
今週、LLMの共有可能リンクをめぐる騒ぎが盛り上がっていたので、さらに詳しく調べてみようと思いました。金曜日にGoogleはChatGPTの共有可能リンクのインデックス登録を停止し、他のいくつかのプロバイダも全くインデックスに登録されませんでした。しかし、archive.orgが独自の記録を保持していることを知った後、他のプロバイダもそこに保存されているかどうか気になりました。
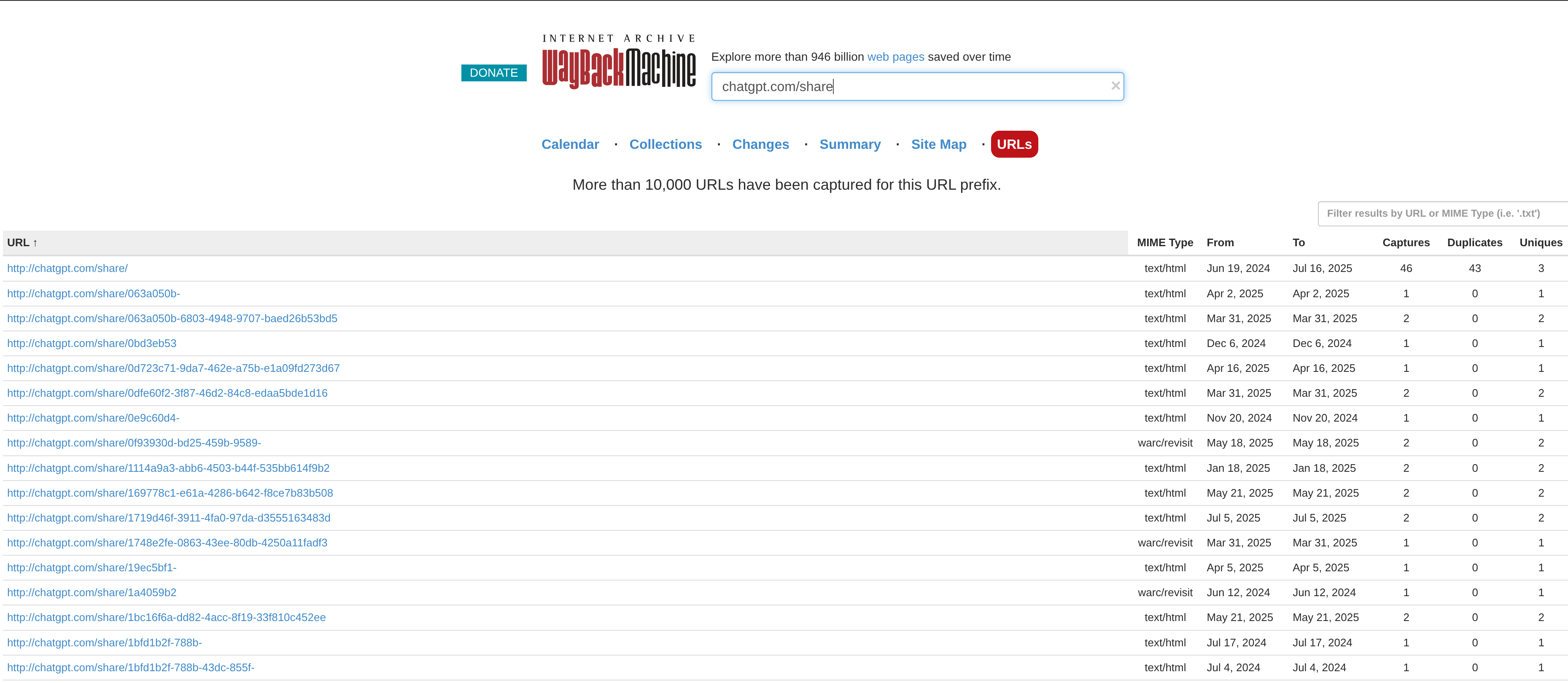
上のスクリーンショットでわかるように、実際に保存されていました。Archive.orgを使えば、以下の共有可能リンクを取得できます。
-
Grok
-
ChatGPT
-
Mistral
-
Qwen
-
Claude
-
Copilot
他にも共有可能リンクは確かにありますが、この記事ではこれらのプロバイダに絞って解説します。
Burp Suite の archvie.org ページにアクセスしたところ、インデックスされたすべての URL が以下の API 呼び出しから取得可能であることがわかりました。
https://web.archive.org/web/timemap/json?url=chatgpt.com%2Fshare&matchType=prefix&collapse=urlkey&output=json&fl=original%2Cmimetype%2Ctimestamp%2Cendtimestamp%2Cgroupcount%2Cuniqcount&filter=!statuscode%3A%5B45%5D..&limit=1000000&_=1754224717183
これを使用することで、エンドポイントでシンプルな wget を実行してコンテンツをローカルホストに保存し、各プロバイダーの URL パターンを grep で検索して、結果を各 LLM 固有のファイルに出力できました。
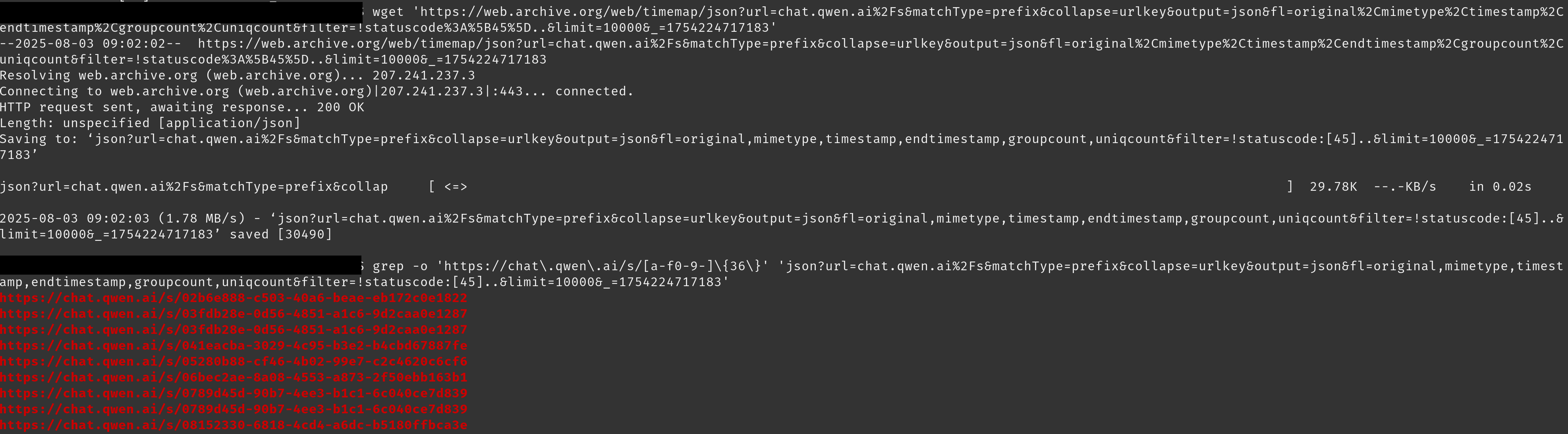
合計で143,142件の共有リンクを収集し、そのコンテンツを取得できました。それぞれの内訳は次のとおりです。
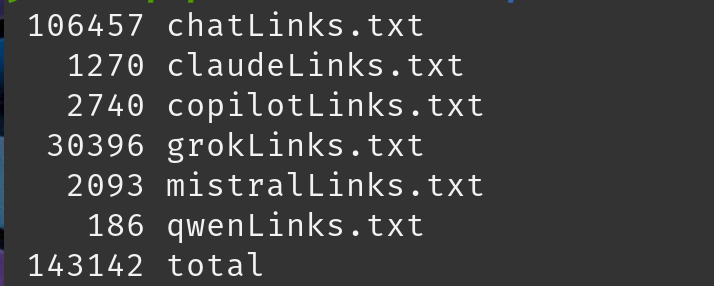
