Incidentes Asociados

Hace tres días, Drew DeVault, fundador y director ejecutivo de SourceHut, publicó una entrada de blog titulada "Por favor, dejen de externalizar sus costos directamente en mi cara", donde se quejaba de que las empresas de LLM estaban rastreando datos sin respetar el archivo robosts.txt, lo que causaba graves interrupciones en SourceHut.

Pensé: "¡Interesante!", y seguí adelante.
Entonces, ayer por la mañana, la infraestructura de GitLab de KDE se vio saturada por otro rastreador de IA, con IP de un rango de Alibaba; esto provocó que GitLab quedara temporalmente inaccesible para los desarrolladores de KDE.
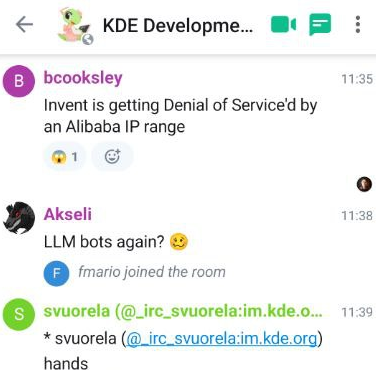
Descubrí que, hace una semana, una chica de anime empezó a aparecer en la instancia de GitLab de GNOME mientras se cargaba la página. Resulta que es la página de carga predeterminada de Anubis, un retador de prueba de trabajo que bloquea los scrapers de IA que causan interrupciones.
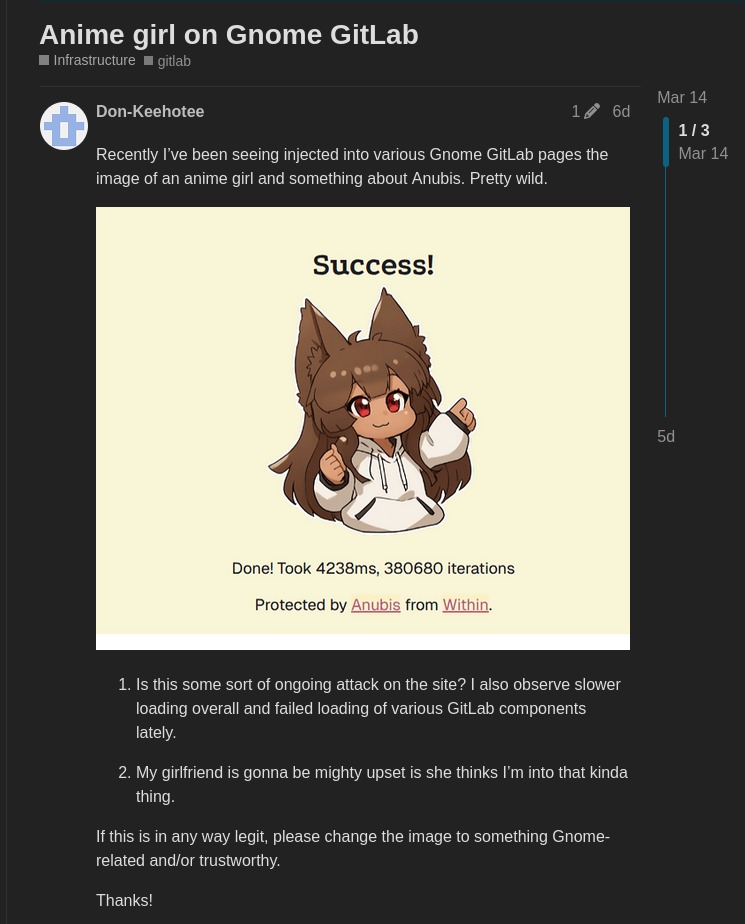
A estas alturas, debería estar bastante claro que esto no es casualidad. Los rastreadores de IA se están volviendo cada vez más agresivos y, dado que el software libre y de código abierto (FOSS) depende de la colaboración pública, mientras que las empresas privadas no tienen ese requisito, esto supone una carga adicional para las comunidades de código abierto.
Así que intentemos obtener más detalles, volviendo a la entrada del blog de Drew. Según Drew, los rastreadores LLM no respetan los requisitos de robots.txt e incluyen endpoints costosos como GitBul, cada página de cada registro de Git y cada confirmación de su repositorio. Lo hacen utilizando agentes de usuario aleatorios de decenas de miles de direcciones IP, cada uno con solo una solicitud HTTP, intentando integrarse con el tráfico de usuarios.

