
3 日前、SourceHut の創設者兼 CEO である Drew DeVault 氏は、「コストを私に直接押し付けるのはやめてください」というブログ記事を公開し、その中で、LLM 企業が robosts.txt を尊重せずにデータをクロールし、SourceHut に深刻な障害を引き起こしていると不満を述べました。

私は「面白い!」と言い、先に進みました。
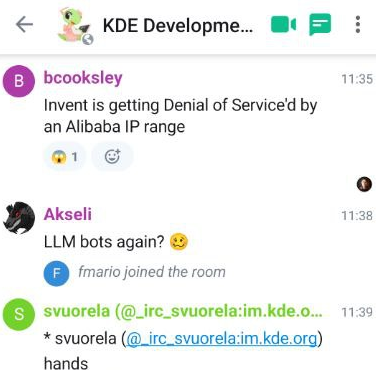
そして、昨日の朝、KDE GitLab インフラストラクチャが Alibaba の範囲の IP を持つ別の AI クローラーによって圧倒され、これにより KDE 開発者が GitLab に一時的にアクセスできなくなりました。
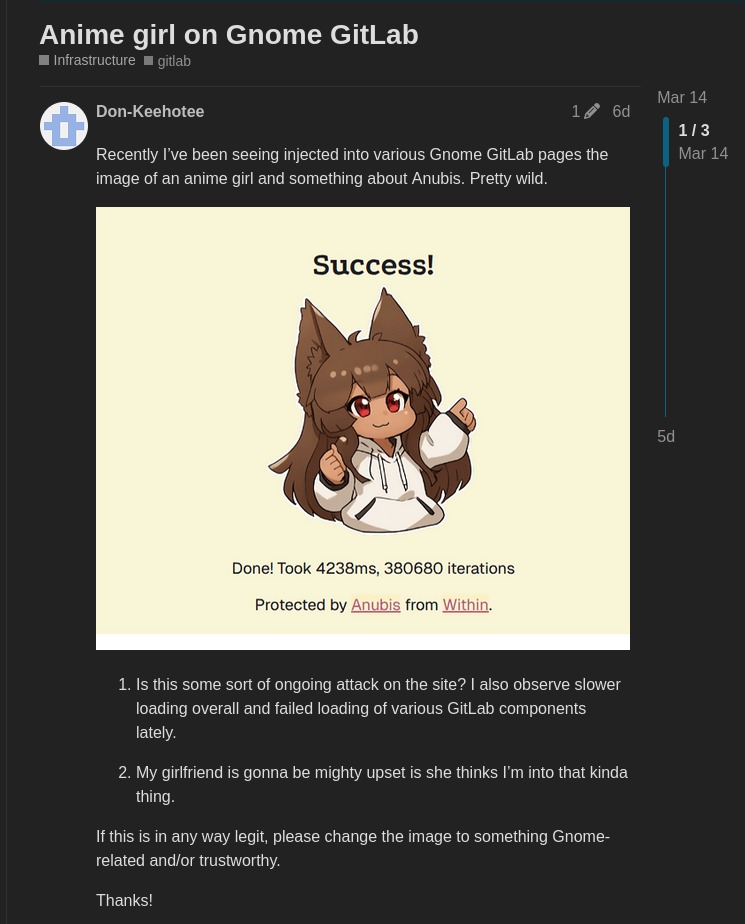
それから、1週間前、ページが読み込まれると、GNOME GitLabインスタンスにアニメの女の子が現れ始めたことを発見しました。これは、障害を引き起こしているAIスクレーパーをブロックするプルーフオブワークチャレンジャーであるAnubisのデフォルトの読み込みページであることが判明しました。
今では、これが偶然ではないことは明らかです。AI スクレイパーはますます攻撃的になっており、FOSS ソフトウェアはパブリック コラボレーションに依存していますが、民間企業にはその要件がないため、オープン ソース コミュニティに余分な負担がかかっています。
それでは、Drew のブログ投稿に戻って、詳細を調べてみましょう。Drew によると、LLM クローラーは robots.txt の要件を尊重せず、git の非難、すべての git ログのすべてのページ、リポジトリ内のすべてのコミットなどの高価なエンドポイントを含めます。彼らは、数万の IP アドレスからランダムなユーザー エージェントを使用してこれを実行し、各 IP アドレスは 1 つの HTTP リクエストのみを行い、ユーザー トラフィックに溶け込もうとします。

