Incidentes Asociados

*Este artículo se publica con el apoyo de The Capitol Forum. * La organización que lo creó eliminó el conjunto de datos de aprendizaje automático LAION-5B utilizado por Stable Diffusion y otros productos importantes de IA después de que un estudio de Stanford descubriera que contenía 3226 casos sospechosos de material de abuso sexual infantil, 1008 de los cuales fueron validados externamente. LAION dijo a 404 Media el martes que por "mucha precaución", estaba eliminando sus conjuntos de datos, incluidos LAION-5B y otro llamado LAION-400M temporalmente "para garantizar que estén seguros antes de volver a publicarlos". Según un nuevo estudio realizado por el Observatorio de Internet de Stanford compartido con 404 Media antes de su publicación, los investigadores encontraron los casos sospechosos de CSAM a través de una combinación de detección y análisis perceptivo y criptográfico basado en hash de las propias imágenes. "Encontramos que tener posesión de un conjunto de datos LAION-5B poblado incluso a finales de 2023 implica la posesión de miles de imágenes ilegales, sin incluir todas las imágenes íntimas publicadas y recopiladas de forma no consensual, cuya legalidad es más variable según jurisdicción", dice el periódico. "Si bien la cantidad de CSAM presente no necesariamente indica que la presencia de CSAM influya drásticamente en el resultado del modelo más allá de la capacidad del modelo para combinar los conceptos de actividad sexual y niños, es probable que aún ejerza influencia. La presencia de CSAM repetido casos idénticos de CSAM también es problemático, particularmente debido a que refuerza las imágenes de víctimas específicas". El hallazgo destaca el peligro de un rastreo en gran medida indiscriminado de Internet con fines de inteligencia artificial generativa. La Red Abierta de Inteligencia Artificial a gran escala, o LAION, es una organización sin fines de lucro que crea herramientas de código abierto para el aprendizaje automático. LAION-5B es uno de sus productos más grandes y populares. Se compone de más de cinco mil millones de enlaces a imágenes extraídas de la web abierta, incluidas plataformas de redes sociales generadas por usuarios, y se utiliza para entrenar los modelos de generación de IA más populares actualmente en el mercado. Stable Diffusion, por ejemplo, utiliza LAION-5B y Stability AI financió su desarrollo. "Si ha descargado ese conjunto de datos completo para cualquier propósito, para entrenar un modelo con fines de investigación, entonces sí, definitivamente tiene CSAM, a menos que haya tomado algunas medidas extraordinarias para detenerlo", David Thiel, autor principal del estudio y tecnólogo jefe. en el Observatorio de Internet de Stanford dijo a 404 Media. Los chats públicos de los líderes de LAION en el servidor oficial de Discord de la organización muestran que estaban conscientes de la posibilidad de que CSAM fuera incluido en sus conjuntos de datos ya en 2021. "Supongo que distribuir un enlace a una imagen como pornografía infantil puede considerarse ilegal. ", escribió el ingeniero principal de LAION, Richard Vencu, en respuesta a un investigador que preguntó cómo maneja LAION los posibles datos ilegales que podrían incluirse en el conjunto de datos. "Intentamos eliminar esas cosas, pero no hay garantía de que desaparezcan todas". [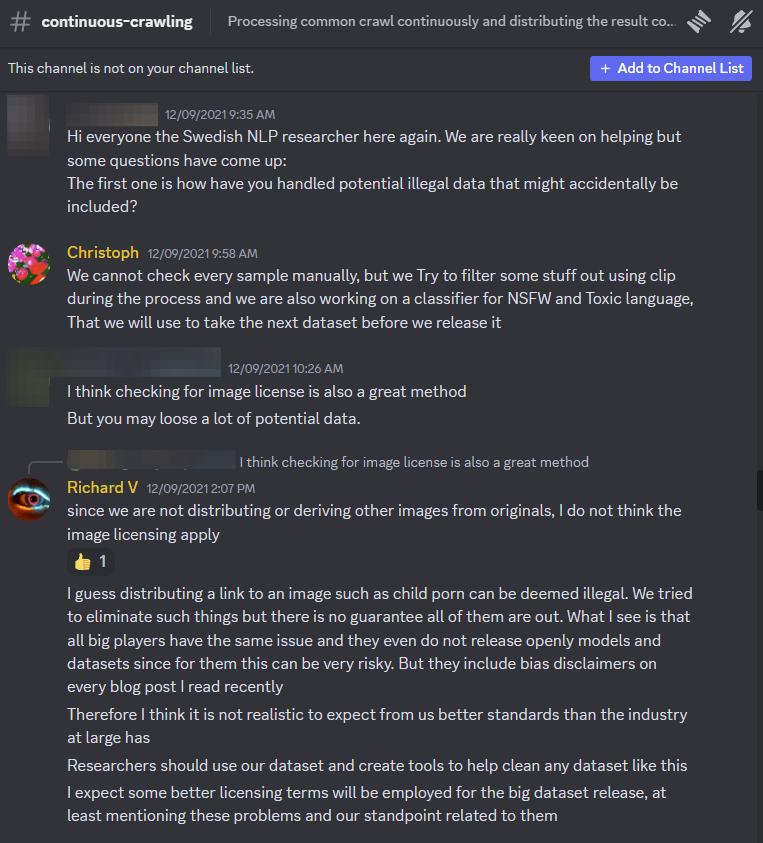 ](https://www.404media.co/content/images/2023/12/laion_discord_1 -1.png) CAPTURA DE PANTALLA A TRAVÉS DE LAION DISCORD La mayoría de las instituciones en los EE. UU., incluido el equipo de Thiel, no están legalmente autorizadas a ver CSAM para verificarlo ellas mismas. Para realizar investigaciones sobre CSAM, los expertos suelen recurrir al hashing perceptual, que extrae una firma digital única o huella digital. , a partir de una imagen o vídeo. PhotoDNA es una tecnología que crea hashes únicos para imágenes de explotación infantil con el fin de encontrar esas imágenes en otros lugares de la web y eliminarlas o perseguir a los abusadores o proliferadores. "Con el objetivo de cuantificar el grado en el que CSAM está presente en el conjunto de datos de entrenamiento, así como eliminarlo tanto de LAION-5B como de los conjuntos de datos derivados, utilizamos varias técnicas complementarias para identificar CSAM potencial en el conjunto de datos: detección perceptiva basada en hash, detección criptográfica basada en hash y análisis de vecinos más cercanos aprovechando las incrustaciones de imágenes en el propio conjunto de datos", dice el documento. A través de este proceso, identificaron al menos 2000 entradas en conjuntos de datos de sospecha de CSAM y confirmaron esas entradas con terceros. Para realizar su investigación, Thiel dijo que se centró en las URL identificadas por el clasificador de seguridad de LAION como "no seguras para el trabajo" y envió esas URL a PhotoDNA. Las coincidencias de hash indican CSAM definido y conocido, y se enviaron a la API del Proyecto Arachnid Shield y fueron validadas por el Centro Canadiense para la Protección Infantil, que puede ver, verificar e informar esas imágenes a las autoridades. Una vez que se verificaron esas imágenes, también pudieron encontrar coincidencias de "vecinos más cercanos" dentro del conjunto de datos, donde se agruparon imágenes relacionadas de las víctimas. LAION podría haber utilizado un método similar a este antes de publicar el conjunto de datos de entrenamiento de IA más grande del mundo, dijo Thiel, pero no lo hizo. "[LAION] inicialmente usó CLIP para tratar de filtrar algunas cosas, pero no parece que lo hicieran originalmente consultando con ningún experto en seguridad infantil. Fue bueno que lo intentaran. Pero los mecanismos que usaron simplemente no fueron excelentes. impresionante", dijo Thiel. "Hicieron un intento que no fue suficiente, y no es así como lo habría hecho si hubiera intentado diseñar un sistema seguro". Un portavoz de LAION dijo a 404 Media en una declaración sobre el artículo de Stanford: "LAION es una organización sin fines de lucro que proporciona conjuntos de datos, herramientas y modelos para el avance de la investigación del aprendizaje automático. Estamos comprometidos con la educación pública abierta y la seguridad ambiental. uso de recursos mediante la reutilización de conjuntos de datos y modelos existentes. Los conjuntos de datos de LAION (más de 5,85 mil millones de entradas) se obtienen del índice web Common Crawl disponible de forma gratuita y ofrecen solo enlaces a contenido en la web pública, sin imágenes. Desarrollamos y publicamos Nuestros propios filtros rigurosos para detectar y eliminar contenido ilegal de los conjuntos de datos de LAION antes de publicarlos. Colaboramos con universidades, investigadores y ONG para mejorar estos filtros y actualmente estamos trabajando con Internet Watch Foundation (IWF) para identificar y eliminar contenido sospechoso de violar las leyes. . Invitamos a los investigadores de Stanford a unirse a LAION para mejorar nuestros conjuntos de datos y desarrollar filtros eficientes para detectar contenido dañino. LAION tiene una política de tolerancia cero para el contenido ilegal y, con mucha precaución, estamos eliminando temporalmente los conjuntos de datos de LAION para garantizar que sean seguro antes de volver a publicarlos." Este estudio sigue a un artículo de junio de Stanford que examinó el panorama de los modelos generativos visuales que podrían usarse para crear CSAM. Thiel me dijo que continuó investigando el tema después de un consejo del investigador de inteligencia artificial Alex Champandard, [que encontró la URL de una imagen en LAION-5B](https://huggingface.co/datasets/laion/laion2B-multi/discussions/ 3?ref=404media.co ) en Hugging Face que estaba subtitulado con una