Incidentes Asociados

ChatGPT eliminó hoy casi 50.000 conversaciones compartidas del índice de Google tras nuestro artículo. Creían haber resuelto el problema. ¿Pero lo lograron?
Una nueva investigación de Digital Digging, aquí está la primera, realizada con el investigador belga Nicolas Deleur, [https://x.com/osint77760], ha descubierto 110.000 conversaciones de ChatGPT preservadas a través de Wayback Machine de Archive.org. Cuando los usuarios hacen clic en "compartir" en una conversación de ChatGPT, creen que están creando un enlace temporal para un amigo o compañero. Lo que no saben es que también están creando un registro permanente y consultable de sus pensamientos, confesiones y, en ocasiones, actividades ilegales, vistas por Archive.org.
Le pedí al director de Wayback Machine, Mark Graham (https://www.linkedin.com/in/markjohngraham/), que comentara. Graham: «Puedo decirles que no hemos recibido ni atendido ninguna solicitud de exclusión (a gran escala) de URLs de "chatgpt.com/share". Si OpenAI, titular de los derechos del material del dominio [chatgpt.com] (http://chatgpt.com/), solicitara la exclusión de URLs del patrón [chatgpt.com] (http://chatgpt.com/), probablemente atenderíamos esa solicitud. Sin embargo, no la han solicitado».
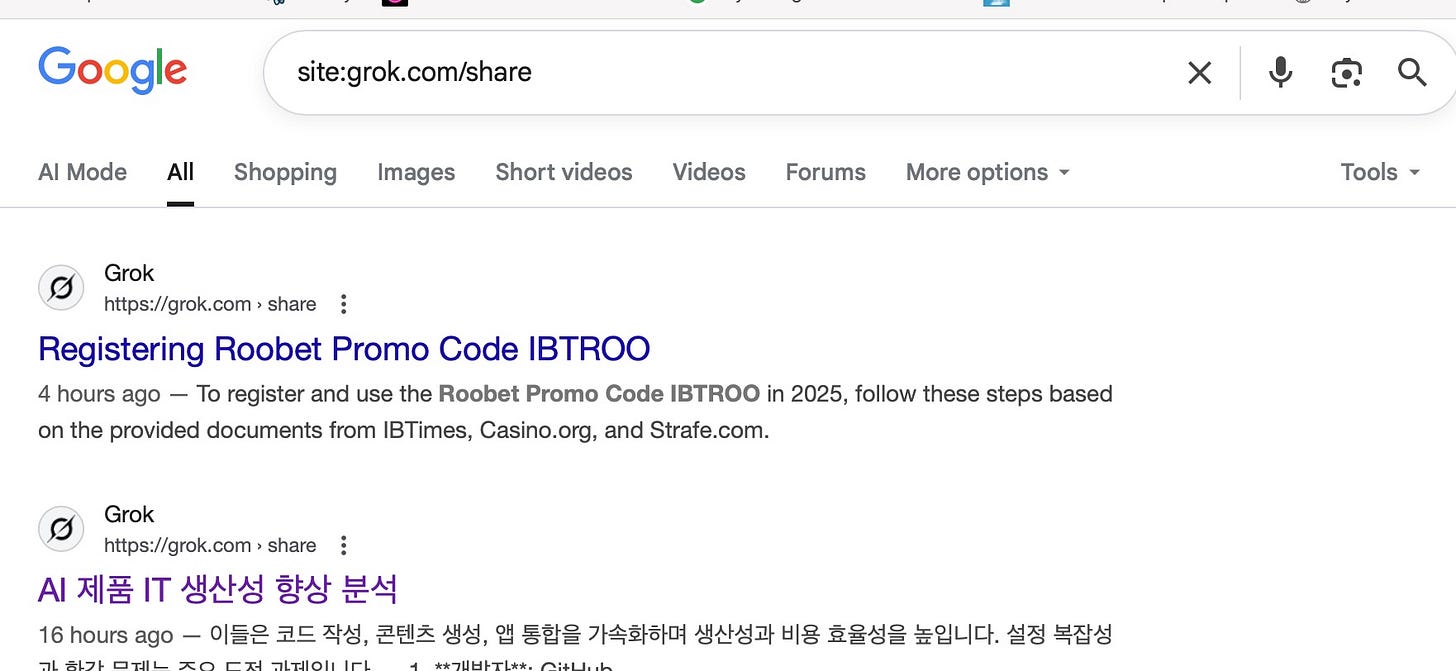
En este momento, los chats de Grok siguen visibles en Google a través de site:grok.com/share, pero se eliminan rápidamente.
