Introduction
Collaborative filtering (CF) is one of the most traditional but also most powerful concepts for calculating personalized recommendations [22] and is vastly used in the field of multimedia recommender systems (MMRS) [11]. However, one issue of CF-based approaches is that they are prone to popularity bias, which leads to the overrepresentation of popular items in the recommendation lists [2,3]. Recent research has studied popularity bias in domains such as music [15,16] or movies [3] by comparing the recommendation performance for different user groups that differ in their inclination to mainstream multimedia items. However, a comprehensive study of investigating popularity bias on the item and user level across several multimedia domains is still missing (see Section 2).
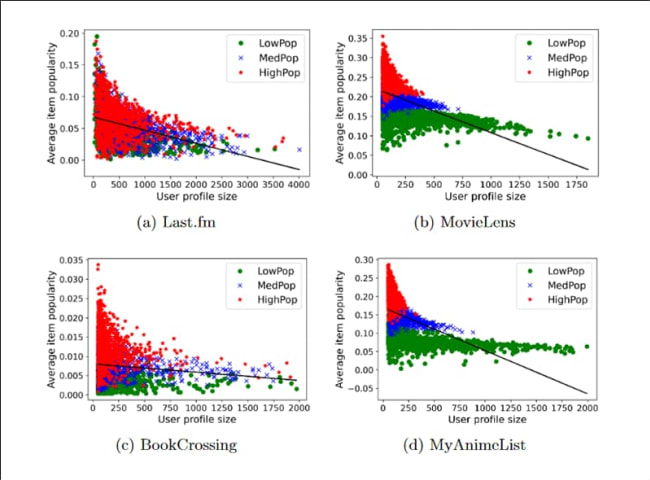
In the present paper, we therefore build upon these previous works and expand the study of popularity bias to four different domains of MMRS: music (Last.fm), movies (MovieLens), digital books (BookCrossing), and animes (MyAnimeList). Within these domains, we show that users with little interest into popular items tend to have large user profiles and thus, are important consumers and data sources for MMRS. Furthermore, we apply four different CF-based recommendation algorithms (see Section 3) on our four datasets that we each split into three user groups that differ in their inclination to popularity (i.e., LowPop, MedPop, and HighPop). With this, we address two research questions (RQ):
– RQ1: To what extent does an item’s popularity affect this item’s recommendation frequency in MMRS?
– RQ2: To what extent does a user’s inclination to popular items affect the quality of MMRS?
Regarding RQ1, we find that the probability of a multimedia item to be recommended strongly correlates with this items’ popularity. Regarding RQ2, we find that users with less inclination to popularity (LowPop) receive statistically significantly worse multimedia recommendations than users with medium (MedPop) and high (HighPop) inclination to popular items (see Section 4). Our results demonstrate that although users with little interest into popular items tend to have the largest user profiles, they receive the lowest recommendation accuracy. Hence, future research is needed to mitigate popularity bias in MMRS, both on the item and the user level.
Related Work
This section presents research on popularity bias that is related to our work. We split these research outcomes in two groups: (i) work related to recommender systems in general, and (ii) work that focuses on popularity bias mitigation techniques.
Popularity bias in recommender systems. Within the domain of recommender systems, there is an increasing number of works that study the effect of popularity bias. For example, as reported in [8], bias towards popular items can affect the consumption of items that are not popular. This in turn prevents them to become popular in the future at all. That way, a recommender system is prone to ignoring novel items or the items liked by niche users that are typically hidden in the “long-tail” of the available item catalog. Tackling these long-tail items has been recognized by some earlier work, such as [10,20]. This issue is further investigated by [1,2] using the popular movie dataset MovieLens 1M. The authors show that more than 80% of all ratings actually belong to popular items, and based on this, focus on improving the trade-off between the ranking accuracy and coverage of long-tail items. Research conducted in [13] illustrates a comprehensive algorithmic comparison with respect to popularity bias. The authors analyze multimedia datasets such as MovieLens, Netflix, Yahoo!Movies and BookCrossing, and find that recommendation methods only consider a small fraction of the available item spectrum. For instance, they find that KNN-based techniques focus mostly on high-rated items and factorization models lean towards recommending popular items. In our work, we analyze an even larger set of multimedia domains and study popularity bias not only on the item but also on the user level.
Popularity bias mitigation techniques. Typical research on mitigating popularity bias performs a re-ranking step on a larger set of recommended candidate items. The goal of such post-processing approaches is to better expose longtail items in the recommendation list [2,4,6]. Here, for example, [7] proposes to improve the total number of distinct recommended items by defining a target distribution of item exposure and minimizing the discrepancy between exposure and recommendation frequency of each item. In order to find a fair ratio between popular and less popular items, [24] proposes to create a protected group of long-tail items and to ensure that their exposure remains statistically indistinguishable from a given minimum. Beside focusing on post-processing, there are some in-processing attempts in adapting existing recommendation algorithms in a way that the generated recommendations are less biased toward popular items. For example, [5] proposes to use a probabilistic neighborhood selection for KNN methods, or [23] suggests a blind-spot-aware matrix factorization approach that debiases interactions between the recommender system and the user. We believe that the findings of our paper can inform future research on choosing the right mitigation technique for a given setting.
...