frase en español que parecía describir material de explotación infantil. LAION-5B está disponible para descargar desde Hugging Face como una herramienta de código abierto. Champandard me dijo observó un informe enviado a Hugging Face en LAION-5B en agosto de 2022, señalando "un ejemplo que describe algo relacionado con la pedofilia." Uno de los ingenieros que trabajó en LAION-5B respondió en marzo de 2023 diciendo que el enlace estaba inactivo pero que lo habían eliminado de todos modos porque el título era inapropiado. "Hugging Face o LAION tardaron siete meses en abordar ese informe, lo cual me pareció muy cuestionable", dijo Champandard. [](https://lh7-us.googleusercontent.com/JvxvXAe7vYRGQl8fGb0lPy3X7uzqGL1NAuxzKRcoZ_0TGSxQRn7eCBjRBS7Pz0Vx0YSAHhrxbGVyBq6KjCbkY3-GscWVLHw 8TMJVd6qHiqHQufPz5YBG9DzVJ24-oiBeEVZU49AN-_RyYbWgScWayEo) Siguiendo los tweets de Champandard , Margaret Mitchell, científica jefe de ética de Hugging Face, escribió en Mastodon: "Solo quería entrar para decir que ha habido muchas "Se ha gastado tiempo y energía tratando de encontrar CSAM, y no se ha encontrado ninguno. Algunas personas en HF están siendo atacadas como si fueran pedófilos, pero es simplemente... crueldad inapropiada". Le pregunté a Hugging Face si, a la luz de este estudio y antes de que LAION eliminara los conjuntos de datos, tomaría medidas contra los datos que tuvieran vínculos con CSAM. Un portavoz de la empresa dijo: "Sí". "El personal de Hugging Face (ni nadie que acceda al Hub) no puede ver los conjuntos de datos hasta que se cargan, y quien los carga puede decidir hacer público el contenido. Una vez compartido, la plataforma ejecuta un escaneo de contenido para identificar problemas potenciales. Los usuarios son responsables de cargarlos. y el mantenimiento del contenido, y el personal aborda los problemas siguiendo las [directrices de contenido] de la plataforma Hugging Face (https://huggingface.co/content-guidelines?ref=404media.co), que continuamos [adaptando] (https://huggingface .co/blog/content-guidelines-update?ref=404media.co ) La plataforma se basa en una combinación de análisis de contenido técnico para validar que las pautas realmente se siguen, moderación de la comunidad y funciones de informes para permitir a los usuarios plantear inquietudes. Monitoreamos los informes y tomamos medidas cuando se detecta contenido infractor", dijo el portavoz de Hugging Face. "Es fundamental para esta discusión señalar que el conjunto de datos LAION-5B contiene URL de contenido externo, no imágenes, lo que plantea desafíos adicionales. Estamos trabajando con la sociedad civil y socios de la industria para desarrollar buenas prácticas para manejar este tipo de preguntas multiplataforma. " El artículo de Stanford dice que el material detectado durante su proceso es "intrínsecamente un recuento insuficiente debido a lo incompleto de los conjuntos de hash de la industria, el desgaste del contenido alojado en vivo, la falta de acceso a los conjuntos de imágenes de referencia originales de LAION y la precisión limitada de los datos 'inseguros'. ' clasificadores de contenido." Varias empresas importantes de IA generativa, Stable Diffusion, utilizan LAION-5B, mientras que otras han utilizado los productos de LAION en diferentes etapas de desarrollo. "Los conjuntos de datos LAION también se han utilizado para entrenar otros modelos, como Imagen de Google, que se entrenó con una combinación de conjuntos de datos internos y LAION-400M", afirma el artículo de Stanford. "En particular, durante una auditoría del LAION-400M, los desarrolladores de Imagen encontraron 'una amplia gama de contenido inapropiado, incluyendo imágenes pornográficas, insultos racistas y estereotipos sociales dañinos' y lo consideraron inadecuado para uso público". Tras la publicación del artículo, un portavoz de Google dijo a 404 Media: "Imagen nunca ha utilizado LAION-5B. Más específicamente, LAION-400M se utilizó únicamente para entrenar el primer modelo de investigación de Imagen, que nunca se lanzó. Ninguna de las siguientes iteraciones de el modelo utiliza cualquier versión de los conjuntos de datos de LAION." LAION también eliminó el 400-M, por "mucha precaución" con respecto a las conclusiones del artículo. Un portavoz de Stable Diffusion dijo a 404 Media después de la publicación del artículo: "Stable Diffusion 1.5 fue lanzado por RunwayML, no por Stability AI. Este informe se centra en el conjunto de datos LAION-5b en su conjunto. Los modelos de Stability AI se entrenaron en un subconjunto filtrado de ese conjunto de datos. Además, posteriormente ajustamos estos modelos para mitigar los comportamientos residuales. Estamos comprometidos a prevenir el uso indebido de la IA y prohibir el uso de nuestros modelos y servicios de imágenes para actividades ilegales, incluidos los intentos de editar o crear CSAM. AI solo aloja versiones de Stable Diffusion que incluyen filtros en su API. Estos filtros eliminan que el contenido inseguro llegue a los modelos. Al eliminar ese contenido antes de que llegue al modelo, podemos ayudar a evitar que el modelo genere contenido inseguro. Además, Hemos implementado filtros para interceptar mensajes o resultados inseguros cuando los usuarios interactúan con modelos en nuestra plataforma. También hemos invertido en funciones de etiquetado de contenido para ayudar a identificar las imágenes generadas en nuestra plataforma. Estas capas de mitigación hacen que sea más difícil para los malos actores hacer un mal uso de la IA". ### ¿CÓMO SUCEDIÓ ESTO? El material sobre abuso infantil probablemente llegó a LAION porque la organización compiló el conjunto de datos utilizando herramientas que rastrean la web, y CSAM no está relegado a el ámbito de la "web oscura", pero prolifera en la web abierta y en muchas plataformas convencionales. [En 2022](https://www.missingkids.org/content/dam/missingkids/pdfs/2022-reports-by- esp.pdf?ref=404media.co ), Facebook realizó más de 21 millones de denuncias de CSAM a la línea informativa del Centro Nacional para Niños Desaparecidos y Explotados (NCMEC), mientras que Instagram realizó 5 millones de denuncias y Twitter realizó 98.050. Los proveedores de servicios electrónicos [ESP] están obligados por ley a reportar "aparente pornografía infantil" a CyberTipline del NCMEC cuando se dan cuenta de ellos, pero "no existen requisitos legales para realizar esfuerzos proactivos para detectar este contenido o qué información debe incluir un ESP en un informe CyberTipline", según el NCMEC. Sin embargo, un conjunto de datos es diferente de un sitio web, incluso si está compuesto por datos de una gran cantidad de sitios web. "Debido a que es Internet, habrá conjuntos de datos que contienen pornografía infantil. Twitter la tiene. Ya sabes, Facebook la tiene. Todo está ahí. No hacen un buen trabajo para vigilarlo, a pesar de que afirman que lo hacen. Y eso ahora se utilizará para entrenar estos modelos", dijo a 404 Media Marcus Rogers, decano adjunto de Iniciativas de Ciberseguridad de la Universidad Purdue. Sin embargo, las organizaciones que crean conjuntos de datos pueden estar ignorando intencionalmente la posibilidad de que CSAM pueda contaminar sus modelos, afirmó. "Las empresas simplemente no quieren saberlo. En parte, incluso si quisieran saberlo, literalmente han perdido el control de todo". "Creo que la razón por la que probablemente lo ignoran es porque no tienen una solución", dijo a 404 Media Bryce Westlake, profesor asociado en el Departamento de Estudios de Justicia y miembro de la facultad del programa de Ciencias Forenses del departamento. "Así que no quieren llamar la atención sobre eso. Porque si llaman la atención, entonces habrá que hacer algo al respecto". Las intervenciones que los creadores de conjuntos de datos podrían