Mientras OpenAI se apresuraba a desindexar las conversaciones de Google hoy, olvidaron la regla más básica de internet: nada desaparece del todo.
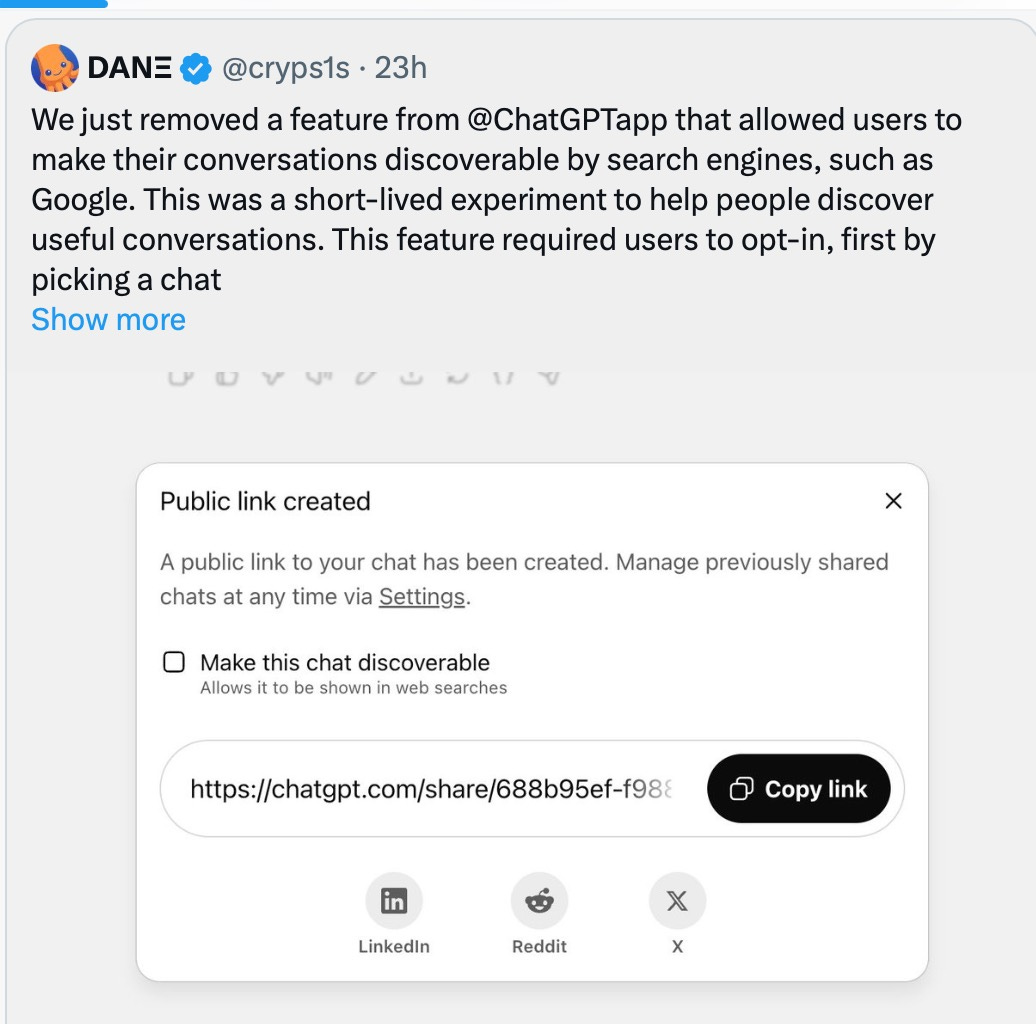
Más de 100 000 chats de ChatGPT aún se encuentran en Archive.org, aunque con una peculiaridad. Los chats no son solo enlaces ni fragmentos. Son conversaciones completas, congeladas en el tiempo, que contienen "confesiones" similares a las que expusimos ayer. Los usuarios compartieron estos chats públicamente, no por defecto, sino solo haciendo clic en "Compartir".