このため、適切な緩和策を講じることは困難です。Drew 氏によると、これらの中断により、いくつかの優先度の高いタスクが数週間または数か月遅れ、ユーザーが影響を受けることがあり (ボ�ットと人間を区別するのが難しいため)、もちろん、これにより SourceHut が時々停止します。

Drew 氏は、どの AI 企業が robots.txt ファイルを多かれ少なかれ尊重しているか、またはユーザー エージェント レポートがより正確であるかを区別していません。これについては後で詳しく調べることができます。
最後に、Drew 氏は、これは孤立した問題ではないと指摘しています。彼は次のように述べています。
私のシステム管理者の友人は皆同じ問題に取り組んでおり、システム管理者の友人とビールや夕食を共にして交流するたびに、すぐにボットについて不満を言うようになります。[...] これらの会話から必死さが伝わってきます。

昨日の KDE GitLab の問題に戻ります。KDE システム管理チームの一員である Ben によると、この DDoS を実行していたすべての IP は MS Edge であると主張しており、中国の AI 企業によるものでした。彼は、OpenAI や Anthropic などの西洋の LLM オペレーターは少なくとも適切な UA を設定していたと述べています。これについては後で詳しく説明します。
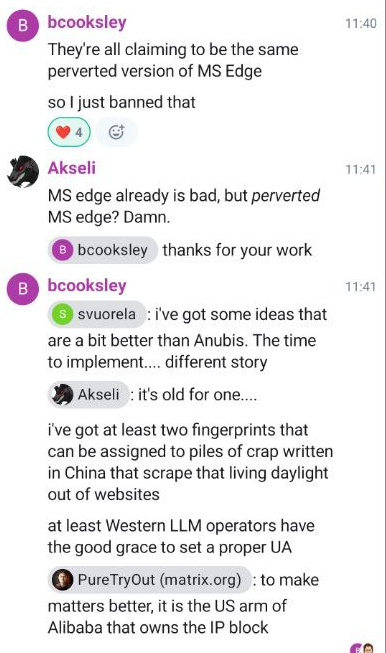
現時点での解決策は、ボットが主張するバージ�ョンの Edge を禁止することでしたが、これが決定的な解決策になるとは考えにくいです。これらのボットは、できるだけ溶け込むようにユーザー エージェントを変更することに熱心なようです。
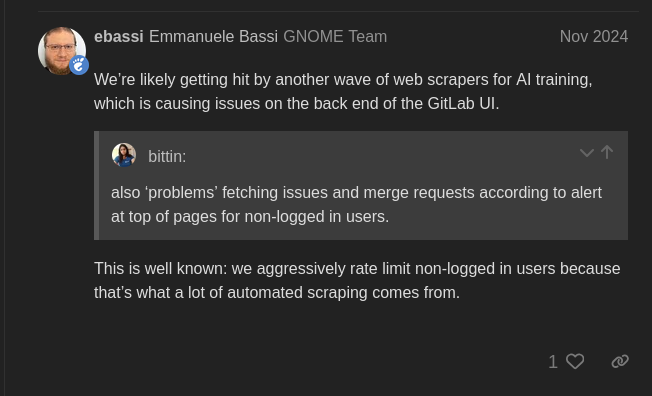