realizar requerirían mucha mano de obra, dijo, e incluso con esos esfuerzos en marcha es posible que no eliminen todo el conjunto de datos, dijo. "Es imposible para ellos deshacerse de todo eso. La única respuesta que la sociedad aceptará es que hay 0% allí, y es imposible hacerlo. Están en una situación en la que no salen ganando, por lo que piensan que es mejor que la gente simplemente no lo sabe." ### CÓMO EL CSAM EN LOS CONJUNTOS DE DATOS AFECTA A LAS PERSONAS REALES En un conjunto de datos de cinco mil millones de entradas, 3226 podrían parecer una gota en un océano de datos. Pero hay varias formas en que el CSAM introducido en los conjuntos de datos de LAION podría empeorar las cosas para las víctimas de la vida real. Dan Sexton, director de tecnología de Internet Watch Foundation, con sede en el Reino Unido, me dijo que el objetivo de los grupos de seguridad en Internet es evitar que más personas vean o difundan contenido abusivo y desconectarlo por completo. Hablamos meses antes de que apareciera el artículo de Stanford, cuando no sabíamos con seguridad que se estaba recopilando material sobre abuso infantil en grandes conjuntos de datos. "[Las víctimas] saben que su contenido está en un conjunto de datos que permite a una máquina crear otras imágenes, que han aprendido de su abuso, eso no es algo que creo que nadie hubiera esperado que sucediera, pero claramente no es una bienvenida. "Para cualquier niño que haya sido abusado y sus imágenes hayan circulado, excluirlo en cualquier lugar de Internet, incluidos los conjuntos de datos, es enorme", dijo. > "No hay ninguna razón por la que imágenes de niños que sufren abusos sexuales deban aparecer alguna vez en esos conjuntos de datos" Lloyd Richardson, director de tecnología de la información del Centro Canadiense para la Protección Infantil (C3P), me dijo que imagina que las víctimas anteriores de abuso sexual infantil estarían "absolutamente disgustadas, sin duda, pero probablemente no necesariamente sorprendidas" al saber que sus imágenes están vinculadas. en un conjunto de datos como LAION-5B. "Saben desde hace mucho tiempo que han tenido que lidiar con sus imágenes o imágenes y videos que circulan en Internet. Algunas cosas técnicas razonables que se podrían hacer durante la última década, simplemente no han sido bien hecho", afirmó. "No creo que nadie quiera crear una herramienta que cree imágenes de niños que sufren abuso sexual, incluso si es accidental", dijo Sexton. "La IA se trata de tener buenos datos, y si ingresas datos incorrectos, obtendrás datos incorrectos. Por supuesto, estos son datos incorrectos. No deseas generar ni eliminar imágenes de abuso sexual infantil. " Hasta ahora, se ha teorizado que los modelos de IA que son capaces de crear imágenes de abuso sexual infantil combinaban conceptos de material adulto explícito e imágenes no explícitas de niños para crear CSAM generado por IA. Según el informe de Stanford, las imágenes de abusos reales están ayudando a entrenar modelos. El CSAM generado artificialmente está en aumento y tiene el potencial de bloquear las líneas directas y disuadir los recursos de las agencias de informes que trabajan con las fuerzas del orden para encontrar a los perpetradores y desconectarlos. La Internet Watch Foundation [publicó recientemente un informe que dice](https://www.iwf.org.uk/about-us/why-we-exist/our-research/how-ai-is-being-abused-to- create-child-sexual-abuse-imagery/?ref=404media.co ) que AI CSAM es "visualmente indistinguible de CSAM real", incluso para analistas capacitados. A principios de este mes, se encontró una investigación de 404 Media personas que utilizaban la popular plataforma de generación de imágenes Civitai estaban creando lo que "podría considerarse pornografía infantil". Y en mayo, el Centro Nacional para Niños Desaparecidos y Explotados, una organización de defensa de víctimas que administra una línea directa para denunciar CSAM, [dijo que se estaba preparando para una "inundación"](https://www.bloomberg.com/news/articles /2023-05-23/predators-exploit-ai-tools-to-depict-abuse-prompting-warnings?ref=404media.co ) de contenido generado artificialmente. Richardson me dijo que los modelos reales de entrenamiento CSAM podrían significar deepfakes abusivos más realistas de las víctimas. "Se podría hacer que un delincuente descargue Stable Diffusion, cree un LoRA [adaptación de bajo rango, un modelo de aprendizaje profundo más ajustado] para una víctima específica y comience a generar nuevas imágenes sobre esta víctima", dijo. Incluso si el abuso de la víctima ocurrió hace mucho tiempo y ahora es un adulto, "ahora se les está creando nuevo material basado en el CSAM existente que existía", dijo. "Así que eso es enormemente problemático". "No hay ninguna razón por la que las imágenes de niños que sufren abuso sexual deban estar alguna vez en esos conjuntos de datos, tanto para asegurarse de que los modelos en sí no creen resultados indeseables, como también para que las víctimas se aseguren de que sus imágenes no se utilicen continuamente y se sigan utilizando para fines propósitos dañinos", dijo Sexton. OctoML, el motor que impulsa Civitai, financiado por a16z, pensó que las imágenes podrían calificarse como "pornografía infantil", pero finalmente decidió seguir trabajando con la compañía de todos modos, según muestran los chats internos de Slack y otros materiales. "Dado lo que se utiliza para entrenar, no se puede argumentar que es como tener una copia de Internet, por lo que tendrás algunas cosas allí que son malas o de alguna manera ilegales", dijo Thiel. "Lo estás poniendo en práctica entrenando los modelos en esas cosas. Y dado que tienes imágenes que se repetirán una y otra vez en ese conjunto de datos, es más probable que el modelo no solo represente el material, sino que tengas el potencial para "Semejanza entre las personas reales que se incluyeron en el conjunto de datos". ### ¿QUIÉN ES RESPONSABLE? Legalmente, todavía no hay precedentes sobre quién es responsable cuando una herramienta de raspado recopila imágenes ilegales. Como señaló Vencu en su mensaje de Discord en 2021, LAION está difundiendo enlaces, no copias reales de imágenes. "Dado que no distribuimos ni derivamos otras imágenes de los originales, no creo que se aplique la licencia de imágenes", dijo en Discord cuando se le preguntó si había material ilegal en el conjunto de datos. La infracción de derechos de autor ha sido una gran preocupación para los artistas y creadores de contenido cuyas imágenes se utilizan para entrenar modelos de IA. En abril, un fotógrafo de archivo alemán [pidió a LAION que excluyera sus fotografías de sus conjuntos de datos](https://www.vice.com/en/article/pkapb7/a-photographer-tried-to-get-his-photos-removed -from-an-ai-dataset-he-got-an-invoice-instead?ref=404media.co ), y LAION respondió facturándole $979, alegando que presentó un reclamo de derechos de autor injustificado. A principios de este año, un grupo de artistas presentó una demanda colectiva contra Stability AI, DeviantArt y Midjourney por su uso del generador de imágenes Stable Diffusion, que utiliza los conjuntos de datos de LAION. Y Getty Images recientemente demandó a Stability AI , alegando que la empresa copió más de 12 millones de imágenes sin permiso. "Tenemos problemas con esos servicios, cómo se construyeron, sobre qué se construyeron, cómo respetan o no los derechos de los creadores, y cómo realmente alimentan los deepfakes y otras cosas por el estilo", dijo el director ejecutivo de Getty Images, Craig Peters, a Associated. Prensa](https://apnews.com/article/getty-images-artificial-intelligence-ai-image-generator-stable-diffusion-a98eeaaeb2bf13c5e8874ceb6a8ce196?ref=404media.co). La difusión de CSAM es un delito federal y las leyes estadounidenses