Entre las conversaciones recién descubiertas, surgen patrones derivados de nuestros hallazgos originales. La mayoría de los chats compartidos son inofensivos, pero algunos no lo son. Aquí hay tres ejemplos de la base de datos archive.org (véase la nota a continuación sobre por qué no mencionamos nombres):
La estrategia de apropiación de tierras en la Amazonía
En una conversación particularmente incriminatoria, un abogado italoparlante de una corporación energética multinacional expuso su estrategia para desplazar a las comunidades indígenas amazónicas. El usuario se presentó diciendo: "Soy el abogado de un grupo multinacional activo en el sector energético que pretende desplazar a una pequeña comunidad indígena amazónica de sus territorios para construir una presa y una central hidroeléctrica".
La conversación reveló planes para una central hidroeléctrica de 15.000 MW, y el abogado preguntó explícitamente: "¿Cómo podemos obtener el precio más bajo posible en las negociaciones con estos indígenas?". Reconocieron que los pueblos indígenas "desconocen el valor monetario de la tierra y no tienen idea de cómo funciona el mercado", admitiendo así su intención de explotar esta brecha de conocimiento para beneficio corporativo.
Disidencia Política en Regímenes Autoritarios
Otra conversación mostró a alguien en un país de habla árabe que le pidió a ChatGPT que escribiera un artículo sobre cómo su presidente "قام السيسي ب نكح الشعب المصري" (aproximadamente: "perjudicó al pueblo egipcio"). ChatGPT, amablemente, elaboró una crítica política detallada que describía la represión gubernamental de las voces de la oposición, los arrestos masivos, el deterioro económico y el uso de la fuerza militar para mantener el poder; todo ello archivado permanentemente en una conversación que podía rastrearse hasta su creador gracias a la información contextual.
Documentación sobre fraude académico
Una conversación en persa trata sobre un investigador que documenta su mala conducta académica en tiempo real. Estaban escribiendo un artículo sobre "بررسی تاثیر فضای مجازی بر سبک زندگی نوجوانان شهرستان رباط کریم" (el impacto del espacio virtual en el estilo de vida de los adolescentes en la ciudad de Robat Karim).
El usuario hizo que ChatGPT escribiera su resumen, revisión de la literatura, analizara sus datos de SPSS y redactara sus secciones de discusión y conclusión. Cuando ChatGPT sugirió fuertemente que el ensayo necesita "más referencias académicas" para cumplir con los estándares de la maestría, el usuario respondió: "دیگه لازم نیست چیزی برای مقاله بنویسی. دمت گرم! برای استادم مقاله رو فرستادم و نمره بهم داد" (No es necesario escribir nada más para el artículo. ¡Gracias! Le envié el artículo a mi profesor y obtuve mi calificación). Encontramos alrededor de 100 conversaciones de estudiantes perezosos.

Alguien me envió esta captura de pantalla de periódicos que realmente leen Digital Digging. ¡Gracias!
La conversación terminó con el usuario comentando alegremente: "یه استاد دیگه، یه مقاله خواسته :)" (Otro profesor quiere un artículo :)), lo que sugiere que este no fue su primer ni último intento de fraude académico asistido por IA.
Esto es lo que OpenAI pasó por alto en su intento de limpieza:
-
Las URL originales pueden estar inactivas, pero los enlaces de Archive.org sí.
-
Google ya no puede verlos, pero cualquiera que conozca el enlace, gracias a archive.org, aún puede.
Notificamos a ChatGPT, pero no respondieron.
Nota: Al igual que en nuestra investigación original, hemos decidido no proporcionar URL específicas de Archive.org ni instrucciones detalladas para acceder a estas conversaciones. Si bien la información es técnicamente pública, no vemos ningún beneficio en facilitar su explotación.
El análisis técnico completo de Nicolas Delier solo puede ser descargado por miembros para evitar su uso indebido:
Los más de 100.000 chats que encontramos en el archivo: