Indexación de riesgos de IA con incidentes, problemas y variantes
Dos años después de lanzar públicamente la base de datos de incidentes de IA (AIID) como una colección de daños o cuasi daños producidos por IA en el mundo, una acumulación de "problemas" que no cumplen con sus criterios de ingestión de incidentes acumulados en su cola de revisión. Para entender por qué, echemos un vistazo a la breve definición de Incidente.
Definición de "incidente": Un presunto daño o casi daño en el que está involucrado un sistema de IA.
Esta definición es "evento", lo que significa que un riesgo debe materializarse en forma de daño. Pero, ¿qué pasa con los informes de riesgos que no necesariamente se han realizado (todavía)? En seguridad informática, los riesgos son "vulnerabilidades", mientras que un incidente de seguridad es una "exposición". Algunos análogos de IA incluyen:

| "China desarrolla un 'fiscal' de IA para presentar cargos 'con un 97 % de precisión'" No es un incidente: el daño inevitable aún no ha ocurrido. |
| "IA y deepfakes presentan nuevos riesgos para las relaciones en Internet" No es un incidente: nos falta un ejemplo específico. |

|

| "Las ligeras modificaciones de los letreros de las calles pueden engañar por completo a los algoritmos de aprendizaje automático" No es un incidente: la vulnerabilidad aún no se ha explotado. |
La comunidad de impactos de IA puede aprender, responder y evitar que muchos de estos problemas se conviertan en incidentes, pero requieren una definición formal y un criterio riguroso. Por lo tanto, introducimos "problemas" definidos como:
Definición de "Problema": Un presunto daño por parte de un sistema de IA que aún no se ha producido o detectado.
Recientemente pusimos a disposición "informes de problemas" en la base de datos de incidentes de AI. Ahora puede buscar en la creciente lista de problemas, que también están traducidos automáticamente al español y inglés. También puede buscar simultáneamente en incidentes y problemas para explorar riesgos emergentes y reales en el mundo.
Estas definiciones y su aplicación dentro de la base de datos de incidentes de IA están sujetas a una gran y creciente colección de reglas de edición[a] que adjudican decisiones difíciles. En la mayoría de los casos, la decisión de si algo es o no un incidente o problema depende de si alguien alega que cumple con los criterios más restrictivos. Nuestra intención al proponer estas definiciones es proporcionar un foro y una infraestructura para resolver estas cuestiones fundamentales.