al respecto son extremadamente estrictas. Por supuesto, es ilegal poseer o transmitir archivos, pero "películas sin revelar, cintas de vídeo sin revelar y datos almacenados electrónicamente que puedan convertirse en una imagen visual de pornografía infantil" también son ilegales [según la ley federal] (https://www. Justice.gov/criminal/criminal-ceos/citizens-guide-us-federal-law-child-pornography?ref=404media.co). No está claro dónde llegarían las URL que enlazan con imágenes de explotación infantil según las leyes actuales, o en qué punto cualquiera que use estos conjuntos de datos podría estar potencialmente en peligro legal. Debido a que las leyes contra el CSAM son comprensiblemente tan estrictas, los investigadores han tenido que encontrar nuevas formas de estudiar su propagación sin infringir la ley ellos mismos. Westlake me dijo que confía en subcontratar algunas investigaciones a colegas en Canadá, como el C3P, para verificar o limpiar datos, donde existen leyes CSAM que establecen excepciones con fines de investigación. De manera similar, Stanford envió su metodología a C3P para su verificación. La Internet Watch Foundation tiene un memorando de entendimiento otorgado por el Crown Prosecution Service, la principal agencia pública de procesamiento penal en el Reino Unido, para descargar, ver y conservar contenido para sus funciones, lo que le permite buscar proactivamente contenido abusivo y informarlo a las autoridades. En Estados Unidos, ver, buscar o poseer material de explotación infantil, aunque sea accidentalmente, es un delito federal. > "Los lugares ya no deberían albergar esos conjuntos de datos para descargar". Rogers y su colega Kathryn Seigfried-Spellar en el departamento forense de Purdue tienen una situación única: están delegados y las autoridades locales les otorgan estatus de aplicación de la ley para hacer su trabajo. Tienen un espacio físico en una instalación segura para hacer cumplir la ley, con cámaras de vigilancia, llaveros, una red segura e identificación de 12 factores a donde deben ir si quieren realizar trabajos como limpiar conjuntos de datos o ver CSAM con fines de investigación o investigación. Aun así, son increíblemente cuidadosos con lo que recolectan con las herramientas de raspado. Siegfried-Spellar me dijo que está trabajando en el estudio de los nudillos y las manos porque a menudo aparecen en imágenes de abuso y son tan identificables como caras, y podría extraer imágenes de foros NSFW Reddit donde las personas publican imágenes de ellos mismos masturbándose, pero no lo hace debido a la riesgo de captar imágenes de menores de edad en la red. "Aunque tienes que ser mayor de 18 años para usar Reddit, nunca voy a extraer esos datos y usarlos, o analizarlos para mi investigación, porque no puedo verificar que alguien realmente sea mayor de edad. de 18 personas que publicaron eso", dijo. "También ha habido conversaciones sobre eso: 'hay imágenes en Internet, ¿por qué no puedo simplemente extraerlas y usarlas para mi entrenamiento de algoritmos?' Pero es porque necesito saber la edad de las fuentes." ### QUÉ HACER AHORA Debido a que LAION-5B es de código abierto, hay muchas copias flotando públicamente, incluso en Hugging Face. Eliminar el conjunto de datos de Hugging Face, extraer enlaces CSAM a imágenes abusivas del conjunto de datos y luego volver a cargarlo, por ejemplo, esencialmente crearía una hoja de ruta para alguien decidido a ver esos archivos comparando las diferencias entre los dos. Thiel me dijo que inició este estudio pensando que el objetivo podría ser eliminar material abusivo de los conjuntos de datos, pero ahora cree que es demasiado tarde. "Ahora soy más de la opinión de que [los conjuntos de datos de LAION] simplemente necesitan ser eliminados", dijo. "Los lugares ya no deberían albergar esos conjuntos de datos para su descarga. Tal vez haya un argumento para conservar copias de ellos para la capacidad de investigación, y luego se pueden seguir y tomar algunas medidas para limpiarlos". Existe un precedente al respecto, especialmente cuando se trata de datos sobre niños. La Comisión Federal de Comercio tiene un término para la eliminación de modelos como control de daños: devolución de algoritmos. Como estrategia de aplicación de la ley, la FTC ha utilizado la devolución de algoritmos en cinco casos que involucran a compañías tecnológicas que crearon modelos a partir de datos obtenidos de manera inadecuada, incluido [un acuerdo con Amazon en mayo](https://www.ftc.gov/news-events/ news/press-releases/2023/05/ftc-doj-charge-amazon-violating-childrens-privacy-law-keeping-kids-alexa-voice-recordings-forever?ref=404media.co) por cargos de que las grabaciones de voz de Alexa violó la privacidad de los niños y un acuerdo entre la FTC y el Departamento de Justicia y una aplicación de pérdida de peso para niños que [supuestamente no pudo verificarse adecuadamente] (https://cyberscoop.com/ftc-settlement-ww-weight-watchers-kurbo-children -prvacy/?ref=404media.co ) consentimiento de los padres. Ambos casos invocaron la Ley de Protección de la Privacidad Infantil en Línea (COPPA). La seguridad infantil y la inteligencia artificial se están convirtiendo rápidamente en el próximo gran campo de batalla de Internet. En abril, el senador demócrata Dick Durbin [presentó la "Ley STOP CSAM](https://www.judiciary.senate.gov/press/dem/releases/durbin-introduces-stop-csam-act-to-crack-down- on-the-proliferation-of-child-sex-abuse-material-online?ref=404media.co ),", lo que convertiría en delito que los proveedores "alojen o almacenen a sabiendas" CSAM o "promuevan o faciliten a sabiendas" el explotación sexual de niños, crear un nuevo delito federal para los servicios en línea que "promuevan o faciliten a sabiendas" delitos de explotación infantil y enmienden la Sección 230 (la ley que protege a las plataformas de la responsabilidad por las acciones de sus usuarios) para permitir acciones civiles. demandas de víctimas de delitos de explotación infantil contra proveedores de servicios en línea. Defensores de la privacidad, incluida la [Electronic Frontier Foundation](https://www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media. co) y el [Centro para la Democracia y la Tecnología](https://cdt.org/insights/the-stop-csam-act-threatens-free-expression-and-privacy-rights-of-children-and-adults/ ?ref=404media.co ) se oponen a la ley, advirtiendo que podría socavar los servicios de cifrado de extremo a extremo. La inclusión de CSAM "aparente" amplía demasiado la red, dicen, y los términos "promover" y "facilitar" son demasiado amplios. También podría tener un efecto paralizador sobre la libertad de expresión en general: "El contenido protegido por la Primera Enmienda que involucre sexualidad, orientación sexual o identidad de género probablemente será blanco de avisos de eliminación frívolos", [escribieron los abogados y expertos en vigilancia de la EFF] (https:// www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media.co) en una publicación de blog. En septiembre, los fiscales generales de 50 estados pidieron a los legisladores federales que estudiaran cómo la explotación impulsada por la IA puede poner en peligro a los niños. "Estamos inmersos en una carrera contra el tiempo para proteger a los niños de nuestro país de los peligros de la IA", [escribieron los fiscales](https://apnews.com/article/ai-child-pornography-attorneys-general-bc7f9384d469b061d603d6ba9748f38a ?ref=404media.co). "De hecho, los proverbiales muros de la ciudad ya han sido traspasados. Ahora es el momento de actuar". Thiel dijo que no se había comunicado con LAION antes de que se publicara el estudio. "No pretendemos que esto sea una especie de trampa para ninguna de las partes involucradas. Pero obviamente se cometieron