実際、GNOME は昨年 11 月から問題を抱えています。一時的な解決策として、ログインしていないユーザーがマージ リクエストやコミットを表示できないようにレート制限していましたが、これは当然のことながら、実際の人間のゲストにも問題を引き起こしました。
最終的に決着した解決策は、Anubis に切り替えることでした。これはブラウザに課題を提示するページであり、ブラウザは時間をかけて計算を行い、その解決策をサーバーに返す必要があります。正解であれば、Web サイトにアクセスできます。
開発者によると、このプロジェクトは「核兵器のような反応ですが、AI スクレイパー ボットがあまりにも積極的にスクレイピングしているため、やらざるを得ませんでした。これをしなければならないのは嫌ですが、ボットは robots.txt などの標準に準拠していないため、現代のインターネットではこうなるのです。たとえ準拠していると主張していてもです」。
しかし、これはユーザーにとっても問題を引き起こしています。多くの人が同じ場所からリンクを開くと、完了までに時間がかかる、より難易度の高いエクササイズが提供される場合があります。1 分の遅延を報告しているユーザーもいますが、携帯電話からは約 2 分待たなければならないというユーザーもいます。
なぜでしょう? チャットルームに GitLab のリンクが貼り付けられたのです! 同様に、トリプル バッファリング GNOME マージ リクエストが Hacker News に投稿されたときにも同じことが起こり、そこで大きな注目を集めました。開発者が言ったように、これはクローラーにとって核兵器のような選択肢ですが、人間にも影響を及ぼします。
