Incidentes Asociados
Los avances recientes en la tecnología de generación de lenguaje natural (NLG) han mejorado significativamente la diversidad, el control y la calidad de los textos generados por LLM. Un ejemplo notable es ChatGPT de OpenAI, que demuestra un rendimiento excepcional en tareas como responder preguntas, redactar correos electrónicos, ensayos y códigos. Sin embargo, esta capacidad recién descubierta para producir textos similares a los humanos con alta eficiencia también plantea preocupaciones sobre la detección y prevención del uso indebido de LLM en tareas como el phishing, la desinformación y la deshonestidad académica.
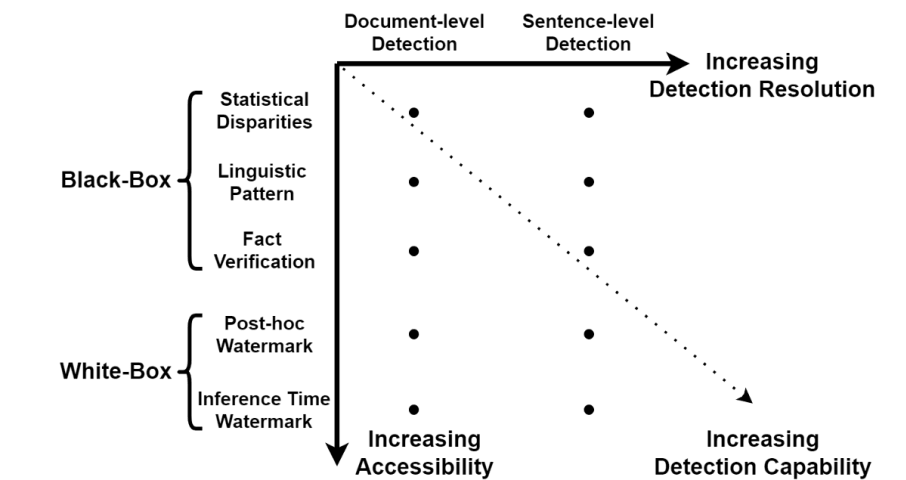
Los métodos de detección existentes se pueden agrupar aproximadamente en dos categorías: detección de recuadro negro y detección de recuadro blanco; los métodos de detección de recuadro negro se limitan al acceso de nivel API a los LLM. Se basan en la recopilación de muestras de texto de fuentes humanas y mecánicas, respectivamente, para entrenar un modelo de clasificación que se puede usar para discriminar entre textos LLM y generados por humanos. Una alternativa es la detección de caja blanca, en este escenario, el detector tiene acceso total a los LLM y puede controlar el comportamiento de generación del modelo con fines de trazabilidad. En la práctica, los detectores de caja negra suelen ser construidos por entidades externas, mientras que la detección de caja blanca generalmente la llevan a cabo los desarrolladores de LLM.
Detección de caja negra
Para construir un detector eficaz, los métodos de caja negra requieren la recopilación de muestras de texto de fuentes generadas tanto por humanos como por máquinas. Posteriormente, se entrena un clasificador para diferenciar entre las dos categorías en función de las características elegidas.
Algunas características de detección de uso común incluyen disparidades estadísticas y patrones lingüísticos. Por ejemplo, GLTR [1] se ha desarrollado para detectar artefactos de generación a través de métodos de muestreo comunes, como se muestra en la Figura. 2. La perplejidad es otra métrica de uso común para la detección de texto generado por LLM. Mide la calidad del modelo lingüístico cuantificando el log-verosimilitud promedio negativo de los textos bajo el LLM. Los estudios han demostrado que los modelos de lenguaje tienden a concentrarse en patrones comunes en los textos en los que fueron entrenados, lo que resulta en puntajes bajos de perplejidad para el texto generado por LLM. Por el contrario, los autores humanos tienen la capacidad de expresarse en una amplia gama de estilos, lo que resulta en valores más altos de perplejidad.