muchos errores muy importantes en varias partes de todo este oleoducto", dijo. "Y en realidad no es así en absoluto cómo debería funcionar el entrenamiento modelo en el futuro". Todo esto es un problema que no va a desaparecer, ni siquiera (o especialmente) si se ignora. "Todos tienen enormes problemas asociados con el robo masivo de datos, imágenes íntimas no consensuadas, material de abuso sexual infantil, lo que sea, está ahí. Estoy un poco perplejo por cómo ha durado tanto tiempo", dijo Richardson. "No es que la tecnología sea necesariamente mala... no es que la IA sea mala. Es el hecho de que un montón de cosas fueron robadas a ciegas, y ahora estamos tratando de poner todas estas tiritas para arreglar algo que realmente nunca debería haber sucedido en primer lugar." Conviértase en suscriptor pago para obtener artículos ilimitados y sin publicidad y acceso a contenido adicional. Este sitio está financiado por suscriptores y usted impulsará directamente nuestro periodismo. *Actualización 20/12, 8:19 a. m. EST: este titular se editó para eliminar la palabra " sospechoso" porque 1.008 entradas fueron validadas externamente. * *Actualización 20/12, 11:20 a. m. EST: esta historia se corrigió para reflejar la incapacidad de Common Crawl para rastrear Twitter, Instagram y Facebook. * Actualización 20/12, 1:32 p.m. EST con comentarios de Google sobre su uso de los productos de LAION. Esta historia se ha corregido para reflejar que Google entrenó a Imagen en un subconjunto (y una versión anterior) de LAION-5B llamado LAION-400M. Sus productos actuales no utilizan conjuntos de datos LAION. Este artículo también se actualizó con comentarios de Stability AI.
](https://www.404media.co/content/images/2023/12/laion_discord_1 -1.png) CAPTURA DE PANTALLA A TRAVÉS DE LAION DISCORD La mayoría de las instituciones en los EE. UU., incluido el equipo de Thiel, no están legalmente autorizadas a ver CSAM para verificarlo ellas mismas. Para realizar investigaciones sobre CSAM, los expertos suelen recurrir al hashing perceptual, que extrae una firma digital única o huella digital. , a partir de una imagen o vídeo. PhotoDNA es una tecnología que crea hashes únicos para imágenes de explotación infantil con el fin de encontrar esas imágenes en otros lugares de la web y eliminarlas o perseguir a los abusadores o proliferadores. "Con el objetivo de cuantificar el grado en el que CSAM está presente en el conjunto de datos de entrenamiento, así como eliminarlo tanto de LAION-5B como de los conjuntos de datos derivados, utilizamos varias técnicas complementarias para identificar CSAM potencial en el conjunto de datos: detección perceptiva basada en hash, detección criptográfica basada en hash y análisis de vecinos más cercanos aprovechando las incrustaciones de imágenes en el propio conjunto de datos", dice el documento. A través de este proceso, identificaron al menos 2000 entradas en conjuntos de datos de sospecha de CSAM y confirmaron esas entradas con terceros. Para realizar su investigación, Thiel dijo que se centró en las URL identificadas por el clasificador de seguridad de LAION como "no seguras para el trabajo" y envió esas URL a PhotoDNA. Las coincidencias de hash indican CSAM definido y conocido, y se enviaron a la API del Proyecto Arachnid Shield y fueron validadas por el Centro Canadiense para la Protección Infantil, que puede ver, verificar e informar esas imágenes a las autoridades. Una vez que se verificaron esas imágenes, también pudieron encontrar coincidencias de "vecinos más cercanos" dentro del conjunto de datos, donde se agruparon imágenes relacionadas de las víctimas. LAION podría haber utilizado un método similar a este antes de publicar el conjunto de datos de entrenamiento de IA más grande del mundo, dijo Thiel, pero no lo hizo. "[LAION] inicialmente usó CLIP para tratar de filtrar algunas cosas, pero no parece que lo hicieran originalmente consultando con ningún experto en seguridad infantil. Fue bueno que lo intentaran. Pero los mecanismos que usaron simplemente no fueron excelentes. impresionante", dijo Thiel. "Hicieron un intento que no fue suficiente, y no es así como lo habría hecho si hubiera intentado diseñar un sistema seguro". Un portavoz de LAION dijo a 404 Media en una declaración sobre el artículo de Stanford: "LAION es una organización sin fines de lucro que proporciona conjuntos de datos, herramientas y modelos para el avance de la investigación del aprendizaje automático. Estamos comprometidos con la educación pública abierta y la seguridad ambiental. uso de recursos mediante la reutilización de conjuntos de datos y modelos existentes. Los conjuntos de datos de LAION (más de 5,85 mil millones de entradas) se obtienen del índice web Common Crawl disponible de forma gratuita y ofrecen solo enlaces a contenido en la web pública, sin imágenes. Desarrollamos y publicamos Nuestros propios filtros rigurosos para detectar y eliminar contenido ilegal de los conjuntos de datos de LAION antes de publicarlos. Colaboramos con universidades, investigadores y ONG para mejorar estos filtros y actualmente estamos trabajando con Internet Watch Foundation (IWF) para identificar y eliminar contenido sospechoso de violar las leyes. . Invitamos a los investigadores de Stanford a unirse a LAION para mejorar nuestros conjuntos de datos y desarrollar filtros eficientes para detectar contenido dañino. LAION tiene una política de tolerancia cero para el contenido ilegal y, con mucha precaución, estamos eliminando temporalmente los conjuntos de datos de LAION para garantizar que sean seguro antes de volver a publicarlos." Este estudio sigue a un artículo de junio de Stanford que examinó el panorama de los modelos generativos visuales que podrían usarse para crear CSAM. Thiel me dijo que continuó investigando el tema después de un consejo del investigador de inteligencia artificial Alex Champandard, [que encontró la URL de una imagen en LAION-5B](https://huggingface.co/datasets/laion/laion2B-multi/discussions/ 3?ref=404media.co ) en Hugging Face que estaba subtitulado con una frase en español que parecía describir material de explotación infantil. LAION-5B está disponible para descargar desde Hugging Face como una herramienta de código abierto. Champandard me dijo observó un informe enviado a Hugging Face en LAION-5B en agosto de 2022, señalando "un ejemplo que describe algo relacionado con la pedofilia." Uno de los ingenieros que trabajó en LAION-5B respondió en marzo de 2023 diciendo que el enlace estaba inactivo pero que lo habían eliminado de todos modos porque el título era inapropiado. "Hugging Face o LAION tardaron siete meses en abordar ese informe, lo cual me pareció muy cuestionable", dijo Champandard. [](https://lh7-us.googleusercontent.com/JvxvXAe7vYRGQl8fGb0lPy3X7uzqGL1NAuxzKRcoZ_0TGSxQRn7eCBjRBS7Pz0Vx0YSAHhrxbGVyBq6KjCbkY3-GscWVLHw 8TMJVd6qHiqHQufPz5YBG9DzVJ24-oiBeEVZU49AN-_RyYbWgScWayEo) Siguiendo los tweets de Champandard , Margaret Mitchell, científica jefe de ética de Hugging Face, escribió en Mastodon: "Solo quería entrar para decir que ha habido muchas "Se ha gastado tiempo y energía tratando de encontrar CSAM, y no se ha encontrado ninguno. Algunas personas en HF están siendo atacadas como si fueran pedófilos, pero es simplemente... crueldad inapropiada". Le pregunté a Hugging Face si, a la luz de este estudio y antes de que LAION eliminara los conjuntos de datos, tomaría medidas contra los datos que tuvieran vínculos con CSAM. Un portavoz de la empresa dijo: "Sí". "El personal de Hugging Face (ni nadie que acceda al Hub) no puede ver los conjuntos de datos hasta que se cargan, y quien los carga puede decidir hacer público el contenido. Una vez compartido, la plataforma ejecuta un escaneo de contenido para identificar problemas potenciales. Los