Mastodon では、GNOME システム管理者の Bart Piotrowski 氏が、問題の範囲を完全に理解できるようにいくつかの数字を親切に共有してくれました。彼によると、約 2 時間半で合計 81,000 件のリクエストが受信され、そのうち Anubi の作業証明を通過したのはわずか 3% で、トラフィックの 97% がボットであることが示唆されています。これはとんでもない数字です!
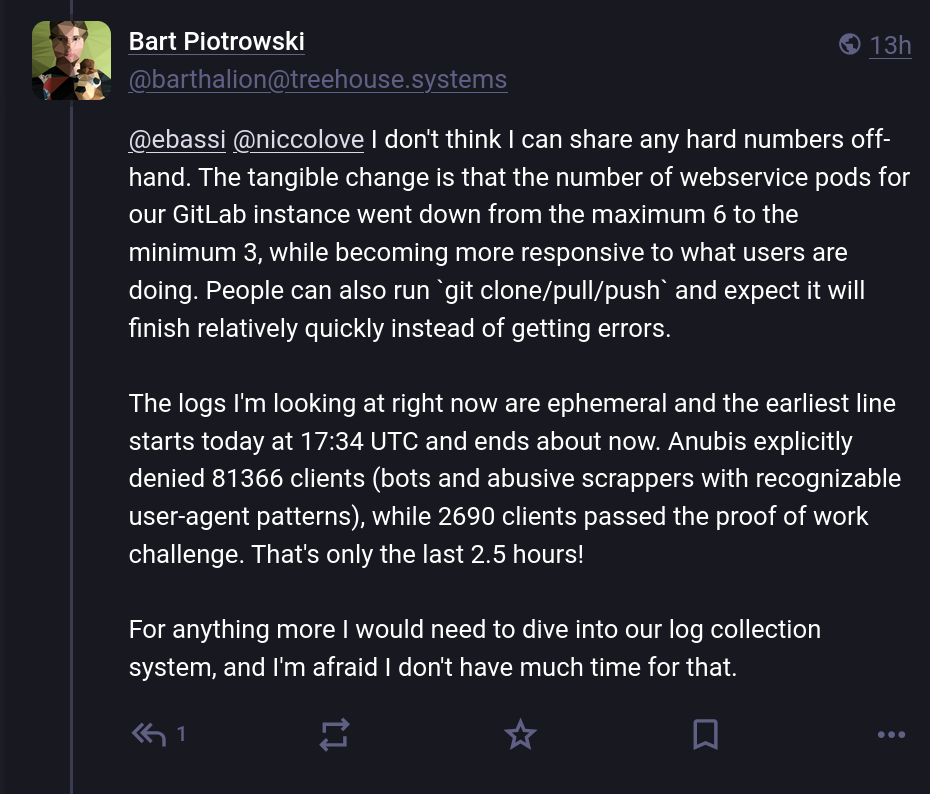
とはいえ、少なくともそれはうまくいきました。��他の組織は、これらのスクレーパーに対処するのに苦労しています。
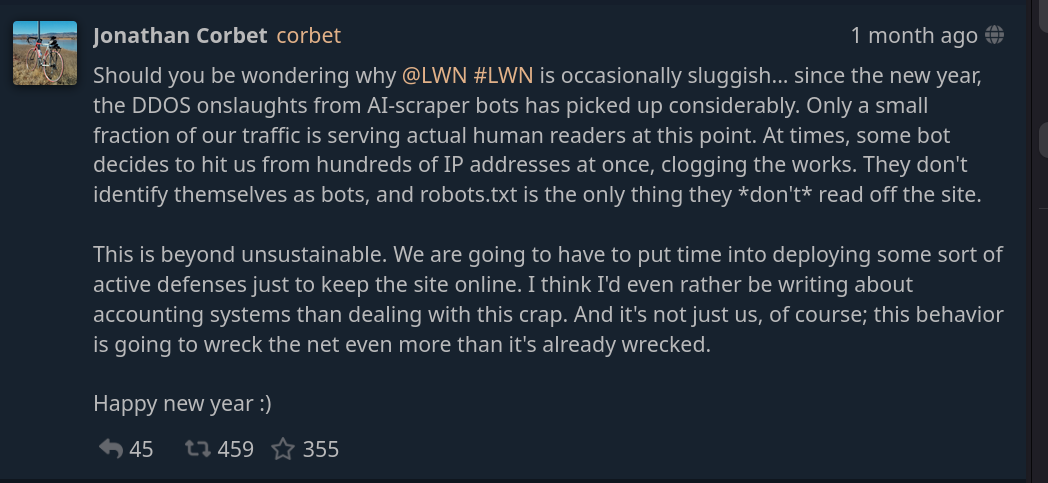
例として、FOSSニュースソースLWNを運営するJonathan Corbetは、AIスクレーパーボットからのDDoSにより、Webサイトが「時々遅くなる」可能性があるとユーザーに警告しています。彼は、「実際の人間の読者にサービスを提供しているのは、私たちのトラフィックのほんの一部に過ぎない」と主張し、ある時点で、ボットは「一度に数百の IP アドレスから私たちを攻撃することを決定します。[...] ボットは自分自身をボットとして識別せず、robots.txt だけがサイトから読み取らないものです」。
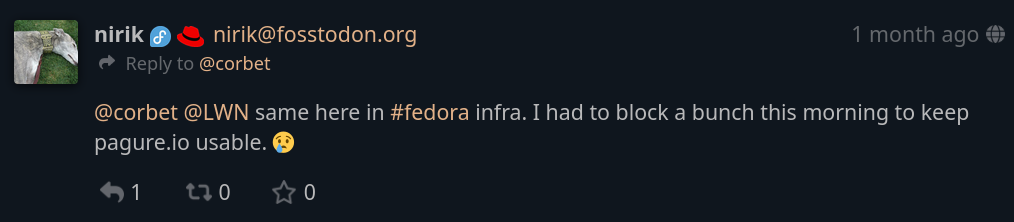
Fedora プロジェクトのシステム管理者である Kevin Fenzi 氏を含む多くの人が連帯を表明しました。 AI スクレイパーの問題も抱えています。まず、1 か月前、pagure.io を存続させるために戦わなければなりませんでした。
しかし、時間の経過とともに状況は悪化し、多数のサブネットをブロックしなければならなくなり、多くの実際のユーザーにも影響が出ています。絶望のあまり、ケビンはある時点でブラジル全土を禁止して、再び機能するようにすることを決定しました。私の理解では、この禁止措置は現在も有効であり、長期的な解決策がどこにあるのかは明らかではありません。

