Problema 6784

El martes, investigadores de Stanford y Yale revelaron algo que las empresas de IA preferirían mantener oculto. Cuatro populares modelos de lenguaje de gran tamaño —GPT de OpenAI, Claude de Anthropic, Gemini de Google y Grok de xAI— han almacenado grandes porciones de algunos de los libros con los que han sido entrenados y pueden reproducir largos extractos de ellos.
De hecho, cuando los investigadores le indicaron estratégicamente, Claude entregó el texto casi completo de Harry Potter y la Piedra Filosofal, El Gran Gatsby, 1984 y Frankenstein, además de miles de palabras de libros como Los Juegos del Hambre y El Guardián entre el Centeno. Los otros tres modelos también reprodujeron cantidades variables de estos libros. Se analizaron trece libros.
Este fenómeno se ha denominado "memorización", y las empresas de IA han negado durante mucho tiempo que ocurra a gran escala. En una carta de 2023 dirigida a la Oficina de Derechos de Autor de EE. UU., OpenAI afirmó que "los modelos no almacenan copias de la información que aprenden". De igual manera, Google indicó a la Oficina de Derechos de Autor que "no existe ninguna copia de los datos de entrenamiento, ya sean texto, imágenes u otros formatos, presente en el propio modelo". Anthropic, Meta, Microsoft y otras empresas han hecho afirmaciones similares. (Ninguna de las empresas de IA mencionadas en este artículo accedió a mis solicitudes de entrevista).
El estudio de Stanford demuestra que existen tales copias en los modelos de IA, y es solo el último de varios estudios que lo demuestran. En mis propias investigaciones, he descubierto que los modelos basados en imágenes pueden reproducir parte del arte y las fotografías con las que se entrenan. Esto podría representar una enorme responsabilidad legal para las empresas de IA, que podría costarle a la industria miles de millones de dólares en juicios por infracción de derechos de autor y provocar la retirada de productos del mercado. También contradice la explicación básica que da la industria de la IA sobre el funcionamiento de su tecnología.
La IA se explica frecuentemente en términos de metáforas; las empresas tecnológicas suelen decir que sus productos aprenden, que los LLM, por ejemplo, han desarrollado una comprensión de la escritura inglesa sin que se les expliquen explícitamente las reglas gramaticales. Esta nueva investigación, junto con varios otros estudios de los últimos dos años, desmiente esa metáfora. La IA no absorbe información como lo hace la mente humana. En cambio, la almacena y accede a ella.
De hecho, muchos desarrolladores de IA usan un término técnicamente más preciso al referirse a estos modelos: compresión con pérdida. Este término también está empezando a ganar terreno fuera de la industria. La frase fue invocada recientemente por un tribunal alemán que falló en contra de OpenAI en un caso presentado por GEMA, una organización de licencias musicales. GEMA demostró que ChatGPT podía generar imitaciones precisas de las letras de las canciones. El juez comparó el modelo con archivos MP3 y JPEG, que almacenan la música y las fotos en archivos más pequeños que los originales sin comprimir. Al almacenar una foto de alta calidad como JPEG, por ejemplo, el resultado es una foto de calidad ligeramente inferior, en algunos casos con desenfoque o artefactos visuales añadidos. Un algoritmo de compresión con pérdida aún almacena la foto, pero es una aproximación en lugar del archivo exacto. Se llama compresión con pérdida porque se pierden algunos datos.
Desde una perspectiva técnica, este proceso de compresión es muy similar a lo que ocurre dentro de los modelos de IA, como me han explicado investigadores de varias empresas y universidades de IA en los últimos meses. Estos modelos ingieren texto e imágenes, y generan texto e imágenes que se aproximan a esas entradas.
Pero esta simple descripción es menos útil para las empresas de IA que la metáfora del aprendizaje, que se ha utilizado para afirmar que los algoritmos estadísticos conocidos como IA eventualmente realizarán nuevos descubrimientos científicos, experimentarán mejoras ilimitadas y se entrenarán recursivamente, lo que posiblemente conducirá a una "explosión de inteligencia". Toda la industria se basa en una metáfora poco sólida.