Debido a esto, es difícil implementar un buen conjunto de medidas de mitigación. Drew afirma que varias tareas de alta prioridad se han retrasado durante semanas o meses debido a estas interrupciones, que los usuarios se han visto afectados ocasionalmente (ya que es difícil distinguir entre bots y humanos) y, por supuesto, esto provoca interrupciones ocasionales de SourceHut.

Drew no distingue aquí entre las empresas de IA que respetan más o menos los archivos robots.txt, o que son más precisas en sus informes de agentes de usuario; podremos profundizar en ello más adelante.
Finalmente, Drew señala que no se trata de un problema aislado. Dice:
Todos mis amigos administradores de sistemas se enfrentan a los mismos problemas, [y] cada vez que me siento a tomar unas cervezas o a cenar con ellos, enseguida nos quejamos de los bots. [...] La desesperación en estas conversaciones es palpable.

Esto me lleva de nuevo a los problemas de ayer con KDE GitLab. Según Ben, miembro del equipo de administración de sistemas de KDE, todas las IP que realizaban este ataque DDoS afirmaban ser de MS Edge y se debían a empresas chinas de inteligencia artificial. Menciona que operadores occidentales de LLM, como OpenAI y Anthropic, al menos configuraban un agente de usuario (UA) adecuado. Hablaremos más sobre esto más adelante.
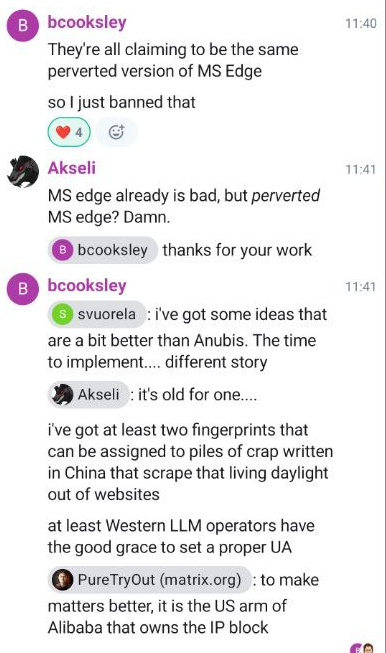
La solución, por ahora, fue prohibir la versión de Edge que los bots decían ser, aunque es difícil creer que esta sea una solución definitiva; estos bots parecen estar interesados en cambiar los agentes de usuario para integrarse lo mejor posible.