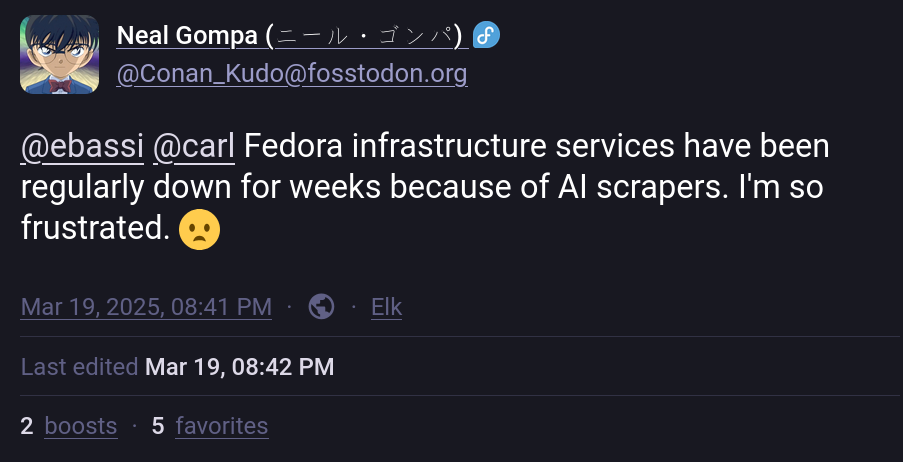
そして、Neal Gompa 氏が指摘しているように、国全体をブロックしても効果は限られており、どうやら Fedora のインフラストラクチャは AI スクレーパーのせいで「数週間にわたって定期的にダウン」しているようです。
先週この問題の影響を受けた別のプロジェクトはInkscapeです。Martin Owens氏によると、これは「昨年の通常の中国のDDoSではなく、当社のスパイダーconfを無視し、ブラウザ情報を偽装し始めた多数の企業によるものです。私は現在、Prodigiusのブロックリストを持っています。AIを扱う大企業で働いている場合は、当社のWebサイトにアクセスできなくなる可能性があります」とのことです。
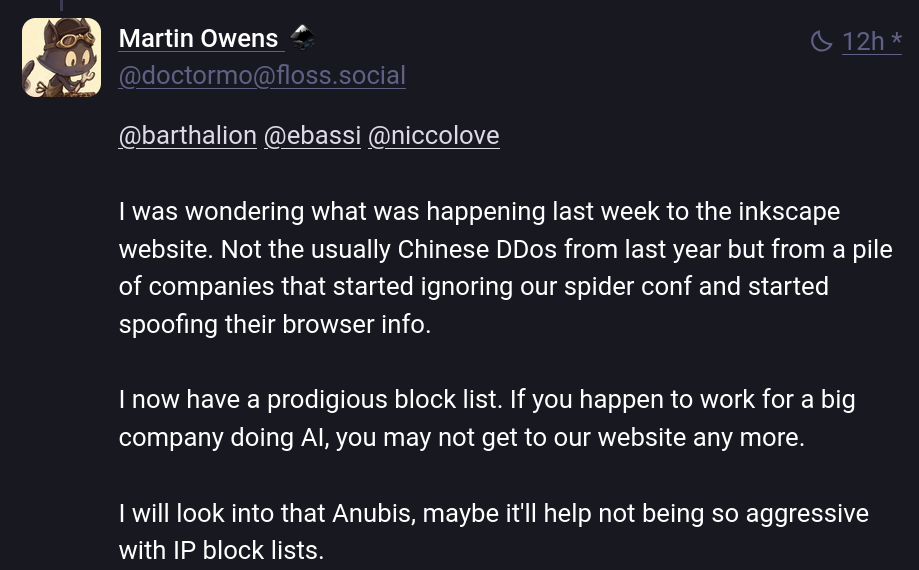
そして、Martin は「膨大なブロック リスト」を作成した唯一の開発者ではありません。Frama ソフトウェアの BigGrizzly でさえ、悪質な LLM クローラーに襲われ、偽装されたユーザー エージェントを含む 46 万件の IP を禁止するリストを作成しました。彼はそのリストを広く共有することを提案しています。
これに対するもう 1 つの包括的な試みは、「ai.robots.txt」プロジェクトです。これは、AI 企業に関連する Web クローラーのオープン リストです。このプロジェクトでは、ロボット排除プロトコルを実装する robots.txt と、リスト内の AI クローラーからリクエストを受け取ったときにエラー ページを返す .htaccess ファイルを提供しています。
数か月前まで遡れば、クローラーに関する数字がさらに得られます。こちらは、Dennis Schubert による Diaspora (オープンソースの分散型ソーシャル ネットワーク) インフラストラクチャに関する投稿です。彼は、「トラフィック ログを見ると、非常に腹が立った」と述べています。
ブログ投稿では、ウェブトラフィック全体の4分の1はOpenAIユーザーエージェントのボットによるもので、15%はAmazon、4.3%はAnthropicによるものだと主張しています。全体として、リクエスト全体の70%はAI企業からのものです。