El problema se aclara si observamos los generadores de imágenes de IA. En septiembre de 2022, Emad Mostaque, cofundador y entonces director ejecutivo de Stability AI, explicó en una entrevista de podcast cómo se construyó Stable Diffusion, el modelo de imagen de Stability. "Tomamos 100.000 gigabytes de imágenes y los comprimimos en un archivo de dos gigabytes que puede recrear cualquiera de esas imágenes y sus iteraciones", afirmó.
Uno de los muchos expertos con los que hablé mientras escribía este artículo fue un investigador independiente de IA que ha estudiado la capacidad de Stable Diffusion para reproducir sus imágenes de entrenamiento. (Acepté mantener el anonimato del investigador, por temor a las repercusiones de las principales empresas de IA). Arriba se muestra un ejemplo de esta capacidad: a la izquierda se muestra la imagen original de la web (una imagen promocional del programa de televisión Garfunkel y Oates) y a la derecha una versión que Stable Diffusion generó al aparecer con un subtítulo en la web, que incluye código HTML: "IFC cancela Garfunkel y Oates". Con esta sencilla técnica, el investigador me mostró cómo producir copias casi exactas de varias docenas de imágenes que se sabe que están en el conjunto de entrenamiento de Stable Diffusion, la mayoría de las cuales incluyen residuos visuales que se parecen a la compresión con pérdida, el tipo de efecto borroso y con fallos que se puede observar en las fotos de vez en cuando.

Fuente: Karla Ortiz
Obra original de Karla Ortiz (La Muerte Que Traigo, 2016, Grafito)

Fuente: Tribunal de Distrito de los Estados Unidos, Distrito Norte de California
Resultado del producto Reimagine XL de Stability (basado en Stable Diffusion XL)
Arriba se muestran otras dos imágenes tomadas de una demanda contra Stability AI y otras empresas. A la izquierda, una obra original de Karla Ortiz, y a la derecha, una variación de Stable Diffusion. En esta imagen, la imagen se aleja un poco del original. Algunos elementos han cambiado. En lugar de comprimir a nivel de píxel, el algoritmo parece copiar y manipular objetos de varias imágenes, manteniendo cierta continuidad visual.
Según explican las empresas, los algoritmos de IA extraen "conceptos" de los datos de entrenamiento y aprenden a crear obras originales. Pero la imagen de la derecha no es solo producto de conceptos. No es una imagen genérica de, por ejemplo, "un ángel con pájaros". Es difícil determinar por qué un modelo de IA deja una marca específica en una imagen, pero podemos asumir razonablemente que Stable Diffusion puede renderizar la imagen de la derecha en parte porque ha almacenado elementos visuales de la imagen de la izquierda. No se trata de un collage en el sentido físico de cortar y pegar, pero tampoco es aprendizaje en el sentido humano que implica la palabra. El modelo carece de sentidos ni experiencia consciente para emitir sus propios juicios estéticos.
Google ha escrito que los LLM no almacenan copias de sus datos de entrenamiento, sino los "patrones del lenguaje humano". Esto es cierto a primera vista, pero engañoso al analizarlo a fondo. Como se ha documentado ampliamente (https://huggingface.co/learn/llm-course/en/chapter2/4), cuando una empresa utiliza un libro para desarrollar un modelo de IA, divide el texto del libro en fragmentos o fragmentos de palabras. Por ejemplo, la frase hola, amigo podría estar representada por los fragmentos él, llo, mi, fri y fin. Algunos fragmentos son palabras reales; otros son simplemente grupos de letras, espacios y puntuación. El modelo almacena estos fragmentos y los contextos en los que aparecen en los libros. El LLM resultante es esencialmente una enorme base de datos de contextos y los fragmentos que tienen más probabilidades de aparecer a continuación.