Detección de caja blanca
En la detección de caja blanca, el detector tiene acceso completo al modelo de idioma de destino, lo que permite la incrustación de marcas de agua secretas en sus salidas para monitorear cualquier actividad sospechosa o no autorizada. Un ejemplo representativo de este método se puede encontrar en la investigación realizada por Kirchenbauer et al. [2]. Durante la próxima generación de tokens, se genera un código hash basado en el token generado anteriormente, que luego se usa para generar un generador de números aleatorios. Esta semilla divide aleatoriamente todo el vocabulario en una "lista verde" y una "lista roja" de igual tamaño. El siguiente token se genera posteriormente a partir de la lista verde. De esta manera, la marca de agua se incrusta en cada palabra generada, como se muestra en la Figura. 3. Para detectar la marca de agua, un tercero con conocimiento de la función hash y generador de números aleatorios puede reproducir la lista roja para cada token y contar el número de violaciones de la regla de la lista roja, verificando así la autenticidad del texto. La probabilidad de que una fuente natural produzca N tokens sin violar la regla de la lista roja es solo (1/2)^N, que es extremadamente pequeña incluso para fragmentos de texto con unas pocas docenas de palabras. Para eliminar la marca de agua, los adversarios deben modificar al menos la mitad de los tokens del documento.
Preocupaciones de los autores:
(1) La recopilación de datos juega un papel vital en el desarrollo de detectores de caja negra, ya que estos sistemas se basan en los datos con los que están capacitados para aprender a identificar las señales de detección. Sin embargo, es importante tener en cuenta que el proceso de recopilación de datos puede introducir sesgos que pueden afectar negativamente el rendimiento y la generalización del detector. Estos sesgos pueden tomar varias formas. Por ejemplo, muchos estudios existentes tienden a centrarse solo en una o unas pocas tareas específicas, como la respuesta a preguntas o la generación de noticias, lo que puede conducir a una distribución desequilibrada de los temas en los datos. Además, los artefactos humanos pueden introducirse fácilmente durante la recopilación de datos, como se ve en el estudio realizado por Guo et al. [3], donde la falta de instrucciones de estilo llevó a ChatGPT de OpenAI a generar respuestas con un sentimiento neutral. Estas correlaciones espurias pueden ser capturadas e incluso amplificadas por el detector, lo que conduce a un rendimiento de generalización deficiente cuando se implementa en aplicaciones del mundo real.
(2) Los métodos de detección actuales se basan en la suposición de que el LLM está controlado por los desarrolladores y se ofrece como un servicio a los usuarios finales, esta relación de uno a muchos es propicia para los propósitos de detección. Sin embargo, la posibilidad de que los desarrolladores abran sus modelos o que los hackers roben los modelos plantea un desafío para estos enfoques de detección. Una vez que el usuario final obtiene acceso completo al LLM, la capacidad de modificar el comportamiento de los LLM impide que la detección de caja negra identifique patrones de lenguaje generalizados. Incrustar una marca de agua en el LLM de código abierto es una solución potencial. Sin embargo, todavía se puede derrotar ya que los usuarios tienen acceso completo al modelo y pueden ajustarlo o cambiar las estrategias de muestreo para borrar la marca de agua. Actualmente. el costo y el esfuerzo involucrados en la capacitación de LLM hacen que sea poco probable que los desarrolladores lancen sus LLM más poderosos. No obstante, la detección de textos generados por LLM a partir de LLM de código abierto sigue siendo un problema crítico que debe abordarse en el futuro.
Conclusión
Si bien la detección de caja negra funciona en la actualidad debido a las señales detectables que dejan los modelos de lenguaje en el texto generado, gradualmente se volverá menos viable a medida que avancen las capacidades del modelo de lenguaje y, en última instancia, se vuelva inviable. A la luz de la rápida mejora en la calidad del texto generado por LLM, el futuro de las herramientas de detección confiables se encuentra en los enfoques de detección de marcas de agua de caja blanca.
Referencias
[1] Gehrmann, Sebastian, Hendrik Strobelt y Alexander M. Rush. “GLTR: Detección Estadística y Visualización de Texto Generado.” Actas de la 57.ª Reunión Anual de la Asociación de Lingüística Computacional: Demostraciones del Sistema. 2019.
[2] Kirchenbauer, John, et al. "Una marca de agua para modelos de lenguaje grande". preimpresión de arXiv arXiv:2301.10226 (2023).
[3] Guo, Biyang, et al. “¿Qué tan cerca está ChatGPT de los expertos humanos? Corpus de comparación, evaluación y detección”. preimpresión de arXiv arXiv:2301.07597 (2023).