| Entre los foros más importantes para resolver estas preguntas se encuentra el OECD.ai Working Group on Classification and Risk, a través del cual la Colaboración Responsable de IA (la Colaboración) proporciona información sobre definiciones intergubernamentales emergentes para un marco de riesgo de IA de dos niveles similar al que se explora aquí. |
La adopción de definiciones compartidas para los riesgos de la IA es importante y oportuna.
Habiendo más que duplicado la cantidad de incidentes de IA indexados este año, estamos comenzando a ver un aumento en el ritmo de informes de incidentes. Con la llegada de la implementación de modelos generativos en el mundo real, esperamos que esta curva pronto se vuelva vertical. Planeamos abordar el ritmo acelerado de los incidentes mediante la introducción del concepto de "variante" en la base de datos de incidentes de IA. |
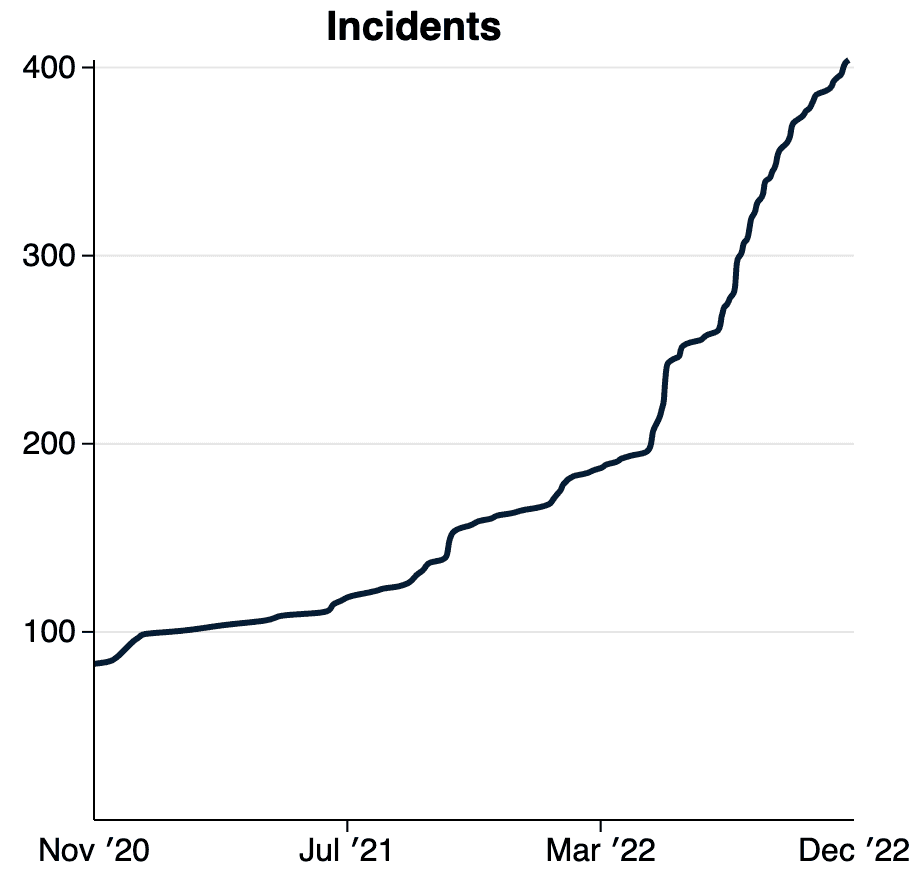
|
Definición de "variante": un incidente que comparte los mismos factores causales, produce daños similares e involucra los mismos sistemas inteligentes que un incidente de IA conocido.
Una de las razones para introducir "variantes" en la base de datos de incidentes es reunir grandes conjuntos de datos de ejemplos en los que las entradas han producido daños. La mayoría de los sistemas de IA producen y actúan sobre datos, por lo que recopilar las circunstancias en las que los sistemas de IA funcionan mal es de suma importancia para garantizar que no vuelva a ocurrir. Los conjuntos de datos de impacto pueden llegar a definir las pruebas de seguridad en toda la industria, moviéndose así más allá de los procesos cualitativos hacia implementaciones de sistemas aseguradas cuantificablemente. Pronto comenzaremos a indexar texto generativo incorrecto antes de pasar a otros tipos de sistemas.
Finalmente, notamos nuestra posición privilegiada en el espacio del impacto social de la IA y deseamos señalar que el artículo de investigación publicado en el [Taller de NeurIPS sobre IA centrada en el ser humano](https://hcai-at-neurips.github.io/ site/ ) también detalla un identificador de incidente planificado para un mundo donde existen múltiples bases de datos de incidentes interrelacionados. Ninguna base de datos única puede indexar todos los incidentes y problemas de IA en el mundo, pero necesitamos desesperadamente asegurarnos de que todos los datos de incidentes se compartan. La base de datos de incidentes de IA código base se está moviendo para admitir la federación (es decir, el intercambio) de datos entre múltiples países, reguladores, idiomas y empresas. Comuníquese con (/contact) si desea obtener más información sobre los planes de la federación.
Leer el artículo de investigación(Se expande en varios elementos) | |
|---|---|
McGregor, S., Paeth, K. y Lam, K. (2022). Indexación de riesgos de IA con incidentes, problemas y variantes. En Actas del Taller de NeurIPS sobre IA centrada en humanos (NeurIPS-22). Conferencia Virtual. | |
Resumen: A pesar de no pasar los criterios actuales de la base de datos para incidentes, estos problemas mejoran la comprensión humana de dónde la IA presenta el potencial de daño. De manera similar a las bases de datos en aviación y seguridad informática, AIID propone adoptar un sistema de dos niveles para indexar incidentes de IA (es decir, un evento de daño o casi daño) y problemas (es decir, un evento de riesgo de daño). Además, dado que algunos sistemas basados en aprendizaje automático a veces producen una gran cantidad de incidentes, se introduce la noción de "variante" de incidente. Estos cambios propuestos marcan la transición del AIID a una nueva versión en respuesta a las lecciones aprendidas de la edición de más de 2000 informes de incidentes e informes adicionales que se incluyen en la nueva categoría de "problema". (Leer más) |

|
Agradecimientos: Kate Perkins brindó valiosos comentarios sobre el contenido del documento además de sus funciones como editora de incidentes de AIID. Las definiciones y discusiones presentadas en el documento también están muy influenciadas por los esfuerzos en curso de la Organización para la Cooperación y el Desarrollo Económicos (OCDE) para adoptar una definición compartida de incidente de IA en los 38 estados miembros. Finalmente, AIID es un esfuerzo de muchas personas y organizaciones organizadas bajo el lema de Responsible AI Collaborative, incluido el Center for Security and Emerging Technology (CSET), cuyo Zachary Arnold contribuyó a la definición y los criterios del primer incidente. Varias personas han contribuido a la implementación de las características de la base de datos, incluidos César Varela, Pablo Costa, Clara Youdale y Luna McNulty. Es a través de los esfuerzos colectivos de Collab que las perspectivas ontológicas presentadas anteriormente tienen significado e importancia en el mundo real.