彼によると、
彼らはページを一度クロールして、次に進むだけではありません。 ああ、いや、彼らは6時間ごとに戻ってきます。 なぜなら、なぜそうしないのか、笑。 また、彼らは
robots.txtについてまったく気にしていません。 なぜなら、彼らが気にする必要があるのは、なぜかです。 [...] レート制限を試みても、彼らは常に他のIPに切り替えるだけです。 ユーザーエージェント文字列でブロックしようとすると、彼らはボットではないUA文字列に切り替えるだけです(本当に)。 これは文字通り、インターネット全体に対するDDoSです。

Read the Docs プロジェクトでも同様の数字が示されています。「AI クローラーはもっと敬意を払う必要がある」というブログ投稿では、すべての AI クローラーをブロックするとトラフィックが即座に 75% 減少し、1 日あたり 800 GB から 200 GB になったと主張しています。これにより、プロジェクトは 1 か月あたり約 1,500 ドルを節約できました。

記事の残りの部分もかなり印象的です。数日、あるいはそれ以上の期間で数十テラバイトのデータをダウンロードするクローラーについて書かれています。さまざまな IP を使用しているため、完全にブロックするのは困難です。

このうちどれだけがトレーニング データのスクレイピングで、どれだけがほとんどの LLM が提供する「検索」機能なのかは疑問です。とはいえ、Schubert 氏によると、Google や Bing などの「通常の」クローラーはわずか 1 パーセント ポイントに過ぎ�ず、他の企業が Web の力を悪用しているという事実を示唆しています。
ただし、これはスクレイパーだけではありません。そうでなければ、このタイトルを「AI 企業」ではなく「AI スクレイパー」にしたでしょう。たとえば、オープン ソース コミュニティが取り組んでいるもう 1 つの問題は、AI によって生成されたバグ レポートです。
