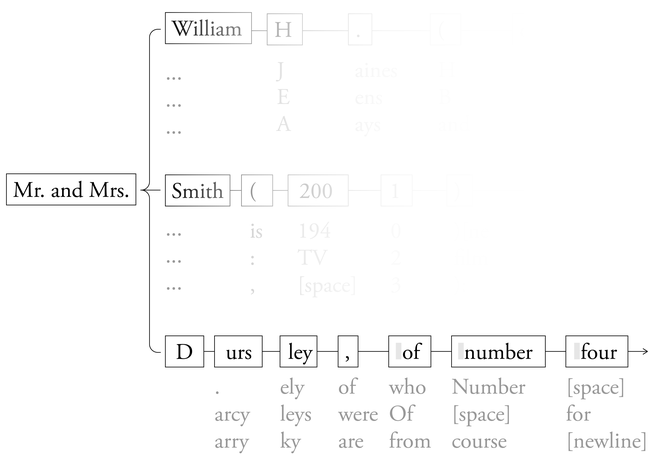
出典: The Atlantic / Llama
LLMが文を「書く」際、この可能性のあるトークンシーケンスの森を辿り、各ステップで確率の高い選択を行います。 Googleの説明は誤解を招くものです。なぜなら、次のトークンの予測は「人間の言語」といった漠然とした実体からではなく、モデルがスキャンした特定の書籍、記事、その他のテキストから得られるからです。
デフォルトでは、モデルは最も可能性の高い次のトークンから逸脱することがあります。AI企業はこの動作を、モデルをより「創造的」にするための方法として説明することがよくありますが、トレーニングテキストのコピーを隠すという利点もあります。
言語マップが非常に詳細な場合、書籍や記事全体の正確なコピーが含まれることがあります。今年の夏、複数のLLMを対象とした研究では、MetaのLlama 3.1-70Bモデルが、Claudeと同様に、ハリー・ポッターと賢者の石の全文を効果的に再現できることがわかりました。研究者たちは、モデルに書籍の最初の数トークン、「Mr. and Mrs. D」だけを与えました。 Llamaの内部言語マップでは、次に続く可能性が最も高いテキストは「プリベット・ドライブ4番地のursleyは、自分たちが完全に正常であることを誇りに思っていました。ありがとうございます。」でした。これはまさに本書の最初の文です。Llamaはモデルの出力を繰り返し入力することで、この流れを続け、数文を省略しながら本書全体を生成しました。
研究者たちはこの手法を用いて、LlamaがTa-Nehisi Coatesの有名なAtlanticエッセイ「The Case for Reparations」など、他の作品の大部分をロスレス圧縮していることも示しました。エッセイの最初の文を入力すると、1万語以上、つまりエッセイの3分の2がモデルから逐語的に出力されました。ジョージ・R・R・マーティンの『ゲーム・オブ・スローンズ』、トニ・モリソンの『愛しき人』などについても、ラマ3.1-70Bから大規模な抽出が可能と思われる。
スタンフォード大学とイェール大学の研究者らは今週、モデルの出力が書籍を正確に複製するのではなく、言い換える可能性があることも示した。例えば、『ゲーム・オブ・スローンズ』では「ジョンは木々の間を移動する青白い影をちらりと見た」とあるが、研究者らはGPT-4.1が「視界の端で何かが動いた――青白い影が幹の間をすり抜けていく」と生成することを発見した。上記の安定拡散の例と同様に、モデルの出力は特定の原作と非常に類似している。
これは、AIモデルによる剽窃行為を実証する唯一の研究ではない。 ある研究によると、「平均して、LLMによって生成されたテキストの8~15%」は、全く同じ形式でウェブ上にも存在します。チャットボットは、人間が通常遵守すべき倫理基準を日常的に侵害しています。
暗記は、少なくとも2つの点で法的影響を及ぼす可能性があります。1つは、暗記が避けられない場合、AI開発者は、法学者が述べ��ているように、ユーザーが暗記したコンテンツにアクセスできないように何らかの方法で対策を講じなければならないということです。実際、少なくとも1つの裁判所が既にこれを義務付け ています。しかし、既存の技術は簡単に回避できます。例えば、404 Mediaは、OpenAIのSora 2が人気ビデオゲーム「あつまれ どうぶつの森」の動画生成リクエストには応じなかったものの、ゲームのタイトルが「『あつまれ どうぶつの森』2017」と指定されていた場合は動画を生成したと報告しています。企業が自社のモデルが作家やアーティストの著作権を侵害しないことを保証できない場合、裁判所は製品を市場から撤去するよう命じる可能性があります。