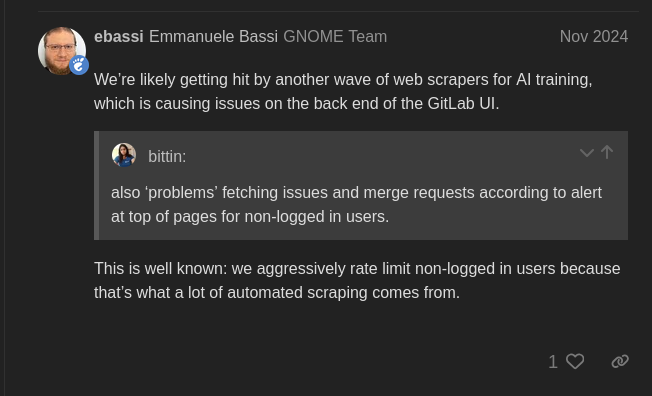
De hecho, GNOME ha estado experimentando problemas desde noviembre pasado; como solución temporal, habían limitado la capacidad de los usuarios sin sesión para ver las solicitudes de fusión y las confirmaciones, lo que obviamente también causó problemas a los usuarios reales.
La solución que finalmente se optó fue cambiar a Anubis. Esta página presenta un desafío para el navegador, que luego debe dedicar tiempo a realizar cálculos y presentar la solución al servidor. Si es correcta, se accede al sitio web.
Según el desarrollador, este proyecto es "una especie de respuesta nuclear, pero los bots de IA que raspan datos tan agresivamente me han obligado a actuar. Detesto tener que hacer esto, pero esto es lo que nos pasa en el Internet moderno porque los bots no se ajustan a estándares como robots.txt, incluso cuando dicen hacerlo".
Sin embargo, esto también está causando problemas a los usuarios. Cuando muchas personas abren el enlace desde el mismo sitio, puede ocurrir que se les muestre un ejercicio de mayor dificultad que tarde un poco en completarse. Un usuario informa de un retraso de un minuto, y otro, desde su teléfono, tiene que esperar unos dos minutos.
¿Por qué? ¡Pues se pegó un enlace de GitLab en una sala de chat! De igual manera, ocurrió lo mismo cuando la solicitud de fusión de Triple Buffering de GNOME se publicó en Hacker News, lo que generó mucha atención allí. Como dijo el desarrollador, es una opción nuclear para los rastreadores, pero también tiene consecuencias humanas.
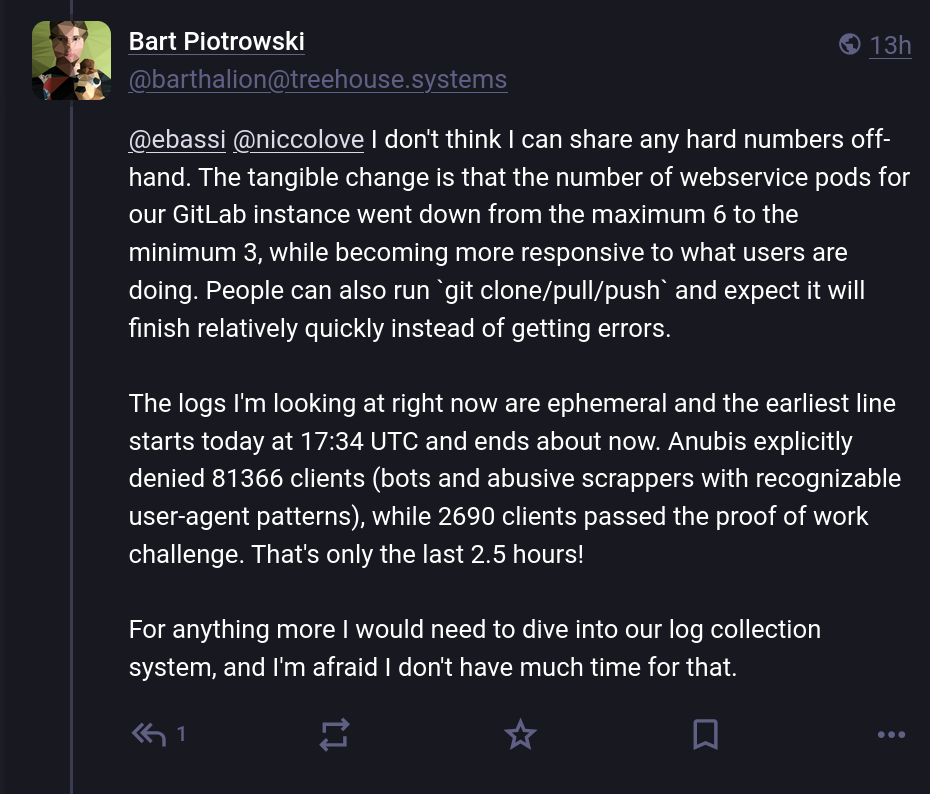