El modelo puede visualizarse como un mapa. Aquí hay un ejemplo, con los tokens más probables de Llama-3.1-70B de Meta:
Fuente: The Atlantic/ Llama
Cuando un LLM "escribe" una oración, recorre un camino a través de este bosque de posibles secuencias de tokens, tomando una decisión de alta probabilidad en cada paso. La descripción de Google es engañosa porque las predicciones del siguiente token no provienen de una entidad vaga como el "lenguaje humano", sino de los libros, artículos y otros textos específicos que el modelo ha escaneado.
Por defecto, los modelos a veces se desvían del siguiente token más probable. Este comportamiento suele ser enmarcado por las empresas de IA como una forma de hacer que los modelos sean más "creativos", pero también tiene la ventaja de ocultar copias del texto de entrenamiento.
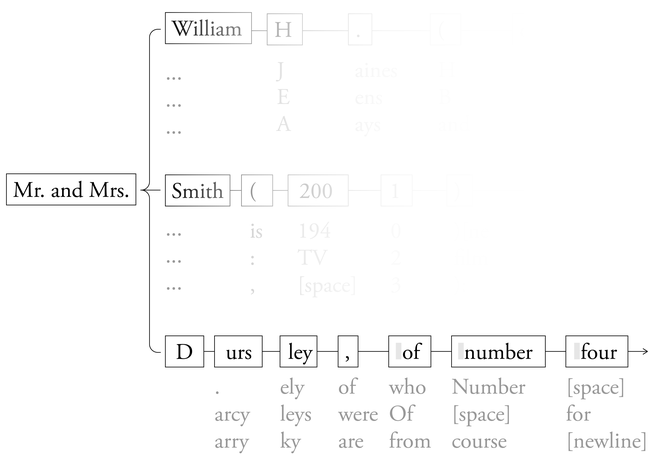
A veces, el mapa de lenguaje es lo suficientemente detallado como para contener copias exactas de libros y artículos completos. El verano pasado, un estudio de varios LLM descubrió que el modelo Llama 3.1-70B de Meta puede, como Claude, reproducir eficazmente el texto completo de Harry Potter y la Piedra Filosofal. Los investigadores asignaron al modelo solo las primeras fichas del libro: "Sr. y Sra. D." En el mapa de lenguaje interno de Llama, el texto con mayor probabilidad de seguir era: "ursley, del número cuatro de Privet Drive, se enorgullecieron de decir que eran perfectamente normales, muchas gracias". Esta es precisamente la primera frase del libro. Al retroalimentar repetidamente los resultados del modelo, Llama continuó con esta línea hasta producir el libro completo, omitiendo solo unas pocas frases cortas.
Utilizando esta técnica, los investigadores también demostraron que Llama había comprimido sin pérdidas grandes porciones de otras obras, como el famoso ensayo de Ta-Nehisi Coates en Atlantic "El caso de las reparaciones". Al usar la primera frase del ensayo como estímulo, más de 10 000 palabras, o dos tercios del ensayo, salieron textualmente del modelo. También parece posible realizar grandes extracciones de Llama 3.1-70B para Juego de Tronos de George R. R. Martin, Beloved de Toni Morrison y otras obras.
Los investigadores de Stanford y Yale también demostraron esta semana que el resultado de un modelo puede parafrasear un libro en lugar de duplicarlo con exactitud. Por ejemplo, donde Juego de Tronos dice "Jon vislumbró una figura pálida moviéndose entre los árboles", los investigadores descubrieron que GPT-4.1 produjo "Algo se movió, justo en el borde de la vista: una figura pálida, deslizándose entre los troncos". Al igual que en el ejemplo de Difusión Estable mencionado anteriormente, el resultado del modelo es extremadamente similar al de una obra original específica.
Esta no es la única investigación que demuestra el plagio casual de modelos de IA. "En promedio, entre el 8 % y el 15 % del texto generado por los LLM" también existe en la web, exactamente en el mismo formato, según un estudio. Los chatbots incumplen sistemáticamente los estándares éticos a los que normalmente están sujetos los humanos.