usuarios son responsables de cargarlos. y el mantenimiento del contenido, y el personal aborda los problemas siguiendo las [directrices de contenido] de la plataforma Hugging Face (https://huggingface.co/content-guidelines?ref=404media.co), que continuamos [adaptando] (https://huggingface .co/blog/content-guidelines-update?ref=404media.co ) La plataforma se basa en una combinación de análisis de contenido técnico para validar que las pautas realmente se siguen, moderación de la comunidad y funciones de informes para permitir a los usuarios plantear inquietudes. Monitoreamos los informes y tomamos medidas cuando se detecta contenido infractor", dijo el portavoz de Hugging Face. "Es fundamental para esta discusión señalar que el conjunto de datos LAION-5B contiene URL de contenido externo, no imágenes, lo que plantea desafíos adicionales. Estamos trabajando con la sociedad civil y socios de la industria para desarrollar buenas prácticas para manejar este tipo de preguntas multiplataforma. " El artículo de Stanford dice que el material detectado durante su proceso es "intrínsecamente un recuento insuficiente debido a lo incompleto de los conjuntos de hash de la industria, el desgaste del contenido alojado en vivo, la falta de acceso a los conjuntos de imágenes de referencia originales de LAION y la precisión limitada de los datos 'inseguros'. ' clasificadores de contenido." Varias empresas importantes de IA generativa, Stable Diffusion, utilizan LAION-5B, mientras que otras han utilizado los productos de LAION en diferentes etapas de desarrollo. "Los conjuntos de datos LAION también se han utilizado para entrenar otros modelos, como Imagen de Google, que se entrenó con una combinación de conjuntos de datos internos y LAION-400M", afirma el artículo de Stanford. "En particular, durante una auditoría del LAION-400M, los desarrolladores de Imagen encontraron 'una amplia gama de contenido inapropiado, incluyendo imágenes pornográficas, insultos racistas y estereotipos sociales dañinos' y lo consideraron inadecuado para uso público". Tras la publicación del artículo, un portavoz de Google dijo a 404 Media: "Imagen nunca ha utilizado LAION-5B. Más específicamente, LAION-400M se utilizó únicamente para entrenar el primer modelo de investigación de Imagen, que nunca se lanzó. Ninguna de las siguientes iteraciones de el modelo utiliza cualquier versión de los conjuntos de datos de LAION." LAION también eliminó el 400-M, por "mucha precaución" con respecto a las conclusiones del artículo. Un portavoz de Stable Diffusion dijo a 404 Media después de la publicación del artículo: "Stable Diffusion 1.5 fue lanzado por RunwayML, no por Stability AI. Este informe se centra en el conjunto de datos LAION-5b en su conjunto. Los modelos de Stability AI se entrenaron en un subconjunto filtrado de ese conjunto de datos. Además, posteriormente ajustamos estos modelos para mitigar los comportamientos residuales. Estamos comprometidos a prevenir el uso indebido de la IA y prohibir el uso de nuestros modelos y servicios de imágenes para actividades ilegales, incluidos los intentos de editar o crear CSAM. AI solo aloja versiones de Stable Diffusion que incluyen filtros en su API. Estos filtros eliminan que el contenido inseguro llegue a los modelos. Al eliminar ese contenido antes de que llegue al modelo, podemos ayudar a evitar que el modelo genere contenido inseguro. Además, Hemos implementado filtros para interceptar mensajes o resultados inseguros cuando los usuarios interactúan con modelos en nuestra plataforma. También hemos invertido en funciones de etiquetado de contenido para ayudar a identificar las imágenes generadas en nuestra plataforma. Estas capas de mitigación hacen que sea más difícil para los malos actores hacer un mal uso de la IA". ### ¿CÓMO SUCEDIÓ ESTO? El material sobre abuso infantil probablemente llegó a LAION porque la organización compiló el conjunto de datos utilizando herramientas que rastrean la web, y CSAM no está relegado a el ámbito de la "web oscura", pero prolifera en la web abierta y en muchas plataformas convencionales. [En 2022](https://www.missingkids.org/content/dam/missingkids/pdfs/2022-reports-by- esp.pdf?ref=404media.co ), Facebook realizó más de 21 millones de denuncias de CSAM a la línea informativa del Centro Nacional para Niños Desaparecidos y Explotados (NCMEC), mientras que Instagram realizó 5 millones de denuncias y Twitter realizó 98.050. Los proveedores de servicios electrónicos [ESP] están obligados por ley a reportar "aparente pornografía infantil" a CyberTipline del NCMEC cuando se dan cuenta de ellos, pero "no existen requisitos legales para realizar esfuerzos proactivos para detectar este contenido o qué información debe incluir un ESP en un informe CyberTipline", según el NCMEC. Sin embargo, un conjunto de datos es diferente de un sitio web, incluso si está compuesto por datos de una gran cantidad de sitios web. "Debido a que es Internet, habrá conjuntos de datos que contienen pornografía infantil. Twitter la tiene. Ya sabes, Facebook la tiene. Todo está ahí. No hacen un buen trabajo para vigilarlo, a pesar de que afirman que lo hacen. Y eso ahora se utilizará para entrenar estos modelos", dijo a 404 Media Marcus Rogers, decano adjunto de Iniciativas de Ciberseguridad de la Universidad Purdue. Sin embargo, las organizaciones que crean conjuntos de datos pueden estar ignorando intencionalmente la posibilidad de que CSAM pueda contaminar sus modelos, afirmó. "Las empresas simplemente no quieren saberlo. En parte, incluso si quisieran saberlo, literalmente han perdido el control de todo". "Creo que la razón por la que probablemente lo ignoran es porque no tienen una solución", dijo a 404 Media Bryce Westlake, profesor asociado en el Departamento de Estudios de Justicia y miembro de la facultad del programa de Ciencias Forenses del departamento. "Así que no quieren llamar la atención sobre eso. Porque si llaman la atención, entonces habrá que hacer algo al respecto". Las intervenciones que los creadores de conjuntos de datos podrían realizar requerirían mucha mano de obra, dijo, e incluso con esos esfuerzos en marcha es posible que no eliminen todo el conjunto de datos, dijo. "Es imposible para ellos deshacerse de todo eso. La única respuesta que la sociedad aceptará es que hay 0% allí, y es imposible hacerlo. Están en una situación en la que no salen ganando, por lo que piensan que es mejor que la gente simplemente no lo sabe." ### CÓMO EL CSAM EN LOS CONJUNTOS DE DATOS AFECTA A LAS PERSONAS REALES En un conjunto de datos de cinco mil millones de entradas, 3226 podrían parecer una gota en un océano de datos. Pero hay varias formas en que el CSAM introducido en los conjuntos de datos de LAION podría empeorar las cosas para las víctimas de la vida real. Dan Sexton, director de tecnología de Internet Watch Foundation, con sede en el Reino Unido, me dijo que el objetivo de los grupos de seguridad en Internet es evitar que más personas vean o difundan contenido abusivo y desconectarlo por completo. Hablamos meses antes de que apareciera el artículo de Stanford, cuando no sabíamos con seguridad que se estaba recopilando material sobre abuso infantil en grandes conjuntos de datos. "[Las víctimas] saben que su contenido está en un conjunto de datos que permite a una máquina crear otras imágenes, que han aprendido de su abuso, eso no es algo que creo que nadie hubiera esperado que sucediera, pero claramente no es una bienvenida. "Para cualquier niño que haya sido abusado y sus imágenes hayan circulado, excluirlo en cualquier lugar de Internet, incluidos los conjuntos de datos, es enorme", dijo. > "No hay ninguna razón por la que imágenes de niños que sufren abusos sexuales deban aparecer alguna vez en esos conjuntos de