A través de Mastodon, un administrador de sistemas de GNOME, Bart Piotrowski, tuvo la amabilidad de compartir algunas cifras para que la gente comprendiera plenamente la magnitud del problema. Según él, en aproximadamente dos horas y media recibieron un total de 81.000 solicitudes, y de ellas, solo el 3% superó la prueba de trabajo de Anubi, lo que indica que el 97% del tráfico provenía de bots: ¡una cifra desorbitada!
Dicho esto, al menos eso funcionó. Otras organizaciones tienen más dificultades para lidiar con estos scrapers.
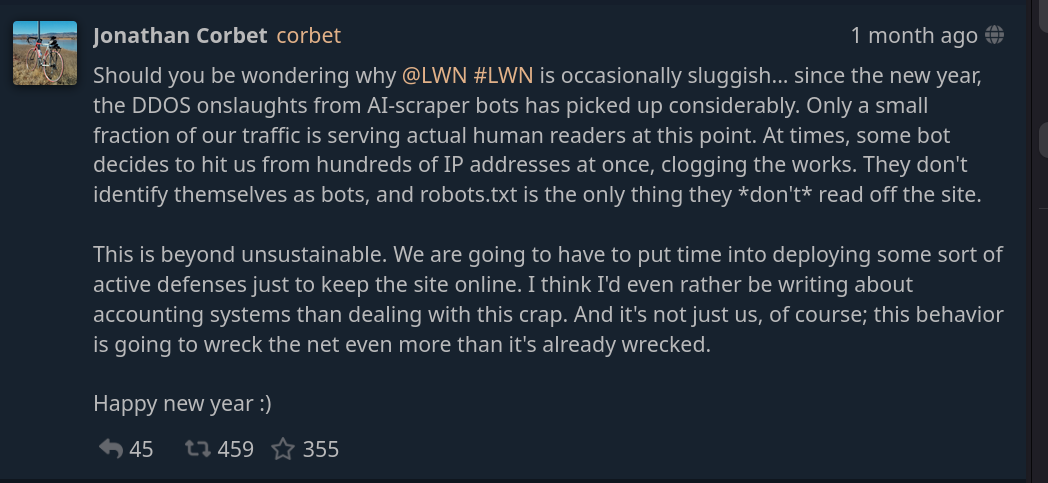
Por ejemplo, Jonathan Corbet, director de la fuente de noticias FOSS LWN, advierte a los usuarios que el sitio web podría estar "ocasionalmente lento"... debido a ataques DDoS de bots scrapers con IA. Afirma que «solo una pequeña fracción de nuestro tráfico llega a lectores humanos reales» y, en algún momento, los bots «deciden atacarnos desde cientos de direcciones IP a la vez. [...] No se identifican como bots, y el archivo robots.txt es lo único que no leen del sitio».
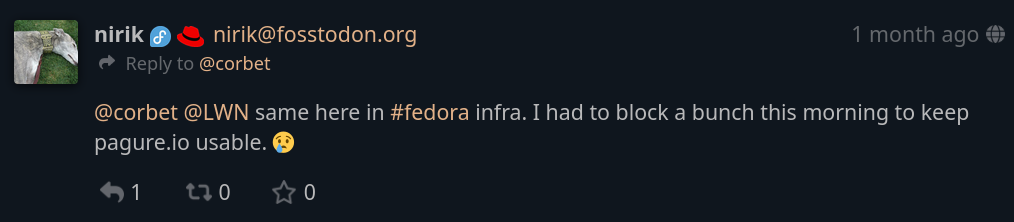
Muchos expresaron su solidaridad, incluido Kevin Fenzi, administrador de sistemas del proyecto Fedora. También han tenido problemas con los scrapers de IA: primero, hace un mes tuvieron que luchar para que pagure.io siguiera funcionando:
Sin embargo, la situación empeoró con el tiempo, por lo que tuvieron que bloquear varias subredes, lo que también afectó a muchos usuarios reales. Desesperado, Kevin decidió banear todo Brasil para que todo volviera a funcionar; según tengo entendido, esta prohibición sigue vigente y no está claro si se podría encontrar una solución a largo plazo.