共有リンクからチャット履歴を取得する方法は、プロバイダーごとに異なることがわかりました。共有リンクへの単純なGETクエリを使用するものもあれば、別のエンドポイントへのAPI呼び出しを行うものもありました。どのように取得されているかを確認するために、いくつかのURLを再度参照し、Burp Suiteの履歴からチャットコンテンツを見つけ、必要に応じてURLを更新しました。

上記は、Alibaba の Qwen LLM が使用するエンドポイントです。
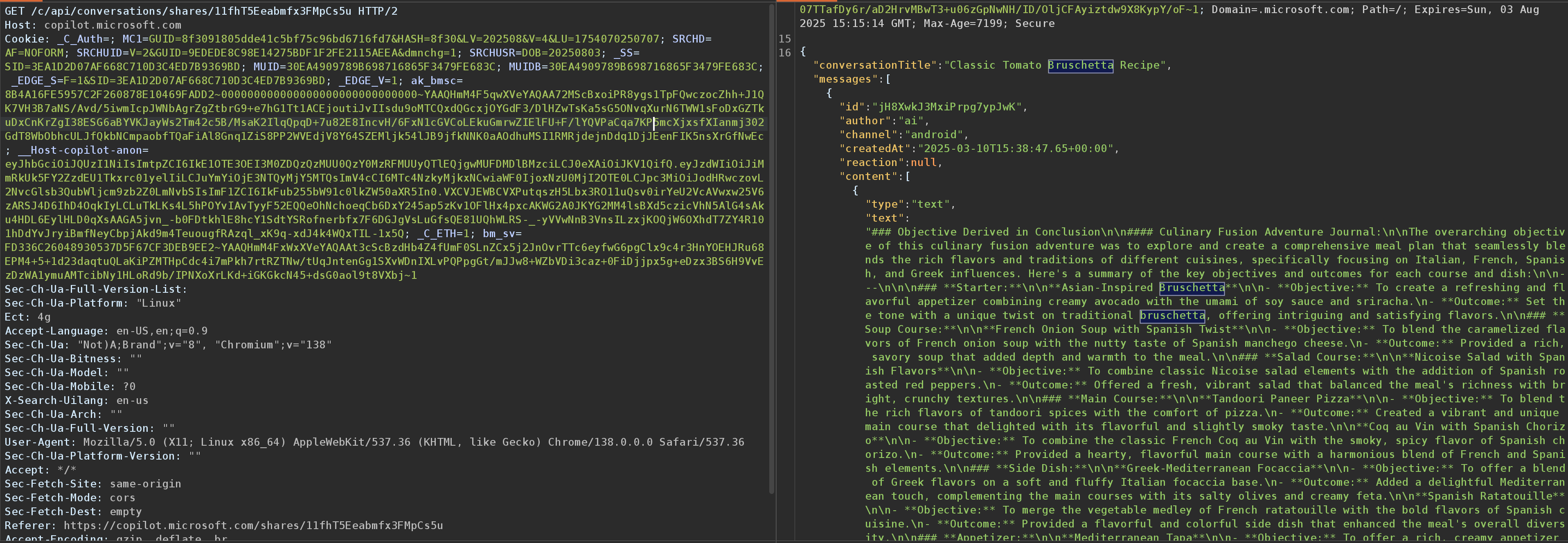
上記は、Copilot が使用するエンドポイントです。
チャットに使用される特定のエンドポイントを入手したので、リクエストする URL を含むファイルに対して、簡単な一致と置換を実行しました。

次に、これらのエンドポイントそれぞれに対して curl を実行し、出力をディレクトリ内のファイルに書き込むという作業を行いました。これは非常に簡単な作業です。
一部のプロバイダーでは、データを表示する前に Cloudflare の認証を通過する必要がありました。これを回避するため、Cloudscraper を使った簡単な Python スクリプトを作成しました。Cloudscraper は、この問題を回避するのに非常に便利です。
cloudscraper をインポート
INPUT_FILE = ''
OUTPUT_FILE = ''
scraper = cloudscraper.create_scraper()
scraper.headers.update({
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
})
last_successful_url = None
infile として open(INPUT_FILE, 'r')、outfile として open(OUTPUT_FILE, 'w') を実行:
infile 内の行:
url = line.strip()
url でない場合:
continue
print(f"➡️ リクエスト中: {url}")
try:
response = scraper.get(url)