datos" Lloyd Richardson, director de tecnología de la información del Centro Canadiense para la Protección Infantil (C3P), me dijo que imagina que las víctimas anteriores de abuso sexual infantil estarían "absolutamente disgustadas, sin duda, pero probablemente no necesariamente sorprendidas" al saber que sus imágenes están vinculadas. en un conjunto de datos como LAION-5B. "Saben desde hace mucho tiempo que han tenido que lidiar con sus imágenes o imágenes y videos que circulan en Internet. Algunas cosas técnicas razonables que se podrían hacer durante la última década, simplemente no han sido bien hecho", afirmó. "No creo que nadie quiera crear una herramienta que cree imágenes de niños que sufren abuso sexual, incluso si es accidental", dijo Sexton. "La IA se trata de tener buenos datos, y si ingresas datos incorrectos, obtendrás datos incorrectos. Por supuesto, estos son datos incorrectos. No deseas generar ni eliminar imágenes de abuso sexual infantil. " Hasta ahora, se ha teorizado que los modelos de IA que son capaces de crear imágenes de abuso sexual infantil combinaban conceptos de material adulto explícito e imágenes no explícitas de niños para crear CSAM generado por IA. Según el informe de Stanford, las imágenes de abusos reales están ayudando a entrenar modelos. El CSAM generado artificialmente está en aumento y tiene el potencial de bloquear las líneas directas y disuadir los recursos de las agencias de informes que trabajan con las fuerzas del orden para encontrar a los perpetradores y desconectarlos. La Internet Watch Foundation [publicó recientemente un informe que dice](https://www.iwf.org.uk/about-us/why-we-exist/our-research/how-ai-is-being-abused-to- create-child-sexual-abuse-imagery/?ref=404media.co ) que AI CSAM es "visualmente indistinguible de CSAM real", incluso para analistas capacitados. A principios de este mes, se encontró una investigación de 404 Media personas que utilizaban la popular plataforma de generación de imágenes Civitai estaban creando lo que "podría considerarse pornografía infantil". Y en mayo, el Centro Nacional para Niños Desaparecidos y Explotados, una organización de defensa de víctimas que administra una línea directa para denunciar CSAM, [dijo que se estaba preparando para una "inundación"](https://www.bloomberg.com/news/articles /2023-05-23/predators-exploit-ai-tools-to-depict-abuse-prompting-warnings?ref=404media.co ) de contenido generado artificialmente. Richardson me dijo que los modelos reales de entrenamiento CSAM podrían significar deepfakes abusivos más realistas de las víctimas. "Se podría hacer que un delincuente descargue Stable Diffusion, cree un LoRA [adaptación de bajo rango, un modelo de aprendizaje profundo más ajustado] para una víctima específica y comience a generar nuevas imágenes sobre esta víctima", dijo. Incluso si el abuso de la víctima ocurrió hace mucho tiempo y ahora es un adulto, "ahora se les está creando nuevo material basado en el CSAM existente que existía", dijo. "Así que eso es enormemente problemático". "No hay ninguna razón por la que las imágenes de niños que sufren abuso sexual deban estar alguna vez en esos conjuntos de datos, tanto para asegurarse de que los modelos en sí no creen resultados indeseables, como también para que las víctimas se aseguren de que sus imágenes no se utilicen continuamente y se sigan utilizando para fines propósitos dañinos", dijo Sexton. OctoML, el motor que impulsa Civitai, financiado por a16z, pensó que las imágenes podrían calificarse como "pornografía infantil", pero finalmente decidió seguir trabajando con la compañía de todos modos, según muestran los chats internos de Slack y otros materiales. "Dado lo que se utiliza para entrenar, no se puede argumentar que es como tener una copia de Internet, por lo que tendrás algunas cosas allí que son malas o de alguna manera ilegales", dijo Thiel. "Lo estás poniendo en práctica entrenando los modelos en esas cosas. Y dado que tienes imágenes que se repetirán una y otra vez en ese conjunto de datos, es más probable que el modelo no solo represente el material, sino que tengas el potencial para "Semejanza entre las personas reales que se incluyeron en el conjunto de datos". ### ¿QUIÉN ES RESPONSABLE? Legalmente, todavía no hay precedentes sobre quién es responsable cuando una herramienta de raspado recopila imágenes ilegales. Como señaló Vencu en su mensaje de Discord en 2021, LAION está difundiendo enlaces, no copias reales de imágenes. "Dado que no distribuimos ni derivamos otras imágenes de los originales, no creo que se aplique la licencia de imágenes", dijo en Discord cuando se le preguntó si había material ilegal en el conjunto de datos. La infracción de derechos de autor ha sido una gran preocupación para los artistas y creadores de contenido cuyas imágenes se utilizan para entrenar modelos de IA. En abril, un fotógrafo de archivo alemán [pidió a LAION que excluyera sus fotografías de sus conjuntos de datos](https://www.vice.com/en/article/pkapb7/a-photographer-tried-to-get-his-photos-removed -from-an-ai-dataset-he-got-an-invoice-instead?ref=404media.co ), y LAION respondió facturándole $979, alegando que presentó un reclamo de derechos de autor injustificado. A principios de este año, un grupo de artistas presentó una demanda colectiva contra Stability AI, DeviantArt y Midjourney por su uso del generador de imágenes Stable Diffusion, que utiliza los conjuntos de datos de LAION. Y Getty Images recientemente demandó a Stability AI , alegando que la empresa copió más de 12 millones de imágenes sin permiso. "Tenemos problemas con esos servicios, cómo se construyeron, sobre qué se construyeron, cómo respetan o no los derechos de los creadores, y cómo realmente alimentan los deepfakes y otras cosas por el estilo", dijo el director ejecutivo de Getty Images, Craig Peters, a Associated. Prensa](https://apnews.com/article/getty-images-artificial-intelligence-ai-image-generator-stable-diffusion-a98eeaaeb2bf13c5e8874ceb6a8ce196?ref=404media.co). La difusión de CSAM es un delito federal y las leyes estadounidenses al respecto son extremadamente estrictas. Por supuesto, es ilegal poseer o transmitir archivos, pero "películas sin revelar, cintas de vídeo sin revelar y datos almacenados electrónicamente que puedan convertirse en una imagen visual de pornografía infantil" también son ilegales [según la ley federal] (https://www. Justice.gov/criminal/criminal-ceos/citizens-guide-us-federal-law-child-pornography?ref=404media.co). No está claro dónde llegarían las URL que enlazan con imágenes de explotación infantil según las leyes actuales, o en qué punto cualquiera que use estos conjuntos de datos podría estar potencialmente en peligro legal. Debido a que las leyes contra el CSAM son comprensiblemente tan estrictas, los investigadores han tenido que encontrar nuevas formas de estudiar su propagación sin infringir la ley ellos mismos. Westlake me dijo que confía en subcontratar algunas investigaciones a colegas en Canadá, como el C3P, para verificar o limpiar datos, donde existen leyes CSAM que establecen excepciones con fines de investigación. De manera similar, Stanford envió su metodología a C3P para su verificación. La Internet Watch Foundation tiene un memorando de entendimiento otorgado por el Crown Prosecution Service, la principal agencia pública de procesamiento penal en el Reino Unido, para descargar, ver y conservar contenido para sus funciones, lo que le permite buscar proactivamente contenido abusivo y informarlo a las autoridades. En Estados Unidos, ver, buscar o poseer material de explotación infantil, aunque sea accidentalmente, es un delito federal. > "Los lugares ya no deberían albergar esos conjuntos de datos para descargar". Rogers y su colega Kathryn Seigfried-Spellar en el