Y, como señala Neal Gompa, incluso bloquear un país entero solo sirve hasta cierto punto, y al parecer, la infraestructura de Fedora ha estado "caída regularmente durante semanas" debido a los scrapers de IA.
Otro proyecto afectado por este problema en la última semana es Inkscape. Según Martin Owens, no se trata del típico ataque DDoS chino del año pasado, sino de un grupo de empresas que empezaron a ignorar nuestra configuración de araña y a falsificar la información de sus navegadores. Ahora tengo una lista de bloqueo de Prodigius. Si trabajas para una gran empresa dedicada a la inteligencia artificial, puede que ya no veas nuestro sitio web.
Y, bueno, Martin no es el único desarrollador que ha creado una "lista de bloqueo prodigiosa". Incluso BigGrizzly, de Frama Software, se vio inundado por un rastreador LLM malicioso y creó una lista de 460.000 direcciones IP con agentes de usuario falsificados para bloquear; se ofrece a compartir la lista.
Otro intento exhaustivo es el proyecto "ai.robots.txt", una lista abierta de rastreadores web asociados con empresas de IA. Ofrecen un archivo robots.txt que implementa el Protocolo de Exclusión de Robots y un archivo .htaccess que devolverá una página de error al recibir una solicitud de cualquier rastreador de IA de su lista.
Podemos obtener más datos sobre los rastreadores si nos remontamos unos meses atrás. Aquí hay una publicación de Dennis Schubert sobre la infraestructura de Diaspora (una red social descentralizada de código abierto), donde dice que "ver los registros de tráfico lo enfureció muchísimo".
En la entrada del blog, afirma que una cuarta parte de todo su tráfico web proviene de bots con un agente de usuario OpenAI, el 15 % de Amazon, el 4,3 % de Anthropic, etc. En total, el 70 % de las solicitudes provienen de empresas de IA.