response.status_code が == の場合403:
print(f"\n❌ 403 Forbidden - 停止中.\n前回成功したURL: {last_successful_url}")
break
outfile.write(f"===== {url} =====\n")
outfile.write(response.text + "\n\n")
last_successful_url = url
except Exception as e:
print(f"⚠️ Error fetching {url}: {e}")
continue
残念ながら、このデータセットではTrufflehogのようなツールはあまりうまく機能しませんでした。代わりに、grepを実行して結果を手動で確認し、攻撃者が利用できるものがないか確認する必要がありました。いくつかの正規表現を使用することで、AWSアクセスキーID、Replicate APIトークンなどを見つけることができました。まだ解析すべきデータは山ほどあり、今後数日間でさらに多くのデータが発見される可能性が高く、今後のアップデートで言及する価値があるかもしれません。今のところは、簡単にまとめておきます。ちらりと見る:
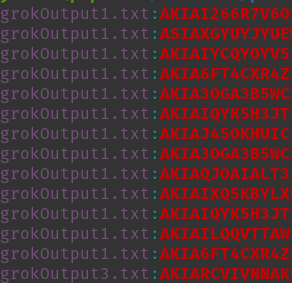


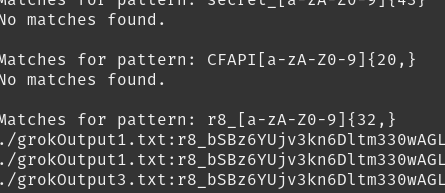
これらのプロバイダーは共有リンクが誰にでも公開されることをユーザーに伝えていますが、この機能を利用した人のほとんどは、これらのリンクが誰でも見つけられるとは思っていなかったでしょう。ましてやインデックス化されて他の人が簡単に閲覧できる状態ではないことは言うまでもありません。これは、攻撃者やレッドチームにとって非常に貴重なデータソースとなる可能性があります。この機能を使えば、いつでもデータセットを検索して、対象企業の従業員が誤って機密情報を漏洩していないかを確認できます。
Claude のチャットの出力を確認したときに気づいた興味深い点は、各チャットで作成者とフルネームが特定されていたことです。

[~] この件についてご協力いただいた SyndromeImposter と MasterSplinter に心より感謝いたします。