departamento forense de Purdue tienen una situación única: están delegados y las autoridades locales les otorgan estatus de aplicación de la ley para hacer su trabajo. Tienen un espacio físico en una instalación segura para hacer cumplir la ley, con cámaras de vigilancia, llaveros, una red segura e identificación de 12 factores a donde deben ir si quieren realizar trabajos como limpiar conjuntos de datos o ver CSAM con fines de investigación o investigación. Aun así, son increíblemente cuidadosos con lo que recolectan con las herramientas de raspado. Siegfried-Spellar me dijo que está trabajando en el estudio de los nudillos y las manos porque a menudo aparecen en imágenes de abuso y son tan identificables como caras, y podría extraer imágenes de foros NSFW Reddit donde las personas publican imágenes de ellos mismos masturbándose, pero no lo hace debido a la riesgo de captar imágenes de menores de edad en la red. "Aunque tienes que ser mayor de 18 años para usar Reddit, nunca voy a extraer esos datos y usarlos, o analizarlos para mi investigación, porque no puedo verificar que alguien realmente sea mayor de edad. de 18 personas que publicaron eso", dijo. "También ha habido conversaciones sobre eso: 'hay imágenes en Internet, ¿por qué no puedo simplemente extraerlas y usarlas para mi entrenamiento de algoritmos?' Pero es porque necesito saber la edad de las fuentes." ### QUÉ HACER AHORA Debido a que LAION-5B es de código abierto, hay muchas copias flotando públicamente, incluso en Hugging Face. Eliminar el conjunto de datos de Hugging Face, extraer enlaces CSAM a imágenes abusivas del conjunto de datos y luego volver a cargarlo, por ejemplo, esencialmente crearía una hoja de ruta para alguien decidido a ver esos archivos comparando las diferencias entre los dos. Thiel me dijo que inició este estudio pensando que el objetivo podría ser eliminar material abusivo de los conjuntos de datos, pero ahora cree que es demasiado tarde. "Ahora soy más de la opinión de que [los conjuntos de datos de LAION] simplemente necesitan ser eliminados", dijo. "Los lugares ya no deberían albergar esos conjuntos de datos para su descarga. Tal vez haya un argumento para conservar copias de ellos para la capacidad de investigación, y luego se pueden seguir y tomar algunas medidas para limpiarlos". Existe un precedente al respecto, especialmente cuando se trata de datos sobre niños. La Comisión Federal de Comercio tiene un término para la eliminación de modelos como control de daños: devolución de algoritmos. Como estrategia de aplicación de la ley, la FTC ha utilizado la devolución de algoritmos en cinco casos que involucran a compañías tecnológicas que crearon modelos a partir de datos obtenidos de manera inadecuada, incluido [un acuerdo con Amazon en mayo](https://www.ftc.gov/news-events/ news/press-releases/2023/05/ftc-doj-charge-amazon-violating-childrens-privacy-law-keeping-kids-alexa-voice-recordings-forever?ref=404media.co) por cargos de que las grabaciones de voz de Alexa violó la privacidad de los niños y un acuerdo entre la FTC y el Departamento de Justicia y una aplicación de pérdida de peso para niños que [supuestamente no pudo verificarse adecuadamente] (https://cyberscoop.com/ftc-settlement-ww-weight-watchers-kurbo-children -prvacy/?ref=404media.co ) consentimiento de los padres. Ambos casos invocaron la Ley de Protección de la Privacidad Infantil en Línea (COPPA). La seguridad infantil y la inteligencia artificial se están convirtiendo rápidamente en el próximo gran campo de batalla de Internet. En abril, el senador demócrata Dick Durbin [presentó la "Ley STOP CSAM](https://www.judiciary.senate.gov/press/dem/releases/durbin-introduces-stop-csam-act-to-crack-down- on-the-proliferation-of-child-sex-abuse-material-online?ref=404media.co ),", lo que convertiría en delito que los proveedores "alojen o almacenen a sabiendas" CSAM o "promuevan o faciliten a sabiendas" el explotación sexual de niños, crear un nuevo delito federal para los servicios en línea que "promuevan o faciliten a sabiendas" delitos de explotación infantil y enmienden la Sección 230 (la ley que protege a las plataformas de la responsabilidad por las acciones de sus usuarios) para permitir acciones civiles. demandas de víctimas de delitos de explotación infantil contra proveedores de servicios en línea. Defensores de la privacidad, incluida la [Electronic Frontier Foundation](https://www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media. co) y el [Centro para la Democracia y la Tecnología](https://cdt.org/insights/the-stop-csam-act-threatens-free-expression-and-privacy-rights-of-children-and-adults/ ?ref=404media.co ) se oponen a la ley, advirtiendo que podría socavar los servicios de cifrado de extremo a extremo. La inclusión de CSAM "aparente" amplía demasiado la red, dicen, y los términos "promover" y "facilitar" son demasiado amplios. También podría tener un efecto paralizador sobre la libertad de expresión en general: "El contenido protegido por la Primera Enmienda que involucre sexualidad, orientación sexual o identidad de género probablemente será blanco de avisos de eliminación frívolos", [escribieron los abogados y expertos en vigilancia de la EFF] (https:// www.eff.org/deeplinks/2023/04/stop-csam-act-would-put-security-and-free-speech-risk?ref=404media.co) en una publicación de blog. En septiembre, los fiscales generales de 50 estados pidieron a los legisladores federales que estudiaran cómo la explotación impulsada por la IA puede poner en peligro a los niños. "Estamos inmersos en una carrera contra el tiempo para proteger a los niños de nuestro país de los peligros de la IA", [escribieron los fiscales](https://apnews.com/article/ai-child-pornography-attorneys-general-bc7f9384d469b061d603d6ba9748f38a ?ref=404media.co). "De hecho, los proverbiales muros de la ciudad ya han sido traspasados. Ahora es el momento de actuar". Thiel dijo que no se había comunicado con LAION antes de que se publicara el estudio. "No pretendemos que esto sea una especie de trampa para ninguna de las partes involucradas. Pero obviamente se cometieron muchos errores muy importantes en varias partes de todo este oleoducto", dijo. "Y en realidad no es así en absoluto cómo debería funcionar el entrenamiento modelo en el futuro". Todo esto es un problema que no va a desaparecer, ni siquiera (o especialmente) si se ignora. "Todos tienen enormes problemas asociados con el robo masivo de datos, imágenes íntimas no consensuadas, material de abuso sexual infantil, lo que sea, está ahí. Estoy un poco perplejo por cómo ha durado tanto tiempo", dijo Richardson. "No es que la tecnología sea necesariamente mala... no es que la IA sea mala. Es el hecho de que un montón de cosas fueron robadas a ciegas, y ahora estamos tratando de poner todas estas tiritas para arreglar algo que realmente nunca debería haber sucedido en primer lugar." Conviértase en suscriptor pago para obtener artículos ilimitados y sin publicidad y acceso a contenido adicional. Este sitio está financiado por suscriptores y usted impulsará directamente nuestro periodismo. *Actualización 20/12, 8:19 a. m. EST: este titular se editó para eliminar la palabra " sospechoso" porque 1.008 entradas fueron validadas externamente. * *Actualización 20/12, 11:20 a. m. EST: esta historia se corrigió para reflejar la incapacidad de Common Crawl para rastrear Twitter, Instagram y Facebook. * Actualización 20/12, 1:32 p.m. EST con comentarios de Google sobre su uso de los productos de LAION. Esta historia se ha corregido para reflejar que Google entrenó a Imagen en un subconjunto (y una versión anterior) de LAION-5B llamado LAION-400M. Sus productos actuales no utilizan conjuntos de datos LAION. Este artículo también se actualizó con comentarios de Stability AI.