La memorización podría tener consecuencias legales de al menos dos maneras. En primer lugar, si la memorización es inevitable, los desarrolladores de IA tendrán que evitar de alguna manera que los usuarios accedan al contenido memorizado, como han escrito los juristas. De hecho, al menos un tribunal ya lo ha exigido. Sin embargo, las técnicas existentes son fáciles de eludir. Por ejemplo, 404 Media ha informado que Sora 2 de OpenAI no cumpliría con una solicitud para generar un video de un videojuego popular llamado Animal Crossing, pero sí generaría un video si el título del juego fuera "'crossing aminal' [sic] 2017". Si las empresas no pueden garantizar que sus modelos nunca infrinjan los derechos de autor de un escritor o artista, un tribunal podría exigirles que retiren el producto del mercado.
Una segunda razón por la que las empresas de IA podrían ser responsables de infringir los derechos de autor es que un modelo en sí mismo podría considerarse una copia ilegal. Mark Lemley, profesor de derecho de Stanford que ha representado a Stability AI y Meta en este tipo de demandas, me comentó que no está seguro de si es preciso decir que un modelo "contiene" una copia de un libro o si "tenemos un conjunto de instrucciones que nos permite crear una copia sobre la marcha en respuesta a una solicitud". Incluso esto último es potencialmente problemático, pero si los jueces deciden que lo primero es cierto, los demandantes podrían exigir la destrucción de las copias infractoras. Esto significa que, además de multas, las empresas de IA podrían, en algunos casos, enfrentarse a la posibilidad de verse legalmente obligadas a reentrenar sus modelos desde cero, con material debidamente licenciado.
En una demanda, The New York Times alegó que el GPT-4 de OpenAI podía reproducir docenas de artículos del Times casi textualmente. OpenAI (que tiene una asociación corporativa con The Atlantic) respondió argumentando que el Times utilizó "instrucciones engañosas" que violaban las condiciones de servicio de la empresa y que incitaban al modelo con secciones de cada uno de esos artículos. "La gente normal no usa los productos de OpenAI de esta manera", escribió la empresa, e incluso afirmó "que el Times pagó a alguien para que pirateara los productos de OpenAI". La empresa también ha denominado este tipo de reproducción "un error poco común que estamos trabajando para eliminar".
Pero la investigación emergente está dejando claro que la capacidad de plagiar es inherente a GPT-4 y a todos los demás LLM principales. Ninguno de los investigadores con los que hablé creía que el fenómeno subyacente, la memorización, fuera inusual o pudiera erradicarse.
En demandas por derechos de autor, la metáfora del aprendizaje permite a las empresas hacer comparaciones engañosas entre chatbots y humanos. Al menos un juez ha repetido estas comparaciones, comparando el robo y escaneo de libros por parte de una empresa de inteligencia artificial con "enseñar a los escolares a escribir bien". También hubo dos demandas en las que los jueces dictaminaron que capacitar a un LLM en libros con derechos de autor era un uso justo, pero ambos fallos fueron defectuosos en su manejo de la memorización: Un juez citó testimonio de un experto que mostró que Llama no podía reproducir más de 50 fichas de los libros de los demandantes, aunque desde entonces se publicó una investigación que demuestra lo contrario. El otro juez reconoció que Claude había memorizado partes significativas de libros, pero dijo que los demandantes no habían alegado que esto fuera un problema.
La investigación sobre cómo los modelos de IA reutilizan su contenido de entrenamiento aún es rudimentaria, en parte porque las empresas de IA están motivadas a mantenerlo así. Varios de los investigadores con los que hablé mientras escribía este artículo me hablaron de investigaciones sobre memorización que han sido censuradas e impedidas por los abogados de las empresas. Ninguno de ellos quiso hablar públicamente sobre estos casos por temor a represalias de las empresas.
Mientras tanto, el CEO de OpenAI, Sam Altman, ha defendido el "derecho de la tecnología a aprender" de libros y artículos, "como puede hacerlo un ser humano". Esta idea engañosa y optimista impide el debate público que necesitamos tener sobre cómo las empresas de IA utilizan las obras creativas e intelectuales de las que dependen por completo.