Según él,
no rastrean una página una sola vez y luego pasan a otra. Ah, no, vuelven cada 6 horas porque, jaja, ¿por qué no? Tampoco les importa un comino el
robots.txt, porque ¿por qué debería importarles? [...] Si intentas limitar su velocidad, simplemente cambiarán a otras IP constantemente. Si intentas bloquearlos por una cadena de agente de usuario, simplemente cambiarán a una cadena de agente de usuario que no sea bot (no, en serio). Esto es literalmente un DDoS en todo internet.

El proyecto Read the Docs ofrece una cifra similar. En una entrada de blog titulada "Los rastreadores de IA deben ser más respetuosos", afirman que bloquear todos los rastreadores de IA redujo inmediatamente su tráfico en un 75 %, pasando de 800 GB/día a 200 GB/día. Esto supuso un ahorro de unos 1500 $ al mes para el proyecto.

El resto del artículo también es bastante impresionante; hablan de rastreadores que descargan decenas de terabytes de datos en cuestión de días, o incluso más. Es difícil bloquearlos por completo, ya que usan varias IP diferentes.

Me pregunto cuánto de esto se debe al scraping de datos de entrenamiento y cuánto a la función de "búsqueda" que ofrecen la mayoría de los LLM. Sin embargo, según Schubert, los rastreadores "normales" como los de Google y Bing solo suman una fracción de un punto porcentual, lo que indica que otras empresas están abusando de sus capacidades web.
Pero no se trata solo de scrapers; de lo contrario, lo habría titulado "scrapers de IA", no "empresas de IA". Otro problema con el que la comunidad de código abierto ha estado lidiando son los informes de errores generados por IA, por ejemplo.
Esto fue reportado por primera vez por Daniel Stenberg, del proyecto Curl, en una entrada de blog titulada "La I en LLM significa Inteligencia". Curl ofrece un proyecto de recompensas por errores, pero últimamente han notado que muchos informes de errores son generados por IA. Estos parecen creíbles y requieren mucho tiempo de desarrollo para su revisión, pero también contienen las típicas alucinaciones esperadas de las IA.
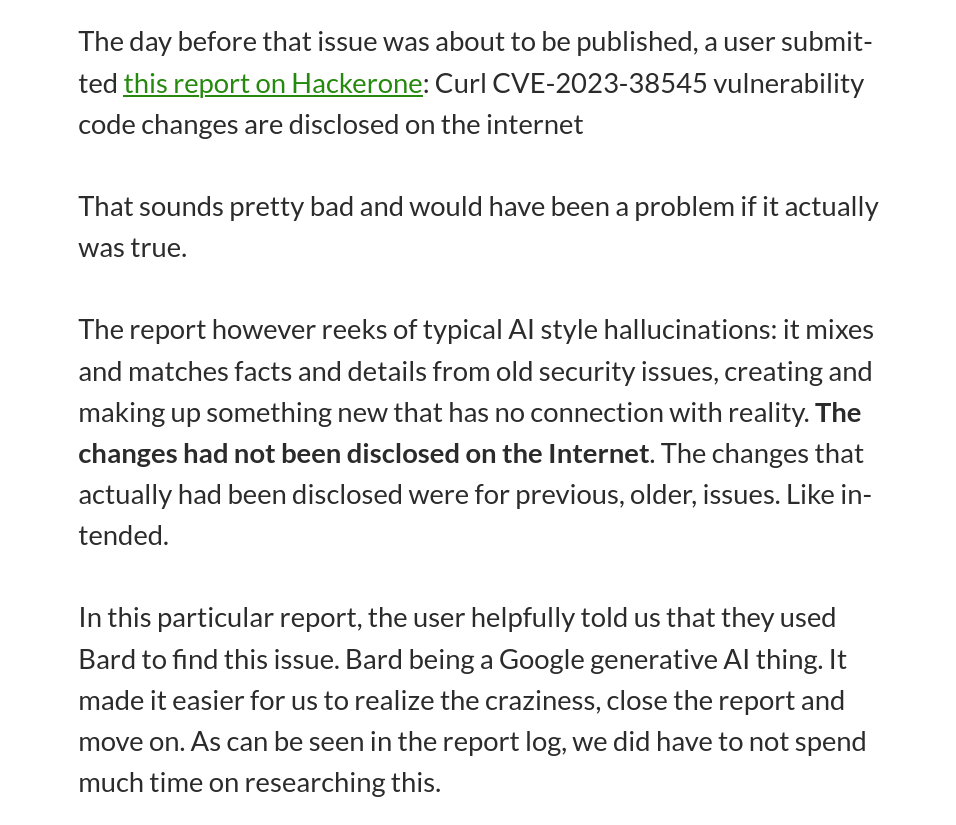
Es una locura tener que revisar tu propio código porque un informe de error te dice con seguridad que hay un problema de seguridad crítico que solucionar, y... no encontrarlo, porque todo el problema es solo una alucinación de la IA.

Seth Larson, miembro del equipo de triaje de informes de seguridad para CPython, pip, urllib3, Requests y otros, reportó un problema similar. Comenta:
Recientemente he notado un aumento en los informes de seguridad de muy baja calidad, spam y con apariencias de LLM para proyectos de código abierto. El problema radica en que, en la era de los LLM, estos informes parecen, a primera vista, potencialmente legítimos y, por lo tanto, requieren tiempo para refutarlos.

Este es un problema bastante grave. Como señala, responder a los informes de seguridad es costoso, y responder a informes de errores inventados pero creíbles supone una carga adicional considerable para los mantenedores, lo que podría obligarlos a abandonar el mundo del código abierto.

El artículo finaliza con una solicitud: por favor, no utilicen sistemas de IA o LLM para detectar vulnerabilidades. Afirma: «Estos sistemas actuales no pueden comprender el código; detectar vulnerabilidades de seguridad requiere comprender el código y comprender conceptos a nivel humano como la intención, el uso común y el contexto».

De nuevo, quiero señalar que estos problemas afectan de forma desproporcionada al mundo del software libre y de código abierto (FOSS). Los proyectos de código abierto no solo suelen disponer de menos recursos en comparación con los productos comerciales, sino que, al ser proyectos impulsados por la comunidad, gran parte de su infraestructura es pública y, por lo tanto, susceptible tanto a rastreadores como a informes de errores o problemas generados por IA.