これは Curl プロジェクトの Daniel Stenberg 氏が「LLM の I は Intelligence の略」というブログ記事で初めて報告したものです。Curl はバグ報奨金プロジェクトを提供していますが、最近、多くのバグ レポートが AI によって生成されていることに気付きました。これらは信頼性が高く、確認に多くの開発者の時間を費やしますが、AI に期待される典型的な幻覚も含まれています。
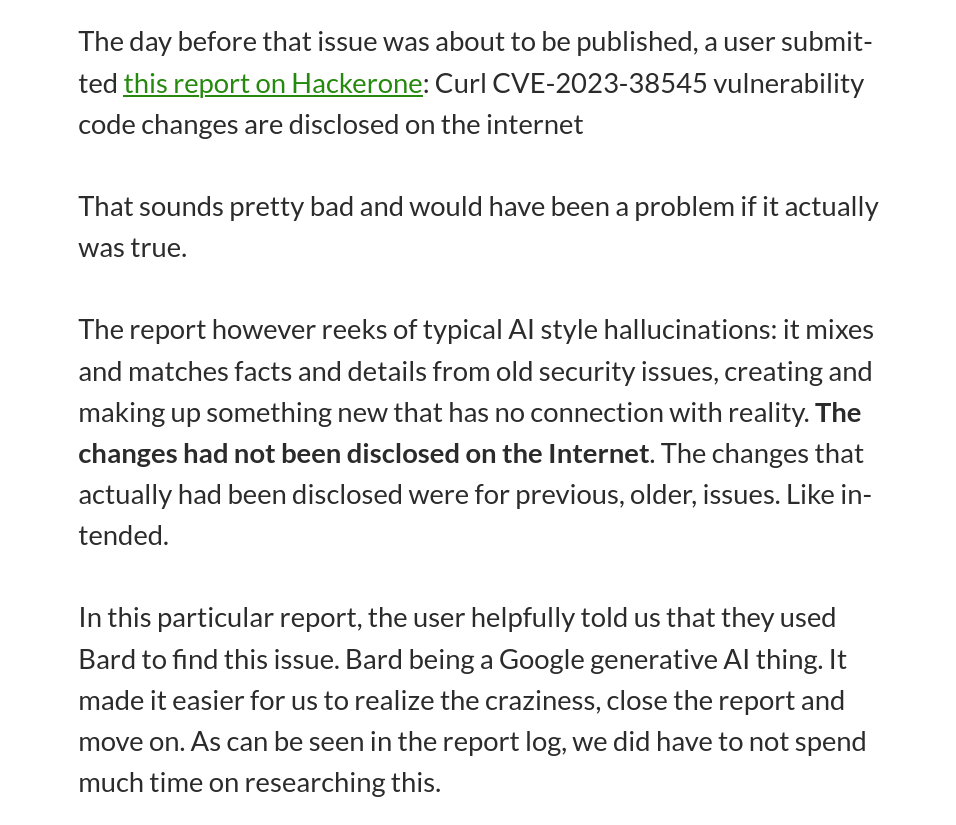
バグ レポートで、修正すべき重大なセキュリティ問題があると自信を持って伝えられ、自分のコードを調べなければならないのに、問題全体が AI の幻覚に過ぎず、その問題が見つからないというのは、かなりクレイジーなことです。

CPython、pip、urllib3、Requests などのセキュリティ レポート トリアージ チームに所属する Seth Larson 氏も同様の問題を報告しました。同氏は次のように述べています。
最近、オープンソース プロジェクトに対する極めて低品質でスパムのような、LLM �の幻覚的なセキュリティ レポートが増加していることに気づきました。問題は、LLM の時代では、これらのレポートは一見すると正当なものである可能性があり、反論に時間がかかることです。

これはかなり大きな問題です。彼が指摘しているように、セキュリティ レポートへの対応にはコストがかかり、捏造されたが信頼できるバグ レポートへの対応はメンテナーにかなりの負担をかけ、オープンソースの世界から追い出される可能性があります。

記事の最後は、脆弱性の検出に AI や LLM システムを使用しないでくださいという要請で締めくくられています。彼は、「現在のこれらのシステムはコードを理解できません。セキュリティの脆弱性を見つけるには、コードを理解することに加え、意図、一般的な使用法、コンテキストなどの人間レベルの概念を理解することが必要です」と述べています。

繰り返しになりますが、これらの問題は FOSS の世界に不釣り合いなほど大きな影響を与えていることを指摘したいと思います。オープンソース プロジェクトは商用製品に比べてリソースが少ないことが多いだけでなく、コミュニティ主導のプロ�ジェクトであるため、インフラストラクチャの多くが公開されており、クローラーと AI によって生成されたバグ レポートや問題の影響を受けやすいのです。