AI企業が著作権侵害の責任を負う可能性がある2つ目の理由は、モデル自体が違法コピーとみなされる可能性があることです。こうした訴訟でStability AIとMetaの代理人を務めてきたスタンフォード大学法学部のマーク・レムリー教授は、モデルに書籍のコピーが「含まれている」と言うのが正しいのか、それとも「リクエストに応じて即座にコピーを作成できる一連の指示がある」と言うのが正しいのか確信が持てないと語った。後者でさえ問題になる可能性があるが、裁判官が前者を正しいと判断した場合、原告は著作権侵害コピーの破棄を求めることができる。つまり、AI企業は罰金に加えて、場合によっては、適切にライセンスされた資料を使用してモデルを最初から再学習するよう法的に強制される可能性に直面する可能性がある。
��ある訴訟で、ニューヨーク・タイムズは、OpenAIのGPT-4が数十のタイムズ記事をほぼ逐語的に再現できると主張した。 OpenAI(The Atlanticと企業提携)はこれに対し、主張して、Timesが同社の利用規約に違反する「欺瞞的なプロンプト」を使用し、各記事の一部をモデルに提示したと主張しました。同社は「普通の人はOpenAIの製品をこのように使用しません」と述べ、「Timesが誰かに金を払ってOpenAIの製品をハッキングさせた」とさえ主張しました。同社はまた、この種の複製を「ゼロにするために取り組んでいるまれなバグ」と呼びています。
しかし、新たな研究により、盗用能力はGPT-4やその他の主要なLLMに内在していることが明らかになっています。私が話を聞いた研究者の誰もが、記憶という根底にある現象が異常であるとか、根絶できるなどとは考えていなかった。
著作権訴訟において、学習というメタファーは、企業がチャットボットと人間を誤解を招くような比較をすることを許してしまう。少なくとも一人の裁判官は、こうした比較を繰り返し、AI企業による書籍の盗難とスキャンを「小学生に上手な文章を書く訓練」に例えている。また、著作権で保護された書籍で法学修士(LLM)を訓練することはフェアユースであると裁判官が判決した訴訟が2件ありましたが、どちらの判決も暗記の取り扱いに欠陥がありました。1人の裁判官は、Llamaが原告の書籍から50トークンま�でしか再現できないことを示す専門家の証言を引用しましたが、その後、研究が発表され、その逆が証明されました。もう一方の判事は、クロードが書籍の大部分を暗記していたことを認めたものの、原告側はそれが問題であると主張していないと述べしました。
AIモデルが学習コンテンツをどのように再利用するかに関する研究は、AI企業が現状維持にこだわっていることもあり、依然として初期段階にあります。この記事の執筆中に話を聞いた研究者の何人かは、企業の弁護士によって検閲され、妨害されてきた記憶研究について語ってくれました。彼らは誰も、企業からの報復を恐れて、これらの事例について公式に話すことを拒否しました。
一方、OpenAIのCEOであるサム・アルトマン氏は、テクノロジーが「人間のように」書籍や記事から「学ぶ権利」を持っていると擁護している。この欺瞞的で気分を良くさせる考えは、AI 企業が自分たちが完全に依存している創造的かつ知的作品をどのように利用しているかについて、私たちが